Latest News
- Spark 2.2.3 released (Jan 11, 2019)
- Spark+AI Summit (April 23-25th, 2019, San Francisco) agenda posted (Dec 19, 2018)
- Spark 2.4.0 released (Nov 02, 2018)
- Spark 2.3.2 released (Sep 24, 2018)

Ease of Use
Build applications through high-level operators.
Spark Streaming brings Apache Spark's language-integrated API to stream processing, letting you write streaming jobs the same way you write batch jobs. It supports Java, Scala and Python.
.filter(_.getText.contains("Spark"))
.countByWindow(Seconds(5))
Fault Tolerance
Stateful exactly-once semantics out of the box.
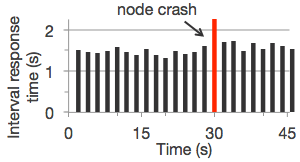
Spark Streaming recovers both lost work and operator state (e.g. sliding windows) out of the box, without any extra code on your part.
Spark Integration
Combine streaming with batch and interactive queries.
By running on Spark, Spark Streaming lets you reuse the same code for batch processing, join streams against historical data, or run ad-hoc queries on stream state. Build powerful interactive applications, not just analytics.
case (word, (curCount, oldCount)) =>
curCount > oldCount
}
Deployment Options
Spark Streaming can read data from HDFS, Flume, Kafka, Twitter and ZeroMQ. You can also define your own custom data sources.
You can run Spark Streaming on Spark's standalone cluster mode or other supported cluster resource managers. It also includes a local run mode for development. In production, Spark Streaming uses ZooKeeper and HDFS for high availability.
Community
Spark Streaming is developed as part of Apache Spark. It thus gets tested and updated with each Spark release.
If you have questions about the system, ask on the Spark mailing lists.
The Spark Streaming developers welcome contributions. If you'd like to help out, read how to contribute to Spark, and send us a patch!
Getting Started
To get started with Spark Streaming:
- Download Spark. It includes Streaming as a module.
- Read the Spark Streaming programming guide, which includes a tutorial and describes system architecture, configuration and high availability.
- Check out example programs in Scala and Java.