| Oracle® Database VLDB and Partitioning Guide 11g Release 2 (11.2) Part Number E25523-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Database VLDB and Partitioning Guide 11g Release 2 (11.2) Part Number E25523-01 |
|
|
PDF · Mobi · ePub |
This section discusses the parallel execution process for SQL statements.
This section contains the following topics:
Each SQL statement undergoes an optimization and parallelization process when it is parsed. If parallel execution is chosen, then the following steps occur:
The user session or shadow process takes on the role of a coordinator, often called the query coordinator.
The query coordinator obtains the necessary number of parallel servers.
The SQL statement is executed as a sequence of operations (a full table scan to perform a join on a nonindexed column, an ORDER BY clause, and so on). The parallel execution servers performs each operation in parallel if possible.
When the parallel servers are finished executing the statement, the query coordinator performs any portion of the work that cannot be executed in parallel. For example, a parallel query with a SUM() operation requires adding the individual subtotals calculated by each parallel server.
Finally, the query coordinator returns any results to the user.
After the optimizer determines the execution plan of a statement, the parallel execution coordinator determines the parallel execution method for each operation in the plan. For example, the parallel execution method might be to perform a parallel full table scan by block range or a parallel index range scan by partition. The coordinator must decide whether an operation can be performed in parallel and, if so, how many parallel execution servers to enlist. The number of parallel execution servers in one set is the degree of parallelism (DOP).
The parallel execution coordinator examines each operation in a SQL statement's execution plan then determines the way in which the rows operated on by the operation must be divided or redistributed among the parallel execution servers. As an example of parallel query with intra- and inter-operation parallelism, consider the query in Example 8-1.
Example 8-1 Running an Explain Plan for a Query on Customers and Sales
EXPLAIN PLAN FOR SELECT /*+ PARALLEL(4) */ customers.cust_first_name, customers.cust_last_name, MAX(QUANTITY_SOLD), AVG(QUANTITY_SOLD) FROM sales, customers WHERE sales.cust_id=customers.cust_id GROUP BY customers.cust_first_name, customers.cust_last_name; Explained.
Note that a hint has been used in the query to specify the DOP of the tables customers and sales.
Example 8-2 shows the explain plan output for the query in Example 8-1.
Example 8-2 Explain Plan Output for a Query on Customers and Sales
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------------
Plan hash value: 4060011603
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 925 | 25900 | | | |
| 1 | PX COORDINATOR | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10003 | 925 | 25900 | Q1,03 | P->S | QC (RAND) |
| 3 | HASH GROUP BY | | 925 | 25900 | Q1,03 | PCWP | |
| 4 | PX RECEIVE | | 925 | 25900 | Q1,03 | PCWP | |
| 5 | PX SEND HASH | :TQ10002 | 925 | 25900 | Q1,02 | P->P | HASH |
|* 6 | HASH JOIN BUFFERED | | 925 | 25900 | Q1,02 | PCWP | |
| 7 | PX RECEIVE | | 630 | 12600 | Q1,02 | PCWP | |
| 8 | PX SEND HASH | :TQ10000 | 630 | 12600 | Q1,00 | P->P | HASH |
| 9 | PX BLOCK ITERATOR | | 630 | 12600 | Q1,00 | PCWC | |
| 10 | TABLE ACCESS FULL| CUSTOMERS | 630 | 12600 | Q1,00 | PCWP | |
| 11 | PX RECEIVE | | 960 | 7680 | Q1,02 | PCWP | |
| 12 | PX SEND HASH | :TQ10001 | 960 | 7680 | Q1,01 | P->P | HASH |
| 13 | PX BLOCK ITERATOR | | 960 | 7680 | Q1,01 | PCWC | |
| 14 | TABLE ACCESS FULL| SALES | 960 | 7680 | Q1,01 | PCWP | |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("SALES"."CUST_ID"="CUSTOMERS"."CUST_ID")
26 rows selected.
Figure 8-1 illustrates the data flow or query plan for the query in Example 8-1.
Figure 8-1 Data Flow Diagram for Joining Tables
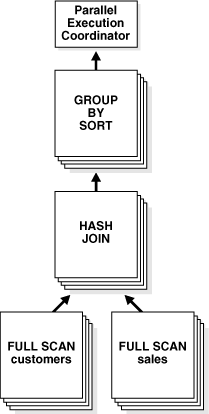
Given two sets of parallel execution servers SS1 and SS2 for the query plan illustrated in Figure 8-1, the execution proceeds as follows: each server set (SS1 and SS2) has four execution processes because of the PARALLEL hint in the query that specifies the DOP.
Child set SS1 first scans the table customers and sends rows to SS2, which builds a hash table on the rows. In other words, the consumers in SS2 and the producers in SS1 work concurrently: one in scanning customers in parallel, the other is consuming rows and building the hash table to enable the hash join in parallel. This is an example of inter-operation parallelism.
After SS1 has finished scanning the entire customers table, it scans the sales table in parallel. It sends its rows to servers in SS2, which then perform the probes to finish the hash-join in parallel. After SS1 has scanned the sales table in parallel and sent the rows to SS2, it switches to performing the GROUP BY operation in parallel. This is how two server sets run concurrently to achieve inter-operation parallelism across various operators in the query tree.
Another important aspect of parallel execution is the redistribution of rows when they are sent from servers in one server set to servers in another. For the query plan in Example 8-2, after a server process in SS1 scans a row from the customers table, which server process in SS2 should it send it to? The operator into which the rows are flowing decides the redistribution. In this case, the redistribution of rows flowing up from SS1 performing the parallel scan of customers into SS2 performing the parallel hash-join is done by hash partitioning on the join column. That is, a server process scanning customers computes a hash function of the value of the column customers.cust_id to decide the number of the server process in SS2 to send it to. The redistribution method used in parallel queries explicitly shows in the Distrib column in the EXPLAIN PLAN of the query. In Figure 8-1, "Data Flow Diagram for Joining Tables", this can be seen on lines 5, 8, and 12 of the EXPLAIN PLAN.
Operations that require the output of other operations are known as consumer operations. In Figure 8-1, the GROUP BY SORT operation is the consumer of the HASH JOIN operation because GROUP BY SORT requires the HASH JOIN output.
Consumer operations can begin consuming rows as soon as the producer operations have produced rows. In Example 8-2, while the parallel execution servers are producing rows in the FULL SCAN of the sales table, another set of parallel execution servers can begin to perform the HASH JOIN operation to consume the rows.
Each of the two operations performed concurrently is given its own set of parallel execution servers. Therefore, both query operations and the data flow tree itself have parallelism. The parallelism of an individual operation is called intra-operation parallelism and the parallelism between operations in a data flow tree is called inter-operation parallelism. Due to the producer-consumer nature of the Oracle Database operations, only two operations in a given tree must be performed simultaneously to minimize execution time. To illustrate intra- and inter-operation parallelism, consider the following statement:
SELECT * FROM employees ORDER BY last_name;
The execution plan implements a full scan of the employees table. This operation is followed by a sorting of the retrieved rows, based on the value of the last_name column. For the sake of this example, assume the last_name column is not indexed. Also assume that the DOP for the query is set to 4, which means that four parallel execution servers can be active for any given operation.
Figure 8-2 illustrates the parallel execution of the example query.
Figure 8-2 Inter-operation Parallelism and Dynamic Partitioning
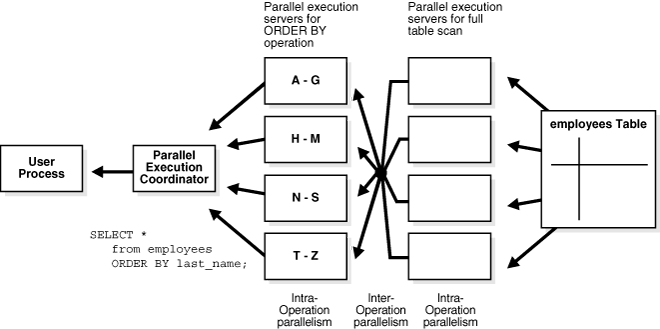
As illustrated in Figure 8-2, there are actually eight parallel execution servers involved in the query even though the DOP is 4. This is because a producer and consumer operator can be performed at the same time (inter-operation parallelism).
Also note that all of the parallel execution servers involved in the scan operation send rows to the appropriate parallel execution server performing the SORT operation. If a row scanned by a parallel execution server contains a value for the last_name column between A and G, that row is sent to the first ORDER BY parallel execution server. When the scan operation is complete, the sorting processes can return the sorted results to the query coordinator, which, in turn, returns the complete query results to the user.
To execute a query in parallel, Oracle Database generally creates a set of producer parallel execution servers and a set of consumer parallel execution servers. The producer server retrieves rows from tables and the consumer server performs operations such as join, sort, DML, and DDL on these rows. Each server in the producer set has a connection to each server in the consumer set. The number of virtual connections between parallel execution servers increases as the square of the degree of parallelism.
Each communication channel has at least one, and sometimes up to four memory buffers, which are allocated from the shared pool. Multiple memory buffers facilitate asynchronous communication among the parallel execution servers.
A single-instance environment uses at most three buffers for each communication channel. An Oracle Real Application Clusters environment uses at most four buffers for each channel. Figure 8-3 illustrates message buffers and how producer parallel execution servers connect to consumer parallel execution servers.
Figure 8-3 Parallel Execution Server Connections and Buffers
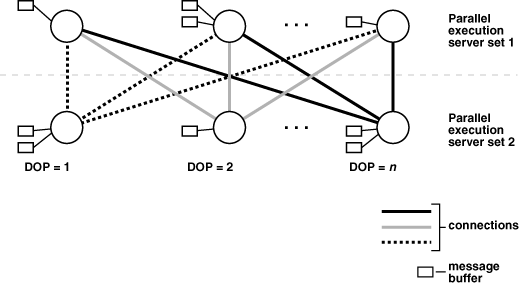
When a connection is between two processes on the same instance, the servers communicate by passing the buffers back and forth in memory (in the shared pool). When the connection is between processes in different instances, the messages are sent using external high-speed network protocols over the interconnect. In Figure 8-3, the DOP equals the number of parallel execution servers, which in this case is n. Figure 8-3 does not show the parallel execution coordinator. Each parallel execution server actually has an additional connection to the parallel execution coordinator. It is important to size the shared pool adequately when using parallel execution. If there is not enough free space in the shared pool to allocate the necessary memory buffers for a parallel server, it fails to start.
The number of parallel execution servers associated with a single operation is known as the degree of parallelism (DOP). Parallel execution is designed to effectively use multiple CPUs. the Oracle Database parallel execution framework enables you to either explicitly choose a specific degree of parallelism or to rely on Oracle Database to automatically control it.
This section contains the following topics:
A specific DOP can be requested from Oracle Database. For example, you can set a fixed DOP at a table or index level:
ALTER TABLES sales PARALLEL 8; ALTER TABLE customers PARALLEL 4;
In this case, queries accessing just the sales table use a requested DOP of 8 and queries accessing the customers table request a DOP of 4. A query accessing both the sales and the customers tables is processed with a DOP of 8 and potentially allocates 16 parallel servers (producer or consumer); whenever different DOPs are specified, Oracle Database uses the higher DOP.
If the PARALLEL clause is specified but no degree of parallelism is listed, the object gets the default DOP. Default parallelism uses a formula to determine the DOP based on the system configuration, as in the following:
For a single instance, DOP = PARALLEL_THREADS_PER_CPU x CPU_COUNT
For an Oracle RAC configuration, DOP = PARALLEL_THREADS_PER_CPU x CPU_COUNT x INSTANCE_COUNT
By default, INSTANCE_COUNT is all of the nodes in the cluster. However, if you have used Oracle RAC services to limit the number of nodes across which a parallel operation can execute, then the number of participating nodes is the number of nodes belonging to that service. For example, on a 4-node Oracle RAC cluster, with each node having 8 CPU cores and no Oracle RAC services, the default DOP would be 2 x 8 x 4 = 64.
The default DOP algorithm is designed to use maximum resources and assumes that the operation finishes faster if it can use more resources. Default parallelism targets the single-user workload. In a multiuser environment, default parallelism is not recommended.
The DOP for a SQL statement can also be set or limited by the Resource Manager. See Oracle Database Administrator's Guide for more information.
When the parameter PARALLEL_DEGREE_POLICY is set to AUTO, Oracle Database automatically decides if a statement should execute in parallel or not and what DOP it should use. Oracle Database also determines if the statement can be executed immediately or if it is queued until more system resources are available. Finally, Oracle Database decides if the statement can take advantage of the aggregated cluster memory or not.
The following is a summary of parallel statement processing when parallel degree policy is set to automatic.
A SQL statement is issued.
The statement is parsed and the optimizer determines the execution plan.
The threshold limit specified by the PARALLEL_MIN_TIME_THRESHOLD initialization parameter is checked.
If the execution time is less than the threshold limit, the SQL statement is run serially.
If the execution time is greater than the threshold limit, the statement is run in parallel based on the DOP that the optimizer calculates.
For more information, see "Determining Degree of Parallelism" and "Controlling Automatic Degree of Parallelism".
The optimizer automatically determines the DOP for a statement based on the resource requirements of the statement. The optimizer uses the cost of all scan operations (full table scan, index fast full scan, and so on) in the execution plan to determine the necessary DOP for the statement.
However, the optimizer limits the actual DOP to ensure parallel server processes do not overwhelm the system. This limit is set by the parameter PARALLEL_DEGREE_LIMIT. The default for value for this parameter is CPU, which means the number of processes is limited by the number of CPUs on the system (PARALLEL_THREADS_PER_CPU * CPU_COUNT * number of instances available) also known as the default DOP. By adjusting this parameter setting, you can control the maximum DOP the optimizer can choose for a SQL statement.
The DOP determined by the optimizer is shown in the notes section of an explain plan output (shown in the following explain plan output), visible either using the explain plan statement or V$SQL_PLAN.
EXPLAIN PLAN FOR SELECT SUM(AMOUNT_SOLD) FROM SH.SALES; PLAN TABLE OUTPUT Plan hash value: 672559287 ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost(%CPU) | Time | Pstart | Pstop | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 4 | 5 (0) | 00:00:01 | | | | 1 | SORT AGGREGATE | | 1 | 4 | | | | | | 2 | PX COORDINATOR | | 1 | 4 | | | | | | 3 | PX SEND QC(RANDOM) |:TQ10000| 1 | 4 | 5 (0) | | | | | 4 | SORT AGGREGATE | | 1 | 4 | | | | | | 5 | PX BLOCK ITERATOR | | 960 | 3840 | 5 (0) | 00:00:01 | 1 | 16 | | 6 | TABLE ACCESS FULL | SALES | 960 | 3840 | 5 (0) | 00:00:01 | 1 | 16 | -------------------------------------------------------------------------------------------------- Note ----- - Computed Degree of Parallelism is 2 - Degree of Parallelism of 2 is derived from scan of object SH.SALES
PARALLEL_MIN_TIME_THRESHOLD is the second initialization parameter that controls automatic DOP. It specifies the minimum execution time a statement should have before the statement is considered for automatic DOP. By default, this is 10 seconds. The optimizer first calculates a serial execution plan for the SQL statement; if the estimated execution elapsed time is greater than PARALLEL_MIN_TIME_THRESHOLD (10 seconds), the statement becomes a candidate for automatic DOP.
There are two initialization parameters that control automatic DOP, PARALLEL_DEGREE_POLICY and PARALLEL_MIN_TIME_THRESHOLD. They are also described in "Automatic Parallel Degree Policy" and "Controlling Automatic DOP, Parallel Statement Queuing, and In-Memory Parallel Execution". There are also two hints you can use to control parallelism.
You can set the DOP using an ALTER SESSION statement, as in the following:
ALTER SESSION SET parallel_degree_policy = limited; ALTER TABLE emp parallel (degree default);
You can use the PARALLEL hint to force parallelism. It takes an optional parameter: the DOP at which the statement should run. In addition, the NO_PARALLEL hint overrides a PARALLEL parameter in the DDL that created or altered the table.The following example illustrates forcing the statement to be executed in parallel:
SELECT /*+parallel */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
The following example illustrates forcing the statement to be executed in parallel with a degree of 10:
SELECT /*+ parallel(10) */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
The following example illustrates forcing the statement to be executed serially:
SELECT /*+ no_parallel */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
The following example illustrates computing the DOP the statement should use:
SELECT /*+ parallel(auto) */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
The following example forces the statement to use Oracle Database 11g Release 1 (11.1) behavior:
SELECT /*+ parallel(manual) */ ename, dname FROM emp e, dept d WHERE e.deptno=d.deptno;
When the parameter PARALLEL_DEGREE_POLICY is set to AUTO, Oracle Database decides if an object that is accessed using parallel execution would benefit from being cached in the SGA (also called the buffer cache). The decision to cache an object is based on a well-defined set of heuristics including the size of the object and frequency on which it is accessed. In an Oracle RAC environment, Oracle Database maps pieces of the object into each of the buffer caches on the active instances. By creating this mapping, Oracle Database automatically knows which buffer cache to access to find different parts or pieces of the object. Using this information, Oracle Database prevents multiple instances from reading the same information from disk over and over again, thus maximizing the amount of memory that can cache objects. If the size of the object is larger than the size of the buffer cache (single instance) or the size of the buffer cache multiplied by the number of active instances in an Oracle RAC cluster, then the object is read using direct-path reads.
The adaptive multiuser algorithm, which is enabled by default, reduces the degree of parallelism as the load on the system increases. When using the Oracle Database adaptive parallelism capabilities, the database uses an algorithm at SQL execution time to determine whether a parallel operation should receive the requested DOP or have its DOP lower to ensure the system is not overloaded.
In a system that makes aggressive use of parallel execution by using a high DOP, the adaptive algorithm adjusts the DOP down when only a few operations are running in parallel. While the algorithm still ensures optimal resource utilization, users may experience inconsistent response times. Using solely the adaptive parallelism capabilities in an environment that requires deterministic response times is not advised. Adaptive parallelism is controlled through the database initialization parameter PARALLEL_ADAPTIVE_MULTI_USER.
The initialization parameter PARALLEL_DEGREE_POLICY controls whether automatic degree of parallelism (DOP), parallel statement queuing, and in-memory parallel execution are enabled. This parameter has three possible values:
MANUAL - Disables automatic DOP, statement queuing and in-memory parallel execution. It reverts the behavior of parallel execution to what it was previous to Oracle Database 11g, Release 2 (11.2), which is the default.
LIMITED - Enables automatic DOP for some statements but parallel statement queuing and in-memory parallel execution are disabled. Automatic DOP is applied only to statements that access tables or indexes declared explicitly with the PARALLEL clause. Tables and indexes that have a DOP specified use that explicit DOP setting
AUTO - Enables automatic DOP, parallel statement queuing, and in-memory parallel execution.
By default, the system only uses parallel execution when a parallel degree has been explicitly set on an object or if a parallel hint is specified in the SQL statement. The degree of parallelism used is exactly what was specified. No parallel statement queue occurs and parallel execution does not use the buffer cache. For information about the parallel statement queue, refer to "Parallel Statement Queuing".
If you want Oracle Database to automatically decide the degree of parallelism only for a subset of SQL statements that touch a specific subset of objects, then set PARALLEL_DEGREE_POLICY to LIMITED and set the parallel clause on that subset of objects. If you want Oracle Database to automatically decide the degree of parallelism, then set PARALLEL_DEGREE_POLICY to AUTO.
When PARALLEL_DEGREE_POLICY is set to AUTO, Oracle Database determines whether the statement should run in parallel based on the cost of the operations in the execution plan and the hardware characteristics. The hardware characteristics include I/O calibration statistics so these statistics must be gathered otherwise Oracle Database does not use the automatic degree policy feature.
If I/O calibration is not run to gather the required statistics, the explain plan output includes the following text in its notes:
automatic DOP: skipped because of IO calibrate statistics are missing
I/O calibration statistics can be gathered with the PL/SQL DBMS_RESOURCE_MANAGER.CALIBRATE_IO procedure. I/O calibration is a one-time action if the physical hardware does not change.
See Also:
Oracle Database Performance Tuning Guide for information about I/O calibration
Oracle Database PL/SQL Packages and Types Reference for information about the DBMS_RESOURCE_MANAGER package
When the parameter PARALLEL_DEGREE_POLICY is set to AUTO, Oracle Database queues SQL statements that require parallel execution if the necessary parallel server processes are not available. After the necessary resources become available, the SQL statement is dequeued and allowed to execute. The default dequeue order is a simple first in, first out queue based on the time a statement was issued.
The following is a summary of parallel statement processing.
A SQL statements is issued.
The statement is parsed and the DOP is automatically determined.
Available parallel resources are checked.
If there are enough parallel resources and there are no statements ahead in the queue waiting for the resources, the SQL statement is executed.
If there are not enough parallel servers, the SQL statement is queued based on specified conditions and dequeued from the front of the queue when specified conditions are met.
Parallel statements are queued if running the statements would increase the number of active parallel servers above the value of the PARALLEL_SERVERS_TARGET initialization parameter. For example, if PARALLEL_SERVERS_TARGET is set to 64, the number of current active servers is 60, and a new parallel statement needs 16 parallel servers, it would be queued because 16 added to 60 is greater than 64, the value of PARALLEL_SERVERS_TARGET.
The default value is described in "PARALLEL_SERVERS_TARGET". This value is not the maximum number of parallel server processes allowed on the system, but the number available to run parallel statements before parallel statement queuing is used. It is set lower than the maximum number of parallel server processes allowed on the system (PARALLEL_MAX_SERVERS) to ensure each parallel statement gets all of the parallel server resources required and to prevent overloading the system with parallel server processes. Note all serial (nonparallel) statements execute immediately even if parallel statement queuing has been activated.
If a statement has been queued, it is identified by the resmgr:pq queued wait event.
This section discusses the following topics:
Note:
This functionality is available starting with Oracle Database 11g Release 2 (11.2.0.2).By default, the parallel statement queue operates as a first-in, first-out queue. By configuring and setting a resource plan, you can control the order in which parallel statements are dequeued and the number of parallel servers used by each workload or consumer group.
Resource plans and consumer groups are created using the DBMS_RESOURCE_MANAGER PL/SQL package. A resource plan consists of a collection of directives for each consumer group which specify controls and allocations for various database resources, such as parallel servers. A resource plan is enabled by setting the RESOURCE_MANAGER_PLAN parameter to the name of the resource plan.
The following sections describe the directives that can be used to manage the processing of parallel statements for consumer groups when the parallel degree policy is set to AUTO.
Specifying a Parallel Statement Queue Timeout for Each Consumer Group
Specifying a Degree of Parallelism Limit for Consumer Groups
A Sample Scenario for Managing Statements in the Parallel Queue
In all cases, the parallel statement queue is managed as a single queue on an Oracle RAC database. Limits for each consumer group apply to all sessions across the Oracle RAC database that belong to that consumer group. The queuing of parallel statements occurs based on the sum of the values of the PARALLEL_SERVERS_TARGET initialization parameter across all database instances.
See Also:
Oracle Database Administrator's Guide for information about managing Oracle Database resources with Resource Manager
Oracle Database Reference for information about V$RSRC* views, the DBA_HIST_RSRC_CONSUMER_GROUP view, and parallel query wait events
Oracle Database PL/SQL Packages and Types Reference for information about the DBMS_RESOURCE_MANAGER package
You can use Resource Manager to manage the order that parallel statements are dequeued from the parallel statement queue. The parallel statements for a particular consumer group are always dequeued in FIFO order. The directives mgmt_p1 ... mgmt_p8 are used to determine which consumer group's parallel statement should be dequeued next. These directives are configured using the CREATE_PLAN_DIRECTIVE or UPDATE_PLAN_DIRECTIVE procedure in the DBMS_RESOURCE_MANAGER PL/SQL package.
For example, you can create the PQ_HIGH, PQ_MEDIUM, and PQ_LOW consumer groups and map parallel statement sessions to these consumer groups based on priority. You then create a resource plan that sets mgmt_p1 to 70% for PQ_HIGH, 25% for PQ_MEDIUM, and 5% for PQ_LOW. This indicates that PQ_HIGH statements are dequeued next with a probability of 70% of the time, PQ_MEDIUM dequeued next with a probability of 25% of the time, and PQ_LOW dequeued next with a probability of 5% of the time.
You can use Resource Manager to limit the number of parallel servers that parallel statements from lower priority consumer groups can use for parallel statement processing. Using Resource Manager you can map parallel statement sessions to different consumer groups that each have specific limits on the number of the parallel servers that can be used. When these limits are specified, parallel statements from a consumer group are queued when this limit would be exceeded.
This limitation becomes useful when a database has high priority and low priority consumer groups. Without limits, a user may issue a large number of parallel statements from a low-priority consumer group that utilizes all parallel servers. When a parallel statement from a high priority consumer group is issued, the resource allocation directives can ensure that the high priority parallel statement is dequeued first. By limiting the number of parallel servers a low-priority consumer group can use, you can ensure that there are always some parallel servers available for a high priority consumer group.
To limit the parallel servers used by a consumer group, use the parallel_target_percentage parameter with the CREATE_PLAN_DIRECTIVE procedure or the new_parallel_target_percentage parameter with the UPDATE_PLAN_DIRECTIVE procedure in the DBMS_RESOURCE_MANAGER package. The parallel_target_percentage and new_parallel_target_percentage parameters specify the maximum percentage of the Oracle RAC-wide parallel server pool that is specified by PARALLEL_SERVERS_TARGET that a consumer group can use.
For example, on an Oracle RAC database system, the initialization parameter PARALLEL_SERVERS_TARGET is set to 32 on two nodes so there are a total of 32 x 2 = 64 parallel servers that can be used before queuing begins. You can set up the consumer group PQ_LOW to use 50% of the available parallel servers (parallel_target_percentage = 50) and low priority statements can then be mapped to the PQ_LOW consumer group. This scenario limits any parallel statements from the PQ_LOW consumer group to 64 x 50% = 32 parallel servers, even though there are more inactive or unused parallel servers. In this scenario, after the statements from the PQ_LOW consumer group have used 32 parallel servers, statements from that consumer group are queued.
It is possible in one database to have some sessions with the parallelism degree policy set to MANUAL and some sessions set to AUTO. In this scenario, only the sessions with parallelism degree policy set to AUTO can be queued. However, the parallel servers used in sessions where the parallelism degree policy is set to MANUAL are included in the total of all parallel servers used by a consumer group.
For information about limiting parallel resources for users, refer to "When Users Have Too Many Processes" and "Limiting the Number of Resources for a User using a Consumer Group".
You can use Resource Manager to set the maximum queue timeout limit so that parallel statements do not stay in the queue for long periods of time. Using Resource Manager you can map parallel statement sessions to different consumer groups that each have specific maximum timeout limits in a resource plan.
To manage the queue timeout, the parallel_queue_timeout parameter is used with the CREATE_PLAN_DIRECTIVE procedure or the new_parallel_queue_timeout parameter is used with the UPDATE_PLAN_DIRECTIVE procedure in the DBMS_RESOURCE_MANAGER package. The parallel_queue_timeout and new_parallel_queue_timeout parameters specify the time in seconds that a statement can remain in a consumer group parallel statement queue. After the timeout period has expired, the statement is terminated with error ORA-7454 and removed from the parallel statement queue.
You can use Resource Manager to the limit the degree of parallelism for specific consumer groups. Using Resource Manager you can map parallel statement sessions to different consumer groups that each have specific limits for the degree of parallelism in a resource plan.
To manage the limit of parallelism in consumer groups, use the parallel_degree_limit_p1 parameter with the CREATE_PLAN_DIRECTIVE procedure in the DBMS_RESOURCE_MANAGER package or the new_parallel_degree_limit_p1 parameter with the UPDATE_PLAN_DIRECTIVE procedure in the DBMS_RESOURCE_MANAGER package. The parallel_degree_limit_p1 and new_parallel_degree_limit_p1 parameters specify a limit on the degree of parallelism for any operation.
For example, you can create the PQ_HIGH, PQ_MEDIUM, and PQ_LOW consumer groups and map parallel statement sessions to these consumer groups based on priority. You then create a resource plan that specifies degree of parallelism limits so that the PQ_HIGH limit is set to 16, the PQ_MEDIUM limit is set to 8, and the PQ_LOW limit is set to 2.
This scenario discusses how to manage statements in the parallel queue with consumer groups set up with Resource Manager. For this scenario, consider a data warehouse workload that consists of three types of SQL statements:
Short-running SQL statements
Short-running identifies statements running less than one minute. You expect these statements to have very good response times.
Medium-running SQL statements
Medium-running identifies statements running more than one minute, but less than 15 minutes. You expect these statements to have reasonably good response times.
Long-running SQL statements
Long-running identifies statements that are ad-hoc or complex queries running more than 15 minutes. You expect these statements to take a long time.
For this data warehouse workload, you want better response times for the short-running statements. To achieve this goal, you must ensue that:
Long-running statements do not use all of the parallel server resources, forcing shorter statements to wait in the parallel statement queue.
When both short-running and long-running statements are queued, short-running statements should be dequeued ahead of long-running statements.
The DOP for short-running queries is limited because the speedup from a very high DOP is not significant enough to justify the use of a large number of parallel servers.
Example 8-3 shows how to set up consumer groups using Resource Manager to set priorities for statements in the parallel statement queue. Note the following for this example:
By default, users are assigned to the OTHER_GROUPS consumer group. If the estimated execution time of a SQL statement is longer than 1 minute (60 seconds), then the user switches to MEDIUM_SQL_GROUP. Because switch_for_call is set to TRUE, the user returns to OTHER_GROUPS when the statement has completed. If the user is in MEDIUM_SQL_GROUP and the estimated execution time of the statement is longer than 15 minutes (900 seconds), the user switches to LONG_SQL_GROUP. Similarly, because switch_for_call is set to TRUE, the user returns to OTHER_GROUPS when the query has completed. The directives used to accomplish the switch process are switch_time, switch_estimate, switch_for_call, and switch_group.
After the number of active parallel servers reaches the value of the PARALLEL_SERVERS_TARGET initialization parameter, subsequent parallel statements are queued. The mgmt_p[1-8] directives control the order in which parallel statements are dequeued when parallel servers become available. Because mgmt_p1 is set to 100% for SYS_GROUP in this example, parallel statements from SYS_GROUP are always dequeued first. If no parallel statements from SYS_GROUP are queued, then parallel statements from OTHER_GROUPS are dequeued with probability 70%, from MEDIUM_SQL_GROUP with probability 20%, and LONG_SQL_GROUP with probability 10%.
Parallel statements issued from OTHER_GROUPS are limited to a DOP of 4 with the setting of the parallel_degree_limit_p1 directive.
To prevent parallel statements of the LONG_SQL_GROUP group from using all of the parallel servers, which could potentially cause parallel statements from OTHER_GROUPS or MEDIUM_SQL_GROUP to wait for long periods of time, its parallel_target_percentage directive is set to 50%. This means that after LONG_SQL_GROUP has used up 50% of the parallel servers set with the PARALLEL_SERVERS_TARGET initialization parameter, its parallel statements are forced to wait in the queue.
Because parallel statements of the LONG_SQL_GROUP group may be queued for a significant amount of time, a timeout is configured for 14400 seconds (4 hours). When a parallel statement from LONG_SQL_GROUP has waited in the queue for 4 hours, the statement is terminated with the error ORA-7454.
Example 8-3 Using consumer groups to set priorities in the parallel statement queue
BEGIN
DBMS_RESOURCE_MANAGER.CREATE_PENDING_AREA();
/* Create consumer groups.
* By default, users start in OTHER_GROUPS, which is automatically
* created for every database.
*/
DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
'MEDIUM_SQL_GROUP',
'Medium-running SQL statements, between 1 and 15 minutes. Medium priority.');
DBMS_RESOURCE_MANAGER.CREATE_CONSUMER_GROUP(
'LONG_SQL_GROUP',
'Long-running SQL statements of over 15 minutes. Low priority.');
/* Create a plan to manage these consumer groups */
DBMS_RESOURCE_MANAGER.CREATE_PLAN(
'REPORTS_PLAN',
'Plan for daytime that prioritizes short-running queries');
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'SYS_GROUP', 'Directive for sys activity',
mgmt_p1 => 100);
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'OTHER_GROUPS', 'Directive for short-running queries',
mgmt_p2 => 70,
parallel_degree_limit_p1 => 4,
switch_time => 60, switch_estimate => TRUE, switch_for_call => TRUE,
switch_group => 'MEDIUM_SQL_GROUP');
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'MEDIUM_SQL_GROUP', 'Directive for medium-running queries',
mgmt_p2 => 20,
parallel_target_percentage => 80,
switch_time => 900, switch_estimate => TRUE, switch_for_call => TRUE,
switch_group => 'LONG_SQL_GROUP');
DBMS_RESOURCE_MANAGER.CREATE_PLAN_DIRECTIVE(
'REPORTS_PLAN', 'LONG_SQL_GROUP', 'Directive for medium-running queries',
mgmt_p2 => 10,
parallel_target_percentage => 50,
parallel_queue_timeout => 14400);
DBMS_RESOURCE_MANAGER.SUBMIT_PENDING_AREA();
END;
/
/* Allow all users to run in these consumer groups */
EXEC DBMS_RESOURCE_MANAGER_PRIVS.GRANT_SWITCH_CONSUMER_GROUP(
'public', 'MEDIUM_SQL_GROUP', FALSE);
EXEC DBMS_RESOURCE_MANAGER_PRIVS.GRANT_SWITCH_CONSUMER_GROUP(
'public', 'LONG_SQL_GROUP', FALSE);
Note:
This functionality is available starting with Oracle Database 11g Release 2 (11.2.0.2).Often it is important for a report or batch job that consists of multiple parallel statements to complete as quickly as possible. For example, when many reports are launched simultaneously, you may want all of the reports to complete as quickly as possible. However, you also want some specific reports to complete first, rather than all reports finishing at the same time.
If a report contains multiple parallel statements and PARALLEL_DEGREE_POLICY is set to AUTO, then each parallel statement may be forced to wait in the queue on a busy database. For example, the following steps describe a scenario in SQL statement processing:
serial statement parallel query - dop 8 -> wait in queue serial statement parallel query - dop 32 -> wait in queue parallel query - dop 4 -> wait in queue
For a report to be completed quickly, the parallel statements must be grouped to produce the following behavior:
start SQL block serial statement parallel query - dop 8 -> first parallel query: ok to wait in queue serial statement parallel query - dop 32 -> avoid or minimize wait parallel query - dop 4 -> avoid or minimize wait end SQL block
To group the parallel statements, you can use the BEGIN_SQL_BLOCK and END_SQL_BLOCK procedures in the DBMS_RESOURCE_MANAGER PL/SQL package. For each consumer group, the parallel statement queue is ordered by the time associated with each of the consumer group's parallel statements. Typically, the time associated with a parallel statement is the time that the statement was enqueued, which means that the queue appears to be FIFO. When parallel statements are grouped in a SQL block with the BEGIN_SQL_BLOCK and END_SQL_BLOCK procedures, the first queued parallel statement also uses the time that it was enqueued. However, the second and all subsequent parallel statements receive special treatment and are enqueued using the enqueue time of the first queued parallel statement within the SQL block. With this functionality, the statements frequently move to the front of the parallel statement queue. This preferential treatment ensures that their wait time is minimized.
See Also:
Oracle Database PL/SQL Packages and Types Reference for information about theDBMS_RESOURCE_MANAGER packageYou can use the NO_STATEMENT_QUEUING and STATEMENT_QUEUING hints in SQL statements to manage parallel statement queuing.
NO_STATEMENT_QUEUING
When PARALLEL_DEGREE_POLICY is set to AUTO, this hint enables a statement to bypass the parallel statement queue. For example:
SELECT /*+ NO_STATEMENT_QUEUING */ emp.last_name, dpt.department_name FROM employees emp, departments dpt WHERE emp.department_id = dpt.department_id;
STATEMENT_QUEUING
When PARALLEL_DEGREE_POLICY is not set to AUTO, this hint enables a statement to be delayed and to only run when parallel processes are available to run at the requested DOP. For example:
SELECT /*+ STATEMENT_QUEUING */ emp.last_name, dpt.department_name FROM employees emp, departments dpt WHERE emp.department_id = dpt.department_id;
When an instance starts, Oracle Database creates a pool of parallel execution servers, which are available for any parallel operation. The initialization parameter PARALLEL_MIN_SERVERS specifies the number of parallel execution servers that Oracle Database creates at instance startup.
When executing a parallel operation, the parallel execution coordinator obtains parallel execution servers from the pool and assigns them to the operation. If necessary, Oracle Database can create additional parallel execution servers for the operation. These parallel execution servers remain with the operation throughout execution. After the statement has been processed completely, the parallel execution servers return to the pool.
If the number of parallel operations increases, Oracle Database creates additional parallel execution servers to handle incoming requests. However, Oracle Database never creates more parallel execution servers for an instance than the value specified by the initialization parameter PARALLEL_MAX_SERVERS.
If the number of parallel operations decreases, Oracle Database terminates any parallel execution servers that have been idle for a threshold interval. Oracle Database does not reduce the size of the pool less than the value of PARALLEL_MIN_SERVERS, no matter how long the parallel execution servers have been idle.
Oracle Database can process a parallel operation with fewer than the requested number of processes. If all parallel execution servers in the pool are occupied and the maximum number of parallel execution servers has been started, the parallel execution coordinator switches to serial processing.
See Oracle Database Reference for information about using the initialization parameter PARALLEL_MIN_PERCENT and "Tuning General Parameters for Parallel Execution" for information about the PARALLEL_MIN_PERCENT and PARALLEL_MAX_SERVERS initialization parameters.
The basic unit of work in parallelism is a called a granule. Oracle Database divides the operation executed in parallel (for example, a table scan, table update, or index creation) into granules. Parallel execution processes execute the operation one granule at a time. The number of granules and their sizes correlate with the degree of parallelism (DOP). The number of granules also affect how well the work is balanced across query server processes.
Block range granules are the basic unit of most parallel operations, even on partitioned tables. Therefore, from an Oracle Database perspective, the degree of parallelism is not related to the number of partitions.
Block range granules are ranges of physical blocks from a table. Oracle Database computes the number and the size of the granules during run-time to optimize and balance the work distribution for all affected parallel execution servers. The number and size of granules are dependent upon the size of the object and the DOP. Block range granules do not depend on static preallocation of tables or indexes. During the computation of the granules, Oracle Database takes the DOP into account and tries to assign granules from different data files to each of the parallel execution servers to avoid contention whenever possible. Additionally, Oracle Database considers the disk affinity of the granules on massive parallel processing (MPP) systems to take advantage of the physical proximity between parallel execution servers and disks.
When partition granules are used, a parallel server process works on an entire partition or subpartition of a table or index. Because partition granules are statically determined by the structure of the table or index when a table or index is created, partition granules do not give you the flexibility in executing an operation in parallel that block granules do. The maximum allowable DOP is the number of partitions. This might limit the utilization of the system and the load balancing across parallel execution servers.
When partition granules are used for parallel access to a table or index, you should use a relatively large number of partitions (ideally, three times the DOP), so that Oracle Database can effectively balance work across the query server processes.
Partition granules are the basic unit of parallel index range scans, joins between two equipartitioned tables where the query optimizer has chosen to use partition-wise joins, and parallel operations that modify multiple partitions of a partitioned object. These operations include parallel creation of partitioned indexes, and parallel creation of partitioned tables.
You can tell which types of granules were used by looking at the execution plan of a statement. The line PX BLOCK ITERATOR above the table or index access indicates that block range granules have been used. In the following example, you can see this on line 7 of the explain plan output just above the TABLE FULL ACCESS on the SALES table.
-------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost%CPU| Time |Pst|Pst| TQ |INOUT|PQDistri|
-------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153 |565(100)|00:00:07| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153 |565(100)|00:00:07| | |Q1,01|P->S |QC(RAND)|
| 3| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 4| PX RECEIVE | | 17| 153 |565(100)|00:00:07| | |Q1,01|PCWP | |
| 5| PX SEND HASH |:TQ10000| 17| 153 |565(100)|00:00:07| | |Q1,00|P->P | HASH |
| 6| HASH GROUP BY | | 17| 153 |565(100)|00:00:07| | |Q1,00|PCWP | |
| 7| PX BLOCK ITERATOR | | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWC | |
|*8| TABLE ACCESS FULL| SALES | 10M| 85M | 60(97) |00:00:01| 1 | 16|Q1,00|PCWP | |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - filter("CUST_ID"<=22810 AND "CUST_ID">=22300)
When partition granules are used, you see the line PX PARTITION RANGE above the table or index access in the explain plan output. On line 6 of the example that follows, the plan has PX PARTITION RANGE ALL because this statement accesses all of the 16 partitions in the table. If not all of the partitions are accessed, it simply shows PX PARTITION RANGE.
---------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Byte|Cost%CPU| Time |Ps|Ps| TQ |INOU|PQDistri|
---------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 17| 153| 2(50)|00:00:01| | | | | |
| 1| PX COORDINATOR | | | | | | | | | | |
| 2| PX SEND QC(RANDOM) |:TQ10001| 17| 153| 2(50)|00:00:01| | |Q1,01|P->S|QC(RAND)|
| 3| HASH GROUP BY | | 17| 153| 2(50)|00:00:01| | |Q1,01|PCWP| |
| 4| PX RECEIVE | | 26| 234| 1(0)|00:00:01| | |Q1,01|PCWP| |
| 5| PX SEND HASH |:TQ10000| 26| 234| 1(0)|00:00:01| | |Q1,00|P->P| HASH |
| 6| PX PARTITION RANGE ALL | | 26| 234| 1(0)|00:00:01| | |Q1,00|PCWP| |
| 7| TABLEACCESSLOCAL INDEX ROWID|SALES| 26| 234| 1(0)|00:00:01| 1|16|Q1,00|PCWC| |
|*8| INDEX RANGE SCAN |SALES_CUST|26| | 1(0)|00:00:01| 1|16|Q1,00|PCWP| |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - access("CUST_ID"<=22810 AND "CUST_ID">=22300)
To optimize performance, all parallel execution servers should have equal workloads. For SQL statements run in parallel by block range or by parallel execution servers, the workload is dynamically divided among the parallel execution servers. This minimizes workload skewing, which occurs when some parallel execution servers perform significantly more work than the other processes.
For the relatively few SQL statements executed in parallel by partitions, if the workload is evenly distributed among the partitions, you can optimize performance by matching the number of parallel execution servers to the number of partitions or by choosing a DOP in which the number of partitions is a multiple of the number of processes. This applies to partition-wise joins and parallel DML on tables created before Oracle9i. See "Limitation on the Degree of Parallelism" for more information.
For example, suppose a table has 16 partitions, and a parallel operation divides the work evenly among them. You can use 16 parallel execution servers (DOP equals 16) to do the work in approximately one-tenth the time that one process would take. You might also use five processes to do the work in one-fifth the time, or two processes to do the work in one-half the time.
If, however, you use 15 processes to work on 16 partitions, the first process to finish its work on one partition then begins work on the 16th partition; and as the other processes finish their work, they become idle. This configuration does not provide good performance when the work is evenly divided among partitions. When the work is unevenly divided, the performance varies depending on whether the partition that is left for last has more or less work than the other partitions.
Similarly, suppose you use six processes to work on 16 partitions and the work is evenly divided. In this case, each process works on a second partition after finishing its first partition, but only four of the processes work on a third partition while the other two remain idle.
In general, you cannot assume that the time taken to perform a parallel operation on a given number of partitions (N) with a given number of parallel execution servers (P) equals N divided by P. This formula does not consider the possibility that some processes might have to wait while others finish working on the last partitions. By choosing an appropriate DOP, however, you can minimize the workload skew and optimize performance.
By default, in an Oracle RAC environment, a SQL statement executed in parallel can run across all of the nodes in the cluster. For this cross-node or inter-node parallel execution to perform, the interconnection in the Oracle RAC environment must be size appropriately because inter-node parallel execution may result in a lot of interconnect traffic. If the interconnection has a considerably lower bandwidth in comparison to the I/O bandwidth from the server to the storage subsystem, it may be better to restrict the parallel execution to a single node or to a limited number of nodes. Inter-node parallel execution does not scale with an undersized interconnection.
To limit inter-node parallel execution, you can control parallel execution in an Oracle RAC environment using the PARALLEL_FORCE_LOCAL initialization parameter. By setting this parameter to TRUE, the parallel server processes can only execute on the same Oracle RAC node where the SQL statement was started.
In Oracle Real Application Clusters, services are used to limit the number of instances that participate in a parallel SQL operation. The default service includes all available instances. You can create any number of services, each consisting of one or more instances. Parallel execution servers are to be used only on instances that are members of the specified service.
See Also:
Oracle Real Application Clusters Administration and Deployment Guide for more information about instance groups
|
Copyright © 2008, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|