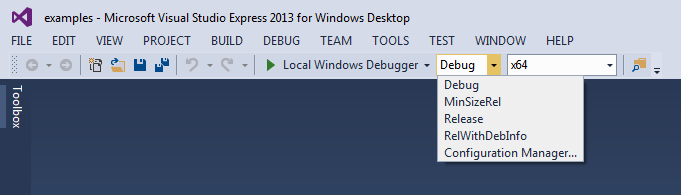
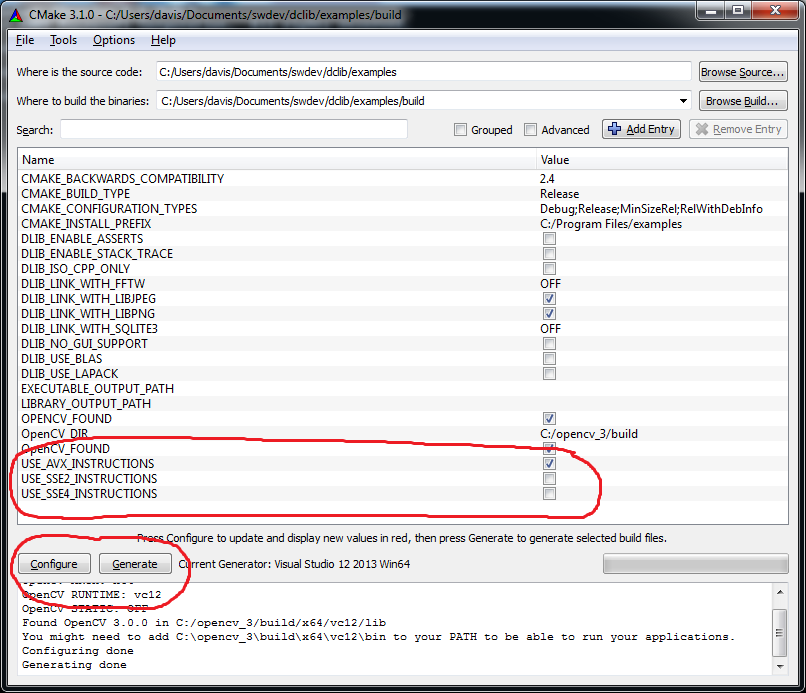
The Library
Help/Info
Current Release
- Algorithms
- API Wrappers
- Bayesian Nets
- Compression
- Containers
- Graph Tools
- Image Processing
- Linear Algebra
- Machine Learning
- Metaprogramming
- Miscellaneous
- Networking
- Optimization
- Parsing
Help/Info
- Dlib Blog
 Examples: C++
Examples: C++- Examples: Python
- FAQ
- Home
- How to compile
- How to contribute
- Index
- Introduction
- License
- Python API
- Suggested Books
- Who uses dlib?
Current Release
- Change Log
- Release Notes
- Version: 19.7