Note
This information was previously available at Cluster Replication.
HBase provides a replication mechanism to copy data between HBase clusters. Replication can be used as a disaster recovery solution and as a mechanism for high availability. You can also use replication to separate web-facing operations from back-end jobs such as MapReduce.
In terms of architecture, HBase replication is master-push. This takes advantage of the fact that each region server has its own write-ahead log (WAL). One master cluster can replicate to any number of slave clusters, and each region server replicates its own stream of edits. For more information on the different properties of master/slave replication and other types of replication, see the article How Google Serves Data From Multiple Datacenters.
Replication is asynchronous, allowing clusters to be geographically distant or to have some gaps in availability. This also means that data between master and slave clusters will not be instantly consistent. Rows inserted on the master are not immediately available or consistent with rows on the slave clusters. rows inserted on the master cluster won’t be available at the same time on the slave clusters. The goal is eventual consistency.
The replication format used in this design is conceptually the same as the statement-based replication design used by MySQL. Instead of SQL statements, entire WALEdits (consisting of multiple cell inserts coming from Put and Delete operations on the clients) are replicated in order to maintain atomicity.
The WALs for each region server must be kept in HDFS as long as they are needed to replicate data to any slave cluster. Each region server reads from the oldest log it needs to replicate and keeps track of the current position inside ZooKeeper to simplify failure recovery. That position, as well as the queue of WALs to process, may be different for every slave cluster.
The clusters participating in replication can be of different sizes. The master cluster relies on randomization to attempt to balance the stream of replication on the slave clusters
HBase supports master/master and cyclic replication as well as replication to multiple slaves.
Figure 17.5. Replication Architecture Overview
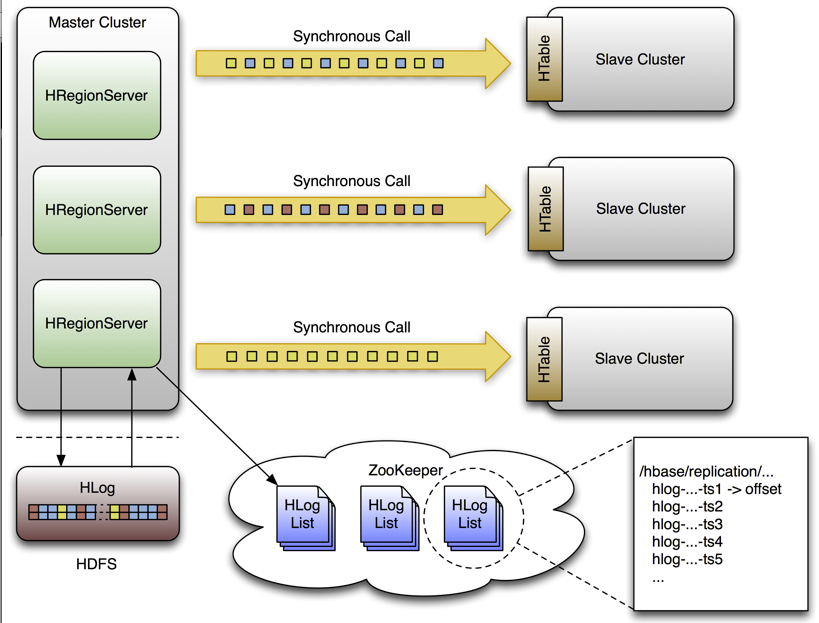
Illustration of the replication architecture in HBase, as described in the prior text.
Enabling and Configuring Replication. See the API documentation for replication for information on enabling and configuring replication.
A single WAL edit goes through several steps in order to be replicated to a slave cluster.
When the slave responds correctly:
A HBase client uses a Put or Delete operation to manipulate data in HBase.
The region server writes the request to the WAL in a way that would allow it to be replayed if it were not written successfully.
If the changed cell corresponds to a column family that is scoped for replication, the edit is added to the queue for replication.
In a separate thread, the edit is read from the log, as part of a batch process. Only the KeyValues that are eligible for replication are kept. Replicable KeyValues are part of a column family whose schema is scoped GLOBAL, are not part of a catalog such as
hbase:meta, and did not originate from the target slave cluster, in the case of cyclic replication.The edit is tagged with the master's UUID and added to a buffer. When the buffer is filled, or the reader reaches the end of the file, the buffer is sent to a random region server on the slave cluster.
The region server reads the edits sequentially and separates them into buffers, one buffer per table. After all edits are read, each buffer is flushed using HTable, HBase's normal client. The master's UUID is preserved in the edits they are applied, in order to allow for cyclic replication.
In the master, the offset for the WAL that is currently being replicated is registered in ZooKeeper.
When the slave does not respond:
The first three steps, where the edit is inserted, are identical.
Again in a separate thread, the region server reads, filters, and edits the log edits in the same way as above. The slave region server does not answer the RPC call.
The master sleeps and tries again a configurable number of times.
If the slave region server is still not available, the master selects a new subset of region server to replicate to, and tries again to send the buffer of edits.
Meanwhile, the WALs are rolled and stored in a queue in ZooKeeper. Logs that are archived by their region server, by moving them from the region server's log directory to a central log directory, will update their paths in the in-memory queue of the replicating thread.
When the slave cluster is finally available, the buffer is applied in the same way as during normal processing. The master region server will then replicate the backlog of logs that accumulated during the outage.
Preserving Tags During Replication
By default, the codec used for replication between clusters strips tags, such as
cell-level ACLs, from cells. To prevent the tags from being stripped, you can use a
different codec which does not strip them. Configure
hbase.replication.rpc.codec to use
org.apache.hadoop.hbase.codec.KeyValueCodecWithTags, on both the
source and sink RegionServers involved in the replication. This option was introduced in
HBASE-10322.
- Replication State in ZooKeeper
HBase replication maintains its state in ZooKeeper. By default, the state is contained in the base node
/hbase/replication. This node contains two child nodes, thePeersznode and theRSznode.Warning
Replication may be disrupted and data loss may occur if you delete the replication tree (
/hbase/replication/) from ZooKeeper. This is despite the information about invariants at Section 18.10.4.1, “No permanent state in ZooKeeper”. Follow progress on this issue at HBASE-10295.- The
PeersZnode The
peersznode is stored in/hbase/replication/peersby default. It consists of a list of all peer replication clusters, along with the status of each of them. The value of each peer is its cluster key, which is provided in the HBase Shell. The cluster key contains a list of ZooKeeper nodes in the cluster's quorum, the client port for the ZooKeeper quorum, and the base znode for HBase in HDFS on that cluster./hbase/replication/peers /1 [Value: zk1.host.com,zk2.host.com,zk3.host.com:2181:/hbase] /2 [Value: zk5.host.com,zk6.host.com,zk7.host.com:2181:/hbase]Each peer has a child znode which indicates whether or not replication is enabled on that cluster. These peer-state znodes do not contain any child znodes, but only contain a Boolean value. This value is read and maintained by the R
eplicationPeer.PeerStateTrackerclass./hbase/replication/peers /1/peer-state [Value: ENABLED] /2/peer-state [Value: DISABLED]- The
RSZnode The
rsznode contains a list of WAL logs which need to be replicated. This list is divided into a set of queues organized by region server and the peer cluster the region server is shipping the logs to. The rs znode has one child znode for each region server in the cluster. The child znode name is the region server's hostname, client port, and start code. This list includes both live and dead region servers./hbase/replication/rs /hostname.example.org,6020,1234 /hostname2.example.org,6020,2856Each
rsznode contains a list of WAL replication queues, one queue for each peer cluster it replicates to. These queues are represented by child znodes named by the cluster ID of the peer cluster they represent./hbase/replication/rs /hostname.example.org,6020,1234 /1 /2Each queue has one child znode for each WAL log that still needs to be replicated. the value of these child znodes is the last position that was replicated. This position is updated each time a WAL log is replicated.
/hbase/replication/rs /hostname.example.org,6020,1234 /1 23522342.23422 [VALUE: 254] 12340993.22342 [VALUE: 0]
| Option | Description | Default |
|---|---|---|
| The name of the base ZooKeeper znode used for HBase |
|
| The name of the base znode used for replication |
|
| The name of the |
|
| The name of |
|
| The name of the |
|
| Whether replication is enabled or disabled on a given cluster |
|
| How many milliseconds a worker should sleep before attempting to replicate a dead region server's WAL queues. | |
| The number of region servers a given region server should attempt to failover simultaneously. |
|
Choosing Region Servers to Replicate To. When a master cluster region server initiates a replication source to a slave cluster,
it first connects to the slave's ZooKeeper ensemble using the provided cluster key . It
then scans the rs/ directory to discover all the available sinks
(region servers that are accepting incoming streams of edits to replicate) and randomly
chooses a subset of them using a configured ratio which has a default value of 10%. For
example, if a slave cluster has 150 machines, 15 will be chosen as potential recipient for
edits that this master cluster region server sends. Because this selection is performed by
each master region server, the probability that all slave region servers are used is very
high, and this method works for clusters of any size. For example, a master cluster of 10
machines replicating to a slave cluster of 5 machines with a ratio of 10% causes the
master cluster region servers to choose one machine each at random.
A ZooKeeper watcher is placed on the
${ node of the
slave cluster by each of the master cluster's region servers. This watch is used to monitor
changes in the composition of the slave cluster. When nodes are removed from the slave
cluster, or if nodes go down or come back up, the master cluster's region servers will
respond by selecting a new pool of slave region servers to replicate to.zookeeper.znode.parent}/rs
Keeping Track of Logs. Each master cluster region server has its own znode in the replication znodes hierarchy. It contains one znode per peer cluster (if 5 slave clusters, 5 znodes are created), and each of these contain a queue of WALs to process. Each of these queues will track the WALs created by that region server, but they can differ in size. For example, if one slave cluster becomes unavailable for some time, the WALs should not be deleted, so they need to stay in the queue while the others are processed. See Region Server Failover for an example.
When a source is instantiated, it contains the current WAL that the region server is writing to. During log rolling, the new file is added to the queue of each slave cluster's znode just before it is made available. This ensures that all the sources are aware that a new log exists before the region server is able to append edits into it, but this operations is now more expensive. The queue items are discarded when the replication thread cannot read more entries from a file (because it reached the end of the last block) and there are other files in the queue. This means that if a source is up to date and replicates from the log that the region server writes to, reading up to the "end" of the current file will not delete the item in the queue.
A log can be archived if it is no longer used or if the number of logs exceeds
hbase.regionserver.maxlogs because the insertion rate is faster than regions
are flushed. When a log is archived, the source threads are notified that the path for that
log changed. If a particular source has already finished with an archived log, it will just
ignore the message. If the log is in the queue, the path will be updated in memory. If the
log is currently being replicated, the change will be done atomically so that the reader
doesn't attempt to open the file when has already been moved. Because moving a file is a
NameNode operation , if the reader is currently reading the log, it won't generate any
exception.
Reading, Filtering and Sending Edits. By default, a source attempts to read from a WAL and ship log entries to a sink as quickly as possible. Speed is limited by the filtering of log entries Only KeyValues that are scoped GLOBAL and that do not belong to catalog tables will be retained. Speed is also limited by total size of the list of edits to replicate per slave, which is limited to 64 MB by default. With this configuration, a master cluster region server with three slaves would use at most 192 MB to store data to replicate. This does not account for the data which was filtered but not garbage collected.
Once the maximum size of edits has been buffered or the reader reaces the end of the WAL, the source thread stops reading and chooses at random a sink to replicate to (from the list that was generated by keeping only a subset of slave region servers). It directly issues a RPC to the chosen region server and waits for the method to return. If the RPC was successful, the source determines whether the current file has been emptied or it contains more data which needs to be read. If the file has been emptied, the source deletes the znode in the queue. Otherwise, it registers the new offset in the log's znode. If the RPC threw an exception, the source will retry 10 times before trying to find a different sink.
Cleaning Logs. If replication is not enabled, the master's log-cleaning thread deletes old logs using a configured TTL. This TTL-based method does not work well with replication, because archived logs which have exceeded their TTL may still be in a queue. The default behavior is augmented so that if a log is past its TTL, the cleaning thread looks up every queue until it finds the log, while caching queues it has found. If the log is not found in any queues, the log will be deleted. The next time the cleaning process needs to look for a log, it starts by using its cached list.
Region Server Failover. When no region servers are failing, keeping track of the logs in ZooKeeper adds no value. Unfortunately, region servers do fail, and since ZooKeeper is highly available, it is useful for managing the transfer of the queues in the event of a failure.
Each of the master cluster region servers keeps a watcher on every other region server,
in order to be notified when one dies (just as the master does). When a failure happens,
they all race to create a znode called lock inside the dead region
server's znode that contains its queues. The region server that creates it successfully then
transfers all the queues to its own znode, one at a time since ZooKeeper does not support
renaming queues. After queues are all transferred, they are deleted from the old location.
The znodes that were recovered are renamed with the ID of the slave cluster appended with
the name of the dead server.
Next, the master cluster region server creates one new source thread per copied queue, and each of the source threads follows the read/filter/ship pattern. The main difference is that those queues will never receive new data, since they do not belong to their new region server. When the reader hits the end of the last log, the queue's znode is deleted and the master cluster region server closes that replication source.
Given a master cluster with 3 region servers replicating to a single slave with id
2, the following hierarchy represents what the znodes layout could be
at some point in time. The region servers' znodes all contain a peers
znode which contains a single queue. The znode names in the queues represent the actual file
names on HDFS in the form
address,port.timestamp
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020, 123456630/
2/
1.1.1.3,60020.1280 (Contains a position)
Assume that 1.1.1.2 loses its ZooKeeper session. The survivors will race to create a lock, and, arbitrarily, 1.1.1.3 wins. It will then start transferring all the queues to its local peers znode by appending the name of the dead server. Right before 1.1.1.3 is able to clean up the old znodes, the layout will look like the following:
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1234 (Contains a position)
1.1.1.1,60020.1265
1.1.1.2,60020,123456790/
lock
2/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
1.1.1.3,60020,123456630/
2/
1.1.1.3,60020.1280 (Contains a position)
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1214 (Contains a position)
1.1.1.2,60020.1248
1.1.1.2,60020.1312
Some time later, but before 1.1.1.3 is able to finish replicating the last WAL from 1.1.1.2, it dies too. Some new logs were also created in the normal queues. The last region server will then try to lock 1.1.1.3's znode and will begin transferring all the queues. The new layout will be:
/hbase/replication/rs/
1.1.1.1,60020,123456780/
2/
1.1.1.1,60020.1378 (Contains a position)
2-1.1.1.3,60020,123456630/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790-1.1.1.3,60020,123456630/
1.1.1.2,60020.1312 (Contains a position)
1.1.1.3,60020,123456630/
lock
2/
1.1.1.3,60020.1325 (Contains a position)
1.1.1.3,60020.1401
2-1.1.1.2,60020,123456790/
1.1.1.2,60020.1312 (Contains a position)
Replication Metrics. The following metrics are exposed at the global region server level and (since HBase 0.95) at the peer level:
source.sizeOfLogQueuenumber of WALs to process (excludes the one which is being processed) at the Replication source
source.shippedOpsnumber of mutations shipped
source.logEditsReadnumber of mutations read from HLogs at the replication source
source.ageOfLastShippedOpage of last batch that was shipped by the replication source