![]() Lightning-fast unified analytics engine
Lightning-fast unified analytics engine
Latest News
- Spark 2.2.3 released (Jan 11, 2019)
- Spark+AI Summit (April 23-25th, 2019, San Francisco) agenda posted (Dec 19, 2018)
- Spark 2.4.0 released (Nov 02, 2018)
- Spark 2.3.2 released (Sep 24, 2018)

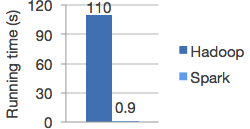
Speed
Run workloads 100x faster.
Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
Ease of Use
Write applications quickly in Java, Scala, Python, R, and SQL.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
Read JSON files with automatic schema inference
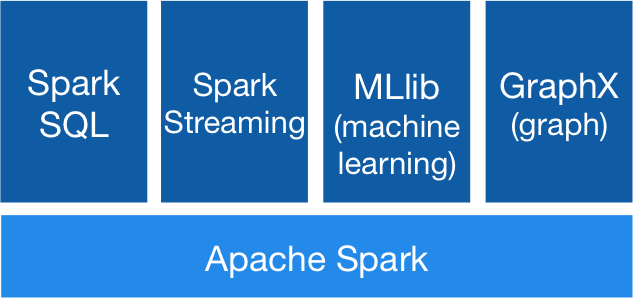
Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.

Community
Spark is used at a wide range of organizations to process large datasets. You can find many example use cases on the Powered By page.
There are many ways to reach the community:
- Use the mailing lists to ask questions.
- In-person events include numerous meetup groups and conferences.
- We use JIRA for issue tracking.
Contributors
Apache Spark is built by a wide set of developers from over 300 companies. Since 2009, more than 1200 developers have contributed to Spark!
The project's committers come from more than 25 organizations.
If you'd like to participate in Spark, or contribute to the libraries on top of it, learn how to contribute.
Getting Started
Learning Apache Spark is easy whether you come from a Java, Scala, Python, R, or SQL background:
- Download the latest release: you can run Spark locally on your laptop.
- Read the quick start guide.
- Learn how to deploy Spark on a cluster.