Let's look at a simple query with two statements. Each statement is placed as a direct child of the <query> element within the template.
<vbox datasources="http://www.xulplanet.com/ds/sample.rdf"
ref="http://www.xulplanet.com/rdf/A">
<template>
<query>
<content uri="?start"/>
<triple subject="?start"
predicate="http://www.xulplanet.com/rdf/relatedItem"
object="?relateditem"/>
</query>
<rule>
...
</rule>
</template>
</vbox>
This query has two statements, each specified with a different tag. The template won't generate anything yet since we still need to fill in the content to be generated which goes in the missing part inside the rule. However, the template builder will be able to compile the rules and examine them as described earlier.
The builder needs to start with a single result as the seed result. This is done with the content tag. It indicates that we are going to use a starting point when navigating the graph. Obviously, since you need to start somewhere, you will have to use a content tag and it should be the first statement. Also, because we can only have one starting point, only one content tag can be used. The seed result will be created like this:
(?start = http://www.xulplanet.com/rdf/A)
The variable ?start is determined from the tag's 'uri' attribute. You can use any variable you want; it's common to use the variable ?uri. However, all rules must use the same starting point variable. So if a second rule were used, it would also need to use the ?start variable. The value of ?start is set to 'http://www.xulplanet.com/rdf/A'. You'll notice that this is the value of the ref attribute which is the desired starting node in the RDF graph. Thus, the ?start variable becomes the container or reference variable.
Actually, in the current template implementation, the above description isn't quite correct. The seed is actually an internal variable set to the container, in this case, the vbox, and the ?start variable is set to the ref later, but that is a minor detail that doesn't make templates more understandable. For this discussion, assume that so far we have a single potential result as above.
The content tag doesn't do anything else at this point, meaning it doesn't add anything else to the network of potential results, so processing continues on to the next statement, the triple, which looks like this:
<triple subject="?start"
predicate="http://www.xulplanet.com/rdf/relatedItem"
object="?relateditem"/>
The triple statement is used to follow arcs or arrows in the RDF graph. The predicate attribute specifies the labels of the arrows to follow. In the triple used here, the predicate is 'http://www.xulplanet.com/rdf/relatedItem', so we know that the builder will look for arrows with that label. The builder can either follow the arrows in a forward or backward direction, but only one direction per statement. It determines which direction to use by examining which data is known and which data is not known yet. Recall the data in the potential results set:
(?start = http://www.xulplanet.com/rdf/A)
This was the seed data created by the content statement. You might be able to guess that the builder fills in the value of the ?start variable as the triple's subject, giving something like this:
<triple subject="http://www.xulplanet.com/rdf/A"
predicate="http://www.xulplanet.com/rdf/relatedItem"
object="?relateditem"/>
The builder doesn't actually change the triple, but this might clarify how the builder is working. The builder looks at both the subject and object of the triple and tries to resolve any of the variables using the known data. The ?start variable has a value 'http://www.xulplanet.com/rdf/A', so that is filled in. The ?relateditem variable doesn't have any known value, so it will be left as is. Once the variables are filled in, the builder can query the RDF graph.
The query will look for all arrows that start at the node 'http://www.xulplanet.com/rdf/A' with the predicate (or arrow label) 'http://www.xulplanet.com/rdf/relatedItem'. Since ?relateditem isn't known, the builder will allow any value for the node the arrow points to, and will look in the datasource for all possible values. In a triple statement, the subject is always the start of an arc, while the object is what it points to. For this triple, the builder will follow the arrows in the forward direction. Here is the RDF graph again:
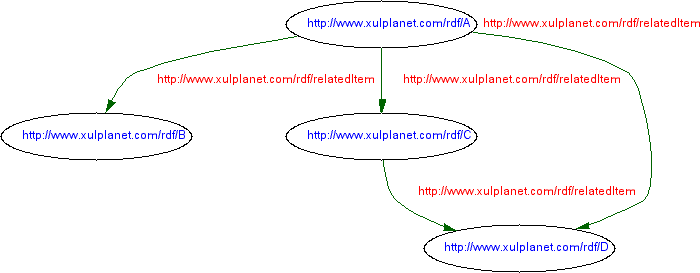
Starting at node A and following the relatedItem arcs, we can see that there are three possible values for the ?relateditem variable, B, C and D. This is new data, so the builder adds it to the graph. Since three values have been found, the network will now have three potential results:
(?start = http://www.xulplanet.com/rdf/A, ?relateditem = http://www.xulplanet.com/rdf/B) (?start = http://www.xulplanet.com/rdf/A, ?relateditem = http://www.xulplanet.com/rdf/C) (?start = http://www.xulplanet.com/rdf/A, ?relateditem = http://www.xulplanet.com/rdf/D)
You may note that the ?start variable is repeated for each result. This is because the builder copies the existing data for each new potential result and adds the new data. Internally, this isn't quite true; the builder actually maintains only one copy of the similar data but uses data structures in such a way which make it appear as if it were duplicated.
You may find this a bit confusing, but this should become clearer later with more specific and practical examples. Since the triple was the last statement, the builder moves on to the content generation phase, creating matches out of the three potential results.