| Oracle® Database VLDB and Partitioning Guide 11g Release 2 (11.2) Part Number E25523-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Database VLDB and Partitioning Guide 11g Release 2 (11.2) Part Number E25523-01 |
|
|
PDF · Mobi · ePub |
This section discusses the following topics:
You can set initialization parameters to determine resource limits. The parameters that establish resource limits are discussed in the following topics:
See Also:
Oracle Database Reference for information about initialization parametersThis parameter specifies whether a SQL statement executed in parallel is restricted to a single instance in an Oracle RAC environment. By setting this parameter to TRUE, you restrict the scope of the parallel server processed to the single Oracle RAC instance where the query coordinator is running.
The recommended value for the PARALLEL_FORCE_LOCAL parameter is FALSE.
PARALLEL_THREADS_PER_CPU x CPU_COUNT x concurrent_parallel_users x 5
In the formula, the value assigned to concurrent_parallel_users running at the default degree of parallelism on an instance is dependent on the memory management setting. If automatic memory management is disabled (manual mode), then the value of concurrent_parallel_users is 1. If PGA automatic memory management is enabled, then the value of concurrent_parallel_users is 2. If global memory management or SGA memory target is used in addition to PGA automatic memory management, then the value of concurrent_parallel_users is 4.
The preceding formula might not be sufficient for parallel queries on tables with higher degree of parallelism (DOP) attributes. For users who expect to run queries of higher DOP, set the value to the following:
2 x DOP x NUMBER_OF_CONCURRENT_USERS
For example, setting the value to 64 enables you to run four parallel queries simultaneously, if each query is using two slave sets with a DOP of 8 for each set.
When concurrent users have too many query server processes, memory contention (paging), I/O contention, or excessive context switching can occur. This contention can reduce system throughput to a level lower than if parallel execution were not used. Increase the PARALLEL_MAX_SERVERS value only if the system has sufficient memory and I/O bandwidth for the resulting load.
You can use performance monitoring tools of the operating system to determine how much memory, swap space and I/O bandwidth are free. Look at the run queue lengths for both your CPUs and disks, and the service time for I/O operations on the system. Verify that the system has sufficient swap space to add more processes. Limiting the total number of query server processes might restrict the number of concurrent users who can execute parallel operations, but system throughput tends to remain stable.
You can limit the amount of parallelism available to a given user by establishing a resource consumer group for the user. Do this to limit the number of sessions, concurrent logons, and the number of parallel processes that any one user or group of users can have.
Each query server process working on a parallel execution statement is logged on with a session ID. Each process counts against the user's limit of concurrent sessions. For example, to limit a user to 10 parallel execution processes, set the user's limit to 11. One process is for the parallel execution coordinator and the other 10 consist of two sets of query servers. This would allow one session for the parallel execution coordinator and 10 sessions for the parallel execution processes.
See Oracle Database Administrator's Guide for more information about managing resources with user profiles and Oracle Real Application Clusters Administration and Deployment Guide for more information about querying GV$ views.
This parameter enables users to wait for an acceptable DOP, depending on the application in use. The recommended value for the PARALLEL_MIN_PERCENT parameter is 0 (zero).
Setting this parameter to values other than 0 (zero) causes Oracle Database to return an error when the requested DOP cannot be satisfied by the system at a given time. For example, if you set PARALLEL_MIN_PERCENT to 50, which translates to 50 percent, and the DOP is reduced by 50 percent or greater because of the adaptive algorithm or because of a resource limitation, then Oracle Database returns ORA-12827. For example:
SELECT /*+ FULL(e) PARALLEL(e, 8) */ d.department_id, SUM(SALARY) FROM employees e, departments d WHERE e.department_id = d.department_id GROUP BY d.department_id ORDER BY d.department_id;
Oracle Database responds with this message:
ORA-12827: insufficient parallel query slaves available
This parameter specifies the number of processes to be started in a single instance that are reserved for parallel operations. The syntax is:
PARALLEL_MIN_SERVERS=n
The n variable is the number of processes you want to start and reserve for parallel operations.
Setting PARALLEL_MIN_SERVERS balances the startup cost against memory usage. Processes started using PARALLEL_MIN_SERVERS do not exit until the database is shut down. This way, when a query is issued, the processes are likely to be available.
This parameter specifies the minimum execution time a statement should have before the statement is considered for automatic degree of parallelism. By default, this is set to 10 seconds. Automatic degree of parallelism is only enabled if PARALLEL_DEGREE_POLICY is set to AUTO or LIMITED. The syntax is:
PARALLEL_MIN_TIME_THRESHOLD = { AUTO | integer }
The default is AUTO.
This parameter specifies the number of parallel server processes allowed to run parallel statements before statement queuing is used. The default value is:
PARALLEL_THREADS_PER_CPU * CPU_COUNT * concurrent_parallel_users * 2
In the formula, the value assigned to concurrent_parallel_users running at the default degree of parallelism on an instance is dependent on the memory management setting. If automatic memory management is disabled (manual mode), then the value of concurrent_parallel_users is 1. If PGA automatic memory management is enabled, then the value of concurrent_parallel_users is 2. If global memory management or SGA memory target is used in addition to PGA automatic memory management, then the value of concurrent_parallel_users is 4.
When PARALLEL_DEGREE_POLICY is set to AUTO, statements that require parallel execution are queued if the number of parallel processes currently in use on the system equals or is greater than PARALLEL_SERVERS_TARGET. This is not the maximum number of parallel server processes allowed on a system (that is controlled by PARALLEL_MAX_SERVERS). However, PARALLEL_SERVERS_TARGET and parallel statement queuing is used to ensure that each statement that requires parallel execution is allocated the necessary parallel server resources and the system is not flooded with too many parallel server processes.
Parallel execution requires memory resources in addition to those required by serial SQL execution. Additional memory is used for communication and passing data between query server processes and the query coordinator.
Oracle Database allocates memory for query server processes from the shared pool. Tune the shared pool as follows:
Allow for other clients of the shared pool, such as shared cursors and stored procedures.
Remember that larger values improve performance in multiuser systems, but smaller values use less memory.
You can then monitor the number of buffers used by parallel execution and compare the shared pool PX msg pool to the current high water mark reported in output from the view V$PX_PROCESS_SYSSTAT.
Note:
If you do not have enough memory available, error message 12853 occurs (insufficient memory for PX buffers: current stringK, max needed stringK). This is caused by having insufficient SGA memory available for PX buffers. You must reconfigure the SGA to have at least (MAX - CURRENT) bytes of additional memory.By default, Oracle Database allocates parallel execution buffers from the shared pool.
If Oracle Database displays the following error on startup, you should reduce the value for SHARED_POOL_SIZE low enough so your database starts:
ORA-27102: out of memory SVR4 Error: 12: Not enough space
After reducing the value of SHARED_POOL_SIZE, you might see the error:
ORA-04031: unable to allocate 16084 bytes of shared memory
("SHARED pool","unknown object","SHARED pool heap","PX msg pool")
If so, execute the following query to determine why Oracle Database could not allocate the 16,084 bytes:
SELECT NAME, SUM(BYTES) FROM V$SGASTAT WHERE POOL='SHARED POOL' GROUP BY ROLLUP (NAME);
Your output should resemble the following:
NAME SUM(BYTES)
-------------------------- ----------
PX msg pool 1474572
free memory 562132
2036704
If you specify SHARED_POOL_SIZE and the amount of memory you specify to reserve is bigger than the pool, Oracle Database does not allocate all the memory it can get. Instead, it leaves some space. When the query runs, Oracle Database tries to get what it needs. Oracle Database uses the 560 KB and needs another 16 KB when it fails. The error does not report the cumulative amount that is needed. The best way of determining how much more memory is needed is to use the formulas in "Adding Memory for Message Buffers".
To resolve the problem in the current example, increase the value for SHARED_POOL_SIZE. As shown in the sample output, the SHARED_POOL_SIZE is about 2 MB. Depending on the amount of memory available, you could increase the value of SHARED_POOL_SIZE to 4 MB and attempt to start your database. If Oracle Database continues to display an ORA-4031 message, gradually increase the value for SHARED_POOL_SIZE until startup is successful.
After you determine the initial setting for the shared pool, you must calculate additional memory requirements for message buffers and determine how much additional space you need for cursors.
You must increase the value for the SHARED_POOL_SIZE parameter to accommodate message buffers. The message buffers allow query server processes to communicate with each other.
Oracle Database uses a fixed number of buffers for each virtual connection between producer query servers and consumer query servers. Connections increase as the square of the DOP increases. For this reason, the maximum amount of memory used by parallel execution is bound by the highest DOP allowed on your system. You can control this value by using either the PARALLEL_MAX_SERVERS parameter or by using policies and profiles.
To calculate the amount of memory required, use one of the following formulas:
For SMP systems:
mem in bytes = (3 x size x users x groups x connections)
For Oracle Real Application Clusters and MPP systems:
mem in bytes = ((3 x local) + (2 x remote)) x (size x users x groups) / instances
Each instance uses the memory computed by the formula.
The terms are:
SIZE = PARALLEL_EXECUTION_MESSAGE_SIZE
USERS = the number of concurrent parallel execution users that you expect to have running with the optimal DOP
GROUPS = the number of query server process groups used for each query
A simple SQL statement requires only one group. However, if your queries involve subqueries which are processed in parallel, then Oracle Database uses an additional group of query server processes.
CONNECTIONS = (DOP2 + 2 x DOP)
If your system is a cluster or MPP, then you should account for the number of instances because this increases the DOP. In other words, using a DOP of 4 on a two-instance cluster results in a DOP of 8. A value of PARALLEL_MAX_SERVERS times the number of instances divided by four is a conservative estimate to use as a starting point.
LOCAL = CONNECTIONS/INSTANCES
REMOTE = CONNECTIONS - LOCAL
Add this amount to your original setting for the shared pool. However, before setting a value for either of these memory structures, you must also consider additional memory for cursors, as explained in the following section.
The formulas in this section are just starting points. Whether you are using automated or manual tuning, you should monitor usage on an on-going basis to ensure the size of memory is not too large or too small. To ensure the correct memory size, tune the shared pool using the following query:
SELECT POOL, NAME, SUM(BYTES) FROM V$SGASTAT WHERE POOL LIKE '%pool%' GROUP BY ROLLUP (POOL, NAME);
Your output should resemble the following:
POOL NAME SUM(BYTES)
----------- -------------------------- ----------
shared pool Checkpoint queue 38496
shared pool KGFF heap 1964
shared pool KGK heap 4372
shared pool KQLS heap 1134432
shared pool LRMPD SGA Table 23856
shared pool PLS non-lib hp 2096
shared pool PX subheap 186828
shared pool SYSTEM PARAMETERS 55756
shared pool State objects 3907808
shared pool character set memory 30260
shared pool db_block_buffers 200000
shared pool db_block_hash_buckets 33132
shared pool db_files 122984
shared pool db_handles 52416
shared pool dictionary cache 198216
shared pool dlm shared memory 5387924
shared pool event statistics per sess 264768
shared pool fixed allocation callback 1376
shared pool free memory 26329104
shared pool gc_* 64000
shared pool latch nowait fails or sle 34944
shared pool library cache 2176808
shared pool log_buffer 24576
shared pool log_checkpoint_timeout 24700
shared pool long op statistics array 30240
shared pool message pool freequeue 116232
shared pool miscellaneous 267624
shared pool processes 76896
shared pool session param values 41424
shared pool sessions 170016
shared pool sql area 9549116
shared pool table columns 148104
shared pool trace_buffers_per_process 1476320
shared pool transactions 18480
shared pool trigger inform 24684
shared pool 52248968
90641768
Evaluate the memory used as shown in your output, and alter the setting for SHARED_POOL_SIZE based on your processing needs.
To obtain more memory usage statistics, execute the following query:
SELECT * FROM V$PX_PROCESS_SYSSTAT WHERE STATISTIC LIKE 'Buffers%';
Your output should resemble the following:
STATISTIC VALUE ------------------- ----- Buffers Allocated 23225 Buffers Freed 23225 Buffers Current 0 Buffers HWM 3620
The amount of memory used appears in the Buffers Current and Buffers HWM statistics. Calculate a value in bytes by multiplying the number of buffers by the value for PARALLEL_EXECUTION_MESSAGE_SIZE. Compare the high water mark to the parallel execution message pool size to determine if you allocated too much memory. For example, in the first output, the value for large pool as shown in px msg pool is 38,092,812 or 38 MB. The Buffers HWM from the second output is 3,620, which when multiplied by a parallel execution message size of 4,096 is 14,827,520, or approximately 15 MB. In this case, the high water mark has reached approximately 40 percent of its capacity.
Before considering the following section, you should read the descriptions of the MEMORY_TARGET and MEMORY_MAX_TARGET initialization parameters in Oracle Database Performance Tuning Guide and Oracle Database Administrator's Guide for details. The PGA_AGGREGATE_TARGET initialization parameter need not be set as MEMORY_TARGET autotunes the SGA and PGA components.
The first group of parameters discussed in this section affects memory and resource consumption for all parallel operations, in particular, for parallel execution. These parameters are:
A second subset of parameters are discussed in "Parameters Affecting Resource Consumption for Parallel DML and Parallel DDL".
To control resource consumption, you should configure memory at two levels:
At the database level, so the system uses an appropriate amount of memory from the operating system.
At the operating system level for consistency.
On some platforms, you might need to set operating system parameters that control the total amount of virtual memory available, totalled across all processes.
A large percentage of the memory used in data warehousing operations (compared to OLTP) is more dynamic. This memory comes from Process Global Area (PGA), and both the size of process memory and the number of processes can vary greatly. Use the PGA_AGGREGATE_TARGET initialization parameter to control both the process memory and the number of processes in such cases. Explicitly setting PGA_AGGREGATE_TARGET along with MEMORY_TARGET ensures that autotuning still occurs but PGA_AGGREGATE_TARGET is not tuned below the specified value.
You can simplify and improve the way PGA memory is allocated by enabling automatic PGA memory management. In this mode, Oracle Database dynamically adjusts the size of the portion of the PGA memory dedicated to work areas, based on an overall PGA memory target explicitly set by the DBA. To enable automatic PGA memory management, you must set the initialization parameter PGA_AGGREGATE_TARGET. For new installations, PGA_AGGREGATE_TARGET and SGA_TARGET are set automatically by the database configuration assistant (DBCA), and MEMORY_TARGET is zero. That is, automatic memory management is disabled. You can enable it in Oracle Enterprise Manager on the Memory Parameters page. Therefore, automatic tuning of the aggregate PGA is enabled by default. However, the aggregate PGA does not grow unless you enable automatic memory management by setting MEMORY_TARGET to a nonzero value.
See Oracle Database Performance Tuning Guide for descriptions of how to use PGA_AGGREGATE_TARGET in different scenarios.
The PARALLEL_EXECUTION_MESSAGE_SIZE parameter specifies the size of the buffer used for parallel execution messages. The default value is operating system-specific, but is typically 16 K. This value should be adequate for most applications.
The parameters that affect parallel DML and parallel DDL resource consumption are:
Parallel insert, update, and delete operations require more resources than serial DML operations. Similarly, PARALLEL CREATE TABLE ... AS SELECT and PARALLEL CREATE INDEX can require more resources. For this reason, you may need to increase the value of several additional initialization parameters. These parameters do not affect resources for queries.
For parallel DML and DDL, each query server process starts a transaction. The parallel execution coordinator uses the two-phase commit protocol to commit transactions; therefore, the number of transactions being processed increases by the DOP. Consequently, you might need to increase the value of the TRANSACTIONS initialization parameter.
The TRANSACTIONS parameter specifies the maximum number of concurrent transactions. The default assumes no parallelism. For example, if you have a DOP of 20, you have 20 more new server transactions (or 40, if you have two server sets) and 1 coordinator transaction. In this case, you should increase TRANSACTIONS by 21 (or 41) if the transactions are running in the same instance. If you do not set this parameter, Oracle Database sets it to a value equal to 1.1 x SESSIONS. This discussion does not apply if you are using server-managed undo.
If a system fails when there are uncommitted parallel DML or DDL transactions, you can speed up transaction recovery during startup by using the FAST_START_PARALLEL_ROLLBACK parameter.
This parameter controls the DOP used when recovering terminated transactions. Terminated transactions are transactions that are active before a system failure. By default, the DOP is chosen to be at most two times the value of the CPU_COUNT parameter.
If the default DOP is insufficient, set the parameter to HIGH. This gives a maximum DOP of at most four times the value of the CPU_COUNT parameter. This feature is available by default.
This parameter specifies the maximum number of DML locks. Its value should equal the total number of locks on all tables referenced by all users. A parallel DML operation's lock requirement is very different from serial DML. Parallel DML holds many more locks, so you should increase the value of the DML_LOCKS parameter by equal amounts.
Note:
Parallel DML operations are not performed when the table lock of the target table is disabled.Table 8-4 shows the types of locks acquired by coordinator and parallel execution server processes for different types of parallel DML statements. Using this information, you can determine the value required for these parameters.
Table 8-4 Locks Acquired by Parallel DML Statements
| Type of Statement | Coordinator Process Acquires: | Each Parallel Execution Server Acquires: |
|---|---|---|
|
Parallel |
1 table lock SX 1 partition lock X for each pruned partition or subpartition |
1 table lock SX 1 partition lock 1 partition-wait lock S for each pruned partition or subpartition owned by the query server process |
|
Parallel row-migrating |
1 table lock SX 1 partition X lock for each pruned partition or subpartition 1 partition lock SX for all other partitions or subpartitions |
1 table lock SX 1 partition lock 1 partition-wait lock S for each pruned partition owned by the query server process 1 partition lock SX for all other partitions or subpartitions |
|
Parallel |
1 table lock SX Partition locks X for all partitions or subpartitions |
1 table lock SX 1 partition lock 1 partition-wait lock S for each partition or subpartition |
|
Parallel |
1 table lock SX 1 partition lock X for each specified partition or subpartition |
1 table lock SX 1 partition lock 1 partition-wait lock S for each specified partition or subpartition |
|
Parallel |
1 table lock X |
None |
Note:
Table, partition, and partition-wait DML locks all appear as TM locks in theV$LOCK view.Consider a table with 600 partitions running with a DOP of 100. Assume all partitions are involved in a parallel UPDATE or DELETE statement with no row-migrations.
The coordinator acquires:
1 table lock SX
600 partition locks X
Total server processes acquire:
100 table locks SX
600 partition locks NULL
600 partition-wait locks S
The parameters that affect I/O are:
These parameters also affect the optimizer, which ensures optimal performance for parallel execution of I/O operations.
When you perform parallel update, merge, and delete operations, the buffer cache behavior is very similar to any OLTP system running a high volume of updates.
The recommended value for this parameter is 8 KB or 16 KB.
Set the database block size when you create the database. If you are creating a new database, use a large block size such as 8 KB or 16 KB.
This parameter determines how many database blocks are read with a single operating system READ call. In this release, the default value of this parameter is a value that corresponds to the maximum I/O size that can be performed efficiently. The maximum I/O size value is platform-dependent and is 1 MB for most platforms. If you set DB_FILE_MULTIBLOCK_READ_COUNT to an excessively high value, your operating system lowers the value to the highest allowable level when you start your database.
The recommended value for both of these parameters is TRUE.
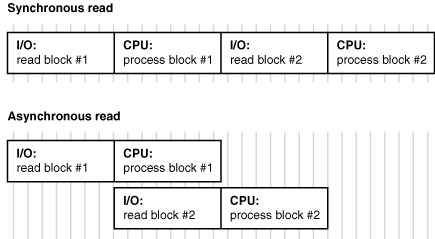
These parameters enable or disable the operating system's asynchronous I/O facility. They allow query server processes to overlap I/O requests with processing when performing table scans. If the operating system supports asynchronous I/O, leave these parameters at the default value of TRUE. Figure 8-6 illustrates how asynchronous read works.
Asynchronous operations are currently supported for parallel table scans, hash joins, sorts, and serial table scans. However, this feature can require operating system-specific configuration and may not be supported on all platforms.
|
Copyright © 2008, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|