Table of Contents
The term multi-tenancy in general is applied to software development to indicate an architecture in which a single running instance of an application simultaneously serves multiple clients (tenants). This is highly common in SaaS solutions. Isolating information (data, customizations, etc) pertaining to the various tenants is a particular challenge in these systems. This includes the data owned by each tenant stored in the database. It is this last piece, sometimes called multi-tenant data, on which we will focus.
There are 3 main approaches to isolating information in these multi-tenant systems which goes hand-in-hand with different database schema definitions and JDBC setups.
Note
Each approach has pros and cons as well as specific techniques and considerations. Such topics are beyond the scope of this documentation. Many resources exist which delve into these other topics. One example is http://msdn.microsoft.com/en-us/library/aa479086.aspx which does a great job of covering these topics.
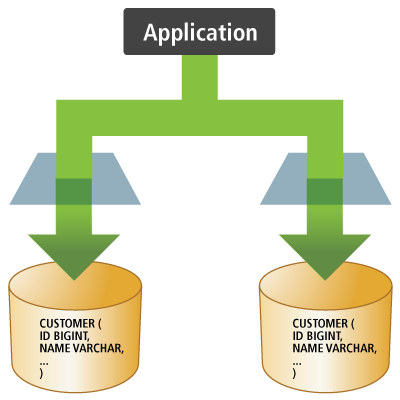
Each tenant's data is kept in a physically separate database instance. JDBC Connections would point specifically to each database, so any pooling would be per-tenant. A general application approach here would be to define a JDBC Connection pool per-tenant and to select the pool to use based on the “tenant identifier” associated with the currently logged in user.
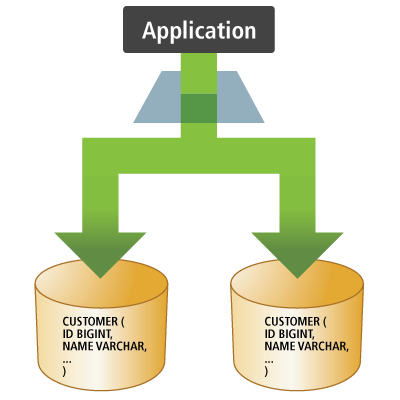
Each tenant's data is kept in a distinct database schema on a single database instance. There are 2 different ways to define JDBC Connections here:
-
Connections could point specifically to each schema, as we saw with the
Separate databaseapproach. This is an option provided that the driver supports naming the default schema in the connection URL or if the pooling mechanism supports naming a schema to use for its Connections. Using this approach, we would have a distinct JDBC Connection pool per-tenant where the pool to use would be selected based on the “tenant identifier” associated with the currently logged in user. -
Connections could point to the database itself (using some default schema) but the Connections would be altered using the SQL
SET SCHEMA(or similar) command. Using this approach, we would have a single JDBC Connection pool for use to service all tenants, but before using the Connection it would be altered to reference the schema named by the “tenant identifier” associated with the currently logged in user.
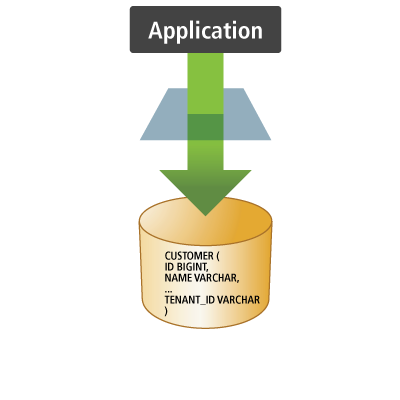
All data is kept in a single database schema. The data for each tenant is partitioned by the use of partition value or discriminator. The complexity of this discriminator might range from a simple column value to a complex SQL formula. Again, this approach would use a single Connection pool to service all tenants. However, in this approach the application needs to alter each and every SQL statement sent to the database to reference the “tenant identifier” discriminator.
Using Hibernate with multi-tenant data comes down to both an API and then integration piece(s). As usual Hibernate strives to keep the API simple and isolated from any underlying integration complexities. The API is really just defined by passing the tenant identifier as part of opening any session.
Example 17.1. Specifying tenant identifier from SessionFactory
Session session = sessionFactory.withOptions()
.tenantIdentifier( yourTenantIdentifier )
...
.openSession();
Additionally, when specifying configuration, a org.hibernate.MultiTenancyStrategy
should be named using the hibernate.multiTenancy setting. Hibernate will perform
validations based on the type of strategy you specify. The strategy here correlates to the isolation
approach discussed above.
- NONE
-
(the default) No multi-tenancy is expected. In fact, it is considered an error if a tenant identifier is specified when opening a session using this strategy.
- SCHEMA
-
Correlates to the separate schema approach. It is an error to attempt to open a session without a tenant identifier using this strategy. Additionally, a
MultiTenantConnectionProvidermust be specified. - DATABASE
-
Correlates to the separate database approach. It is an error to attempt to open a session without a tenant identifier using this strategy. Additionally, a
MultiTenantConnectionProvidermust be specified. - DISCRIMINATOR
-
Correlates to the partitioned (discriminator) approach. It is an error to attempt to open a session without a tenant identifier using this strategy. This strategy is not yet implemented in Hibernate as of 4.0 and 4.1. Its support is planned for 5.0.
When using either the DATABASE or SCHEMA approach, Hibernate needs to be able to obtain Connections
in a tenant specific manner. That is the role of the
MultiTenantConnectionProvider
contract. Application developers will need to provide an implementation of this
contract. Most of its methods are extremely self-explanatory. The only ones which might not be are
getAnyConnection and releaseAnyConnection. It is
important to note also that these methods do not accept the tenant identifier. Hibernate uses these
methods during startup to perform various configuration, mainly via the
java.sql.DatabaseMetaData object.
The MultiTenantConnectionProvider to use can be specified in a number of
ways:
-
Use the hibernate.multi_tenant_connection_provider setting. It could name a
MultiTenantConnectionProviderinstance, aMultiTenantConnectionProviderimplementation class reference or aMultiTenantConnectionProviderimplementation class name. -
Passed directly to the
org.hibernate.boot.registry.StandardServiceRegistryBuilder. -
If none of the above options match, but the settings do specify a hibernate.connection.datasource value, Hibernate will assume it should use the specific
DataSourceBasedMultiTenantConnectionProviderImplimplementation which works on a number of pretty reasonable assumptions when running inside of an app server and using onejavax.sql.DataSourceper tenant. See its javadocs for more details.
org.hibernate.context.spi.CurrentTenantIdentifierResolver is a contract
for Hibernate to be able to resolve what the application considers the current tenant identifier.
The implementation to use is either passed directly to Configuration via its
setCurrentTenantIdentifierResolver method. It can also be specified via
the hibernate.tenant_identifier_resolver setting.
There are 2 situations where CurrentTenantIdentifierResolver is used:
-
The first situation is when the application is using the
org.hibernate.context.spi.CurrentSessionContextfeature in conjunction with multi-tenancy. In the case of the current-session feature, Hibernate will need to open a session if it cannot find an existing one in scope. However, when a session is opened in a multi-tenant environment the tenant identifier has to be specified. This is where theCurrentTenantIdentifierResolvercomes into play; Hibernate will consult the implementation you provide to determine the tenant identifier to use when opening the session. In this case, it is required that aCurrentTenantIdentifierResolverbe supplied. -
The other situation is when you do not want to have to explicitly specify the tenant identifier all the time as we saw in Example 17.1, “Specifying tenant identifier from
SessionFactory”. If aCurrentTenantIdentifierResolverhas been specified, Hibernate will use it to determine the default tenant identifier to use when opening the session.
Additionally, if the CurrentTenantIdentifierResolver implementation
returns true for its validateExistingCurrentSessions
method, Hibernate will make sure any existing sessions that are found in scope have a matching
tenant identifier. This capability is only pertinent when the
CurrentTenantIdentifierResolver is used in current-session settings.
Multi-tenancy support in Hibernate works seamlessly with the Hibernate second level cache. The key used to cache data encodes the tenant identifier.
Example 17.2. Implementing MultiTenantConnectionProvider using different connection pools
/**
* Simplisitc implementation for illustration purposes supporting 2 hard coded providers (pools) and leveraging
* the support class {@link org.hibernate.service.jdbc.connections.spi.AbstractMultiTenantConnectionProvider}
*/
public class MultiTenantConnectionProviderImpl extends AbstractMultiTenantConnectionProvider {
private final ConnectionProvider acmeProvider = ConnectionProviderUtils.buildConnectionProvider( "acme" );
private final ConnectionProvider jbossProvider = ConnectionProviderUtils.buildConnectionProvider( "jboss" );
@Override
protected ConnectionProvider getAnyConnectionProvider() {
return acmeProvider;
}
@Override
protected ConnectionProvider selectConnectionProvider(String tenantIdentifier) {
if ( "acme".equals( tenantIdentifier ) ) {
return acmeProvider;
}
else if ( "jboss".equals( tenantIdentifier ) ) {
return jbossProvider;
}
throw new HibernateException( "Unknown tenant identifier" );
}
}
The approach above is valid for the DATABASE approach. It is also valid for the SCHEMA approach provided the underlying database allows naming the schema to which to connect in the connection URL.
Example 17.3. Implementing MultiTenantConnectionProvider using single connection pool
/**
* Simplisitc implementation for illustration purposes showing a single connection pool used to serve
* multiple schemas using "connection altering". Here we use the T-SQL specific USE command; Oracle
* users might use the ALTER SESSION SET SCHEMA command; etc.
*/
public class MultiTenantConnectionProviderImpl
implements MultiTenantConnectionProvider, Stoppable {
private final ConnectionProvider connectionProvider = ConnectionProviderUtils.buildConnectionProvider( "master" );
@Override
public Connection getAnyConnection() throws SQLException {
return connectionProvider.getConnection();
}
@Override
public void releaseAnyConnection(Connection connection) throws SQLException {
connectionProvider.closeConnection( connection );
}
@Override
public Connection getConnection(String tenantIdentifier) throws SQLException {
final Connection connection = getAnyConnection();
try {
connection.createStatement().execute( "USE " + tenanantIdentifier );
}
catch ( SQLException e ) {
throw new HibernateException(
"Could not alter JDBC connection to specified schema [" +
tenantIdentifier + "]",
e
);
}
return connection;
}
@Override
public void releaseConnection(String tenantIdentifier, Connection connection) throws SQLException {
try {
connection.createStatement().execute( "USE master" );
}
catch ( SQLException e ) {
// on error, throw an exception to make sure the connection is not returned to the pool.
// your requirements may differ
throw new HibernateException(
"Could not alter JDBC connection to specified schema [" +
tenantIdentifier + "]",
e
);
}
connectionProvider.closeConnection( connection );
}
...
}
This approach is only relevant to the SCHEMA approach.