| Oracle® Communications Data Model Implementation and Operations Guide Release 11.3.1 Part Number E28442-04 |
|
|
PDF · Mobi · ePub |
| Oracle® Communications Data Model Implementation and Operations Guide Release 11.3.1 Part Number E28442-04 |
|
|
PDF · Mobi · ePub |
This chapter discusses the ETL (extraction, transformation and loading) programs you use to populate an Oracle Communications Data Model warehouse. It includes the following topics:
ETL for the Foundation Layer of an Oracle Communications Data Model Warehouse
Customizing Intra-ETL for the Oracle Communications Data Model
Performing an Initial Load of an Oracle Communications Data Model Warehouse
Refreshing the Data in an Oracle Communications Data Model Warehouse
Managing Errors During Oracle Communications Data Model Intra-ETL Execution
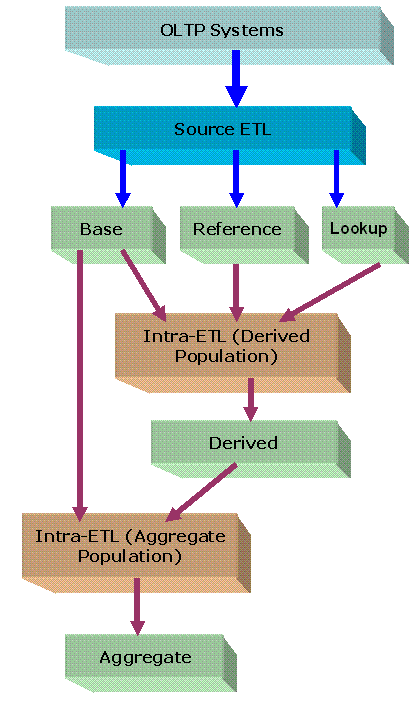
Figure 2-1, "Layers of an Oracle Communications Data Model Warehouse" illustrated the three layers in Oracle Communications Data Model warehouse environment: the optional staging layer, the foundation layer, and the access layer. As illustrated by Figure 4-1, you use two types of ETL (extraction, transformation and loading) to populate these layers:
Source-ETL. ETL that populates the staging layer (if any) and the foundation layer (that is, the base, reference, and lookup tables) with data from the OLTP system is known as source ETL.
Oracle Communications Data Model does not include source-ETL scripts. Unless you are using an application adapter for Oracle Communications Data Model, you must create source-ETL yourself using your understanding of your OLTP system and your customized Oracle Communications Data Model. See "ETL for the Foundation Layer of an Oracle Communications Data Model Warehouse" for more information on creating source-ETL.
Intra-ETL. ETL that populates the access layer (that is, the derived tables, aggregate tables, materialized views, OLAP cubes, and data mining models) using the data in the foundation layer is known as intra-ETL.
Oracle Communications Data Model does include intra-ETL. You can modify the default intra-ETL to populate a customized access layer from a customized foundation layer. See "Customizing Intra-ETL for the Oracle Communications Data Model" for more information on the intra-ETL.
ETL that populates the foundation layer of an Oracle Communications Data Model warehouse (that is, the base, reference, and lookup tables) with data from an OLTP system is known as source-ETL.
You can populate the foundation layer of an Oracle Communications Data Model warehouse in the following ways:
If an application adapter for Oracle Communications Data Model is available for the system from which you want to populate the foundation layer of an Oracle Communications Data Model warehouse, you can use that adapter to populate the foundation layer. For more information, see "Using an Application Adapter to Populate the Foundation Layer".
Write your own source-ETL scripts using Oracle Warehouse Builder or another ETL tool and then use those scripts to populate the foundation layer. For more information, see "Writing Your Own Source-ETL".
If an Application Adapter for Oracle Communications Data Model is available for the application that populates your OLTP system, you use that adapter to populate the foundation layer of your Oracle Communications Data Model warehouse.
For example, if want to populate the foundation layer of your Oracle Communications Data Model warehouse with data from your Oracle Communications Network Charging and Control system, then you can use the Oracle Communications Network Charging and Control Adapter for Oracle Communications Data Model. See Appendix C, "Using the NCC Adapter for Oracle Communications Data Model" for more information
If you are not using an application adapter for Oracle Communications Data Model, you must write your own source-ETL scripts using Oracle Warehouse Builder or another ETL tool or mapping tool.
Oracle By Example:
See the following OBE tutorials for more information on Oracle Warehouse Builder:"Setting Up the Oracle Warehouse Builder 11g Release 2 Environment"
"Improved User Interface, Usability, and Productivity With Oracle Warehouse Builder 11g R2"
"Using Data Transformation Operators with Source and Target Operators"
"Working with Pluggable Mappings"
"Examining Source Data Using Data Profiling with Database 11g Release 2"
To access the tutorials, open the Oracle Learning Library in your browser by following the instructions in "Oracle Technology Network"; and, then, search for the tutorials by name.
The following topics provide general information about writing source-ETL:
ETL Architecture for Oracle Communications Data Model Source-ETL
Creating a Source to Target Mapping Document for the Source-ETL
Designing a Plan for Rectifying Source-ETL Data Quality Problems
Keep the following points in mind when designing and writing source-ETL for Oracle Communications Data Model:
You can populate the calendar data by using the calendar population scripts provided with Oracle Communications Data Model and described in Oracle Communications Data Model Reference.
Populate the tables in the following order:
Lookup tables
Reference tables
Base tables
Analyze the tables in one category before loading the tables in the next category (for example, analyze the reference tables before loading the lookup tables). Additionally, you must analyze all of the tables loaded by the source-ETL process before executing the intra-ETL processes).
See:
The topic about analyzing tables, indexes and clusters in Oracle Database Administrator's Guide.ETL first extracts data from the original sources, assures the quality of the data, cleans the data, and makes the data consistent across the original sources. ETL then populates the physical objects with the "clean" data so that query tools, report writers, dashboards and so on can access the data.
The fundamental services upon which data acquisition is constructed are as follows:
Data sourcing
Data movement
Data transformation
Data loading
From a logical architecture perspective, there are many different ways to configure these building blocks for delivering data acquisition services. The major architectural styles available that cover a range of options to be targeted within a data warehousing architecture include:
Batch Extract, Transform, and Load and Batch Extract, Load, Transform, Load
Batch Extract, Transform and Load (ETL) and Batch Extract, Load, Transform, Load (ELTL) are the traditional architecture's in a data warehouse implementation. The difference between them is where the transformation proceed in or out database.
Batch Hybrid Extract, Transform, Load, Transform, Load
Batch Hybrid Extract, Transform, Load, Transform, Load (ETLTL) is a hybrid strategy. This strategy provides the most flexibility to remove hand coding approaches to transformation design, apply a metadata-driven approach, and still be able to leverage the data processing capabilities of the enterprise warehouse. In this targeted design, the transformation processing is first performed outside the warehouse as a pre-processing step before loading the staging tables, and then further transformation processing is performed within the data warehouse before the final load into the target tables.
Real-time Extract, Transform, Load
Real-time Extract, Transform, Load (rETL) is appropriate when service levels for data freshness demand more up-to-date information in the data warehousing environment. In this approach, the OLTP system must actively publish events of interest so that the rETL processes can extract them from a message bus (queue) on a timely basis. A message-based paradigm is used with publish and subscribe message bus structures or point-to-point messaging with reliable queues.
When designing source-ETL for Oracle Communications Data Model, use the architecture that best meets your business needs.
Before you begin building your extract systems, create a logical data interface document that maps the relationship between original source fields and target destination fields in the tables. This document ties the very beginning of the ETL system to the very end.
Columns in the data mapping document are sometimes combined. For example, the source database, table name, and column name could be combined into a single target column. The information within the concatenated column would be delimited with a period. Regardless of the format, the content of the logical data mapping document has been proven to be the critical element required to sufficiently plan ETL processes.
Data cleaning consists of all the steps required to clean and validate the data feeding a table and to apply known business rules to make the data consistent. The perspectives of the cleaning and conforming steps are less about the upside potential of the data and more about containment and control.
If there are data quality problems, then build a plan, in agreement with IT and business users, for how to rectify these problems.
Answer the following questions:
Is data missing?
Is the data wrong or inconsistent?
Should the problem be fixed in the source systems?
Set up the data quality reporting and action program and people responsibility.
Set up the following processes and programs:
Set up a data quality measurement process.
Set up the data quality reporting and action program and people responsibility.
All data movement among ETL processes are composed of jobs. An ETL workflow executes these jobs in the proper sequence and with regard to the necessary dependencies. General ETL tools, such as Oracle Warehouse Builder, support this kind of workflow, job design, and execution control.
Below are some tips when you design ETL jobs and workflow:
Use common structure across all jobs (source system to transformer to target data warehouse).
Have a one-to-one mapping from source to target.
Define one job per Source table.
Apply generic job structure and template jobs to allow for rapid development and consistency.
Use an optimized job design to leverage Oracle load performance based on data volumes.
Design parameterized job to allow for greater control over job performance and behavior.
Maximize Jobs parallelism execution.
Your ETL tool or your developed mapping scripts generate status and error handling tables.
As a general principle, all ETL logs status and errors into a table. You monitor execution status using an ETL tool or by querying this log table directly.
Whether you are developing mapping scripts and loading into a staging layer or directly into the foundation layer the goal is to get the data into the warehouse in the most expedient manner. In order to achieve good performance during the load you must begin by focusing on where the data to be loaded resides and how you load it into the database. For example, you should not use a serial database link or a single JDBC connection to move large volumes of data. The most common and preferred mechanism for loading large volumes of data is loading from flat files.
The following topics discuss best practices for ensuring your source-ETL loads efficiently:
The area where flat files are stored before being loaded into the staging layer of a data warehouse system is commonly known as staging area. The overall speed of your load is determined by:
How quickly the raw data can be read from staging area.
How quickly the raw data can be processed and inserted into the database.
Recommendations: Using a Staging Area
Stage the raw data across as many physical disks as possible to ensure that reading it is not a bottleneck during the load.
Also, if you are using the Exadata Database Machine, the best place to stage the data is in an Oracle Database File System (DBFS) stored on the Exadata storage cells. DBFS creates a mountable cluster file system which can you can use to access files stored in the database. Create the DBFS in a separate database on the Database Machine. This allows the DBFS to be managed and maintained separately from the data warehouse.
Mount the file system using the DIRECT_IO option to avoid thrashing the system page cache while moving the raw data files in and out of the file system.
See:
Oracle Database SecureFiles and Large Objects Developer's Guide for more information on setting up DBFS.In order to parallelize the data load Oracle Database must be able to logically break up the raw data files into chunks, known as granules. To ensure balanced parallel processing, the number of granules is typically much higher than the number of parallel server processes. At any given point in time, a parallel server process is allocated one granule to work on. After a parallel server process completes working on its granule, another granule is allocated until all of the granules are processed and the data is loaded.
Recommendations: Preparing Raw Data Files for Source-ETL
Follow these recommendations:
Deliminate each row using a known character such as a new line or a semicolon. This ensures that Oracle can look inside the raw data file and determine where each row of data begins and ends in order to create multiple granules within a single file.
If a file is not position-able and seek-able (for example the file is compressed or zip file), then the files cannot be broken up into granules and the whole file is treated as a single granule. In this case, only one parallel server process can work on the entire file. In order to parallelize the loading of compressed data files, use multiple compressed data files. The number of compressed data files used determines the maximum parallel degree used by the load.
When loading multiple data files (compressed or uncompressed):
Use a single external table, if at all possible
Make the files similar in size
Make the size of the files a multiple of 10 MB
If you must have files of different sizes, list the files from largest to smallest. By default, Oracle assumes that the flat file has the same character set as the database. If this is not the case, specify the character set of the flat file in the external table definition to ensure the proper character set conversions can take place.
Oracle offers several data loading options
External table or SQL*Loader
Oracle Data Pump (import and export)
Change Data Capture and Trickle feed mechanisms (such as Oracle GoldenGate)
Oracle Database Gateways to open systems and mainframes
Generic Connectivity (ODBC and JDBC)
The approach that you take depends on the source and format of the data you receive.
Recommendations: Loading Flat Files
If you are loading from files into Oracle you have two options: SQL*Loader or external tables.
Using external tables offers the following advantages:
Allows transparent parallelization inside the database.You can avoid staging data and apply transformations directly on the file data using arbitrary SQL or PL/SQL constructs when accessing external tables. SQL Loader requires you to load the data as-is into the database first.
Parallelizing loads with external tables enables a more efficient space management compared to SQL*Loader, where each individual parallel loader is an independent database sessions with its own transaction. For highly partitioned tables this could potentially lead to a lot of wasted space.
You can create an external table using the standard CREATE TABLE statement. However, to load from flat files the statement must include information about where the flat files reside outside the database. The most common approach when loading data from an external table is to issue a CREATE TABLE AS SELECT (CTAS) statement or an INSERT AS SELECT (IAS) statement into an existing table.
A direct path load parses the input data according to the description given in the external table definition, converts the data for each input field to its corresponding Oracle data type, then builds a column array structure for the data. These column array structures are used to format Oracle data blocks and build index keys. The newly formatted database blocks are then written directly to the database, bypassing the standard SQL processing engine and the database buffer cache.
The key to good load performance is to use direct path loads wherever possible:
A CREATE TABLE AS SELECT (CTAS) statement always uses direct path load.
A simple INSERT AS SELECT (IAS) statement does not use direct path load. In order to achieve direct path load with an IAS statement you must add the APPEND hint to the command.
Direct path loads can also run in parallel. To set the parallel degree for a direct path load, either:
Add the PARALLEL hint to the CTAS statement or an IAS statement.
Set the PARALLEL clause on both the external table and the table into which the data is loaded.
After the parallel degree is set:
A CTAS statement automatically performs a direct path load in parallel.
An IAS statement does not automatically perform a direct path load in parallel. In order to enable an IAS statement to perform direct path load in parallel, you must alter the session to enable parallel DML by executing the following statement.
alter session enable parallel DML;
A benefit of partitioning is the ability to load data quickly and easily with minimal impact on the business users by using the EXCHANGE PARTITION command. The EXCHANGE PARTITION command enables swapping the data in a nonpartitioned table into a particular partition in your partitioned table. The EXCHANGE PARTITION command does not physically move data, instead it updates the data dictionary to exchange a pointer from the partition to the table and vice versa.
Because there is no physical movement of data, an exchange does not generate redo and undo. In other words, an exchange is a sub-second operation and far less likely to impact performance than any traditional data-movement approaches such as INSERT.
Recommendations: Partitioning Tables
Partition the larger tables and fact tables in the Oracle Communications Data Model warehouse.
Example 4-1 Using Exchange Partition Statement with a Partitioned Table
Assume that there is a large table called Sales, which is range partitioned by day. At the end of each business day, data from the online sales system is loaded into the Sales table in the warehouse.
The following steps ensure the daily data gets loaded into the correct partition with minimal impact to the business users of the data warehouse and optimal speed:
Create external table for the flat file data coming from the online system
Using a CTAS statement, create a nonpartitioned table called tmp_sales that has the same column structure as Sales table
Build any indexes that are on the Sales table on the tmp_sales table
Issue the EXCHANGE PARTITION command.
Alter table Sales exchange partition p2 with
table top_sales including indexes without validation;
Gather optimizer statistics on the newly exchanged partition using incremental statistics.
The EXCHANGE PARTITION command in this example, swaps the definitions of the named partition and the tmp_sales table, so the data instantaneously exists in the right place in the partitioned table. Moreover, with the inclusion of the INCLUDING INDEXES and WITHOUT VALIDATION clauses, Oracle swaps index definitions and does not check whether the data actually belongs in the partition - so the exchange is very quick.
Note:
The assumption being made in this example is that the data integrity was verified at date extraction time. If you are unsure about the data integrity, omit theWITHOUT VALIDATION clause so that the Database checks the validity of the data.The Oracle Communications Data Model supports the use of ETL tools such as Oracle Warehouse Builder to define the workflow to execute the intra-ETL process. You can, of course, write your own intra-ETL. However, an intra-ETL component is delivered with Oracle Communications Data Model that is a process flow designed using the Oracle Warehouse Builder Workflow component. This process flow is named INTRA_ETL_FLW.
As illustrated by Figure 4-1, "ETL Flow Diagram", the INTRA_ETL_FLW process flow uses the data in the Oracle Communications Data Model base, reference, and lookup tables to populate all of the other Oracle Communications Data Model structures. Within this package the dependency of each individual program is implemented and enforced so that each program executes in the proper order.
You can change the original intra-ETL script for your specific requirements. However, perform a complete impact analysis before you make the change. Package the changes as a patch to the original Oracle Communications Data Model intra-ETL mapping.
The INTRA_ETL_FLW process flow consists of the following subprocesses and includes the dependency of individual sub-process flows and executes them in the proper order:
DRVD_FLW
This sub-process flow contains all the Oracle Warehouse Builder mappings for populating derived tables based on the content of the base, reference, and lookup tables. This process flow allows mappings to be executed concurrently.
This sub-process uses the following technologies:
MERGE clause. This statement is used for initial load and for incremental load. It determines if the data to be inserted or updated into target table based on checking key columns with incoming data and provides a much superior performance compared to an INSERT and UPDATE combination.
TABLE function. This function is used mainly for derived tables (and some source data) in order to avoid needing a separate staging table. The absence of a staging table provides a performance boost in the ETL operation and simplifies database maintenance
Pipeline clause. This clause is used in the TABLE function for incrementally returning the result set for further processing as soon as they are created. Therefore, the use of this clause avoids bulk return which makes the complete process much faster than using a normal return.
AGGR_FLW
This sub-process flow contains PL/SQL code that uses the partitions change tracking strategy to refresh all the aggregate tables which are materialized views in the Oracle Communications Data Model.
This subprocess uses the following technologies:
Materialized View. A materialized view is used to hold the aggregation data. Whenever this is refreshed then the modified data get reflected in the corresponding aggregate table and this leads to a significant increase in the query execution performance. Moreover usage of materialized view allows Oracle Communications Data Model to make use of the Oracle Query Rewrite feature for better SQL optimization and hence improved performance.
FAST Refresh. This refresh type is used to refresh the aggregates with only the incremental data (inserted and modified) in base and derived tables after the immediately previous refresh and this incremental refresh leads to much better performance and hence shorter intra-ETL window.
MINING_FLW
This sub-process flow triggers the data mining model refresh.
The INTRA_ETL_FLW process flow also includes the OLAP_MAP mapping. OLAP_MAP invokes the analytic workspace build function of the PKG_OCDM_OLAP_ETL_AW_LOAD package to load data from Oracle Communications Data Model aggregate materialized views into the Oracle Communications Data Model analytical workspace and calculates the forecast data. The PKG_OCDM_OLAP_ETL_AW_LOAD package reads OLAP ETL parameters from the DWC_OLAP_ETL_PARAMETER control table in the ocdm_sys schema to determine the specifics of how to load the data and perform the forecasts.
Note:
The shell scriptocdm_execute_wf.sh delivered with Oracle Communications Data Model performs the same function as Oracle Warehouse Builder Workflow INTRA_ETL_FLW. This shell script does not require Oracle Warehouse Builder workflow. For more information about working with this script, see "Manually Executing the ocdm_execute_wf.sh Script".See:
Oracle Communications Data Model Reference for detailed information about the Oracle Communications Data Model intra-ETL.Performing an initial load of an Oracle Communications Data Model is a multistep process:
Load the foundation layer of the Oracle Communications Data Model warehouse (that is, the reference, lookup, and base tables) as described in "Performing an Initial Load of the Foundation Layer".
Load the access layer of the Oracle Communications Data Model warehouse (that is, the derived and aggregate tables, materialized views, OLAP cubes, and data mining models) as described in "Performing an Initial Load of the Access Layer".
The manner in which you perform an initial load of the foundation layer of an Oracle Communications Data Model warehouse (that is, the reference, lookup, and base tables) varies depending on whether or not you are using an application adapter for Oracle Communications Data Model:
If you are using an application adapter for Oracle Communications Data Model, then you use that adapter to load the foundation layer. For example, you can use the NCC Adapter for Oracle Communications Data Model to populate the foundation layer of an Oracle Communications Data Model warehouse with data from an Oracle Communications Network Charging and Control system as described in "Initial Loading Using the NCC Adapter for Oracle Communications Data Model".
If you are not using an application adapter for, then you perform the initial load of the foundation layer using source-ETL that you create. See "Writing Your Own Source-ETL" for more information on creating this ETL.
To perform an initial load of access layer of the Oracle Communications Data Model warehouse (that is, the derived and aggregate tables, materialized views, OLAP cubes, and data mining models) take the following steps:
Update the parameters in DWC_ETL_PARAMETER control table in the ocdm_sys schema so that the ETL can use this information (that is, the beginning and end date of the ETL period) when loading the derived and aggregate tables and views.
For an initial load of an Oracle Communications Data Model warehouse, specify the values shown in the following table.
| Columns | Value |
|---|---|
PROCESS_NAME |
'OCDM-INTRA-ETL' |
FROM_DATE_ETL |
The beginning date of the ETL period. |
TO_DATE_ETL |
The ending date of the ETL period. |
See:
Oracle Communications Data Model Reference for more information on theDWC_ETL_PARAMETER control table.Update the Oracle Communications Data Model OLAP ETL parameters in DWC_OLAP_ETL_PARAMETER control table in the ocdm_sys schema to specify the build method and other build characteristics so that the ETL can use this information when loading the OLAP cube data.
For an initial load of the analytic workspace, specify values following the guidelines in Table 4-1.
Table 4-1 Values of Oracle Communications Data Model OLAP ETL Parameters in the DWC_OLAP_ETL_PARAMETER Table for Initial Load
| Column Name | Value |
|---|---|
|
|
|
|
|
|
|
|
One of the following values that specifies the cubes you want to build:
|
|
|
A decimal value that specifies the number of parallel processes to allocate to this job. (Default value is |
|
|
One of the following values depending on whether you want to calculate forecast cubes:
|
|
|
If the value for the |
|
|
If the value for the |
|
|
If the value for the |
|
|
If the value for the |
|
|
Specify |
|
|
Specify |
Execute the intra-ETL in one of the ways described in "Executing the Default Oracle Communications Data Model Intra-ETL ".
You can execute the intra-ETL packages provided with Oracle Communications Data Model in the following ways:
As a Workflow within Oracle Warehouse Builder as described in "Executing the INTRA_ETL_FLW Workflow from Oracle Warehouse Builder".
Without using Oracle Warehouse Builder Workflow as described in "Manually Executing the ocdm_execute_wf.sh Script".
In either case, you can execute the intra-ETL explicitly or invoke its execution in some other program or process (for example, the source-ETL process after its successful execution) or through a predefined schedule (for example, using Oracle Job Scheduling feature and so on).
See:
"Monitoring the Execution of the Intra-ETL Process", "Recovering an Intra ETL Process", and "Troubleshooting Intra-ETL Performance".You can execute the INTRA_ETL_FLW process from within Oracle Warehouse Builder after you deploy it.
To deploy the INTRA_ETL_FLW process flow, take the following steps:
Confirm that Oracle Warehouse Builder Workflow has been installed as described in Oracle Communications Data Model Installation Guide.
Within Oracle Warehouse Builder, go to the Control Center Manager.
Select OLAP_PFLW, then select AGR_PFLW, then select the main process flow INTRA_ETL_FLW.
Right-click INTRA_ETL_FLW and select set action.
If this is the first deployment, set action to Create.
If this is a later deployment, set action to Replace.
Deploy the process flow.
After the deployment finishes successfully, INTRA_ETL_FLW is ready to execute.
See:
Oracle Warehouse Builder Sources and Targets Guide for information about Oracle Warehouse Builder.Oracle Communications Data Model provides a script that you can use to populate the intra-ETL without using an Oracle Warehouse Builder Workflow. This shell script is named ocdm_execute_wf.sh .
The ocdm_execute_wf.sh script performs the same function as Oracle Warehouse Builder Workflow INTRA_ETL_FLW. The script can be invoked by another process such as source-ETL, or according to a predefined schedule such as Oracle Job Scheduling.
The ocdm_execute_wf.sh program prompts you to enter the environmental variables described in the following table.
| Variable | Description |
|---|---|
TSNAME |
The tnsname of target database. |
SYSTEM password |
SYSTEM account password of target database. |
ocdm_sys password |
The password of the ocdm_sys account. |
ORACLE HOME |
Oracle Database home (that is, the full path without ending "/"). |
Reads the values from the DWC_ETL_PARAMETER and DWC_OLAP_ETL_PARAMETER control tables in the ocdm_sys schema before executing the mappings in the correct order
The result of each table loading are tracked in the DWC_INTRA_ETL_PROCESS and DWC_INTRA_ETL_ACTIVITY control tables as described in "Monitoring the Execution of the Intra-ETL Process".
"Performing an Initial Load of the Access Layer" describes how to perform an initial load of an Oracle Communications Data Model data warehouse. After this initial load, you must load new data into your Oracle Communications Data Model data warehouse regularly so that it can serve its purpose of facilitating business analysis.
To load new data into your Oracle Communications Data Model warehouse, you extract the data from one or more operational systems and copy that data into the warehouse. The challenge in data warehouse environments is to integrate, rearrange and consolidate large volumes of data over many systems, thereby providing a new unified information base for business intelligence.
The successive loads and transformations must be scheduled and processed in a specific order that is determined by your business needs. Depending on the success or failure of the operation or parts of it, the result must be tracked and subsequent, alternative processes might be started.
You can do a full incremental load of the Oracle Communications Data Model warehouse, or you can refresh the data sequentially, as follows:
Refreshing the Foundation Layer of Oracle Communications Data Model Warehouse
Refreshing the Access Layer of an Oracle Communications Data Model Warehouse
In either case, you can manage errors during the execution of the intra-ETL as described in "Managing Errors During Oracle Communications Data Model Intra-ETL Execution".
You can refresh the foundation layer of an Oracle Communications Data Model warehouse (that is, the reference, lookup, and base tables) in the following ways:
If an application adapter for Oracle Communications Data Model is available for the system from which you want to refresh the foundation layer of an Oracle Communications Data Model warehouse, you can use that adapter to refresh the foundation layer.
For example, you can use the NCC Adapter for Oracle Communications Data Model to refresh the foundation layer of an Oracle Communications Data Model warehouse with data from an Oracle Communications Network Charging and Control system as described in "Refreshing the Data Using the NCC Adapter for Oracle Communications Data Model".
You can refresh the foundation layer using source-ETL scripts that you wrote using Oracle Warehouse Builder or another ETL tool. For more information on creating source-ETL, see "Writing Your Own Source-ETL".
Refreshing the access layer of an Oracle Communications Data Model is a multi-step process. You can do a full incremental load of the access layer all at one time, or you can refresh the data sequentially, as follows:
Refreshing Oracle Communications Data Model Derived and Aggregate Tables
Refreshing Oracle Communications Data Model Data Mining Models
In either case, you can manage errors during the execution of the intra-ETL as described in "Managing Errors During Oracle Communications Data Model Intra-ETL Execution".
Refreshing the relational tables and views in an Oracle Communications Data Model is a multi-step process:
Refresh the foundation layer of the Oracle Communications Data Model warehouse (that is, the reference, lookup, and base tables) with OLTP data by executing the source-ETL that you have written.
Update the parameters of the DWC_ETL_PARAMETER control table in the ocdm_sys schema. For an incremental load of an Oracle Communications Data Model warehouse, specify the values shown in the following table (that is, the beginning and end date of the ETL period).
| Columns | Value |
|---|---|
PROCESS_NAME |
'OCDM-INTRA-ETL' |
FROM_DATE_ETL |
The beginning date of the ETL period. |
TO_DATE_ETL |
The ending date of the ETL period. |
See:
Oracle Communications Data Model Reference for more information on theDWC_ETL_PARAMETER control table.Refresh the derived tables and aggregate tables which are materialized views in Oracle Communications Data Model by executing the DRVD_FLOW and AGGR_FLOW subprocess of the INTRA_ETL_FLW process flow. See "Executing the Default Oracle Communications Data Model Intra-ETL " for more information.
See also:
Oracle Warehouse Builder Sources and Targets GuideOn a scheduled basis you must update the OLAP cube data with the relational data that has been added to the Oracle Communications Data Model data warehouse since the initial load of the OLAP cubes.
You can execute the Oracle Communications Data Model ETL to update the OLAP cubes in the following ways
Refresh all of the data in the warehouse by executing the Oracle Warehouse Builder Workflow INTRA_ETL_FLW in one of the ways that are described in "Executing the Default Oracle Communications Data Model Intra-ETL ".
The OLAP Cubes are populated through OLAP_MAP which is a part of Oracle Communications Data Model intra-ETL main workflow INTRA_ETL_FLW.
Refresh only the OLAP cube data by executing the OLAP_MAP Oracle Warehouse Builder mapping in the Oracle Warehouse Builder control center.
Note:
You must refresh the corresponding materialized view of the OLAP cubes you are refreshing before you executeOLAP_MAP. (For the mapping between OLAP cube and materialized views, refer to Oracle Communications Data Model Reference.Take these steps to perform an incremental load of the analytic workspace that is part of the Oracle Communications Data Model warehouse:
Update the aggregate tables which are materialized views in Oracle Communications Data Model. See "Refreshing Oracle Communications Data Model Derived and Aggregate Tables" for more information.
Execute the intra-ETL to load the cube data in one of the ways described in "Executing the Default Oracle Communications Data Model Intra-ETL ".
If necessary, to recover from errors during the execution of OLAP_MAP take the following steps.
Change the value of the BUILD_METHOD column of the ocdm_sys.DWC_OLAP_ETL_PARAMETER table to "C".
In Oracle Warehouse Builder, rerun the OLAP_MAP map.
The MINING_FLW sub-process flow of the INTRA_ETL_FLW process flow triggers the data mining model refreshment. After the initial load of the warehouse, it is recommended to refresh the data mining models monthly. Refreshing the data models is integrated into the MINING_FLW sub-process flow. You can also manually refresh the data models.
The way you refresh a data mining model varies depending on whether you want to refresh all of the models or only one model:
To manually refresh all mining models, call the following procedure.
ocdm_mining.PKG_ocdm_mining.REFRESH_MODEL( MONTH_CODE,P_PROCESS_NO)
This procedure performs the following tasks for each model:
Refreshes the mining source materialized views based on the latest data from ocdm_sys schema.
Trains each model on the new training data.
Applies each model onto the new apply data set.
To manually re-create only one mining model, you can call the corresponding procedure. For example, to re-create the churn SVM model, you can call the following procedure.
ocdm_mining.create_churn_svm_model( MONTH_CODE );
"Tutorial: Customizing the Churn Prediction Model" provides detailed instructions for refreshing a single data mining model.
This topic discusses how you can identify and manage errors during intra-ETL execution. It contains the following topics:
Two ocdm_sys schema control tables, DWC_INTRA_ETL_PROCESS and DWC_INTRA_ETL_ACTIVITY, monitor the execution of the intra-ETL process. These tables are documented in Oracle Communications Data Model Reference.
Each normal run (as opposed to an error-recovery run) of a separate intra-ETL execution performs the following steps:
Inserts a record into the DWC_INTRA_ETL_PROCESS table with a monotonically increasing system generated unique process key, SYSDATE as process start time, RUNNING as the process status, and an input date range in the FROM_DATE_ETL and TO_DATE_ETL columns.
Invokes each of the individual intra-ETL programs in the appropriate order of dependency. Before the invocation of each program, the procedure inserts a record into the intra-ETL Activity detail table, DWC_INTRA_ETL_ACTIVITY, with values for:
ACTIVITY_KEY, a system generated unique activity key.
PROCESS_KEY, the process key value corresponding to the intra-ETL process.
ACTIVITY_NAME, an individual program name.
ACTIVITY_DESC, a suitable activity description.
ACTIVITY_START_TIME, the value of SYSDATE.
ACTIVITY_STATUS, the value of RUNNING.
Updates the corresponding record in the DWC_INTRA_ETL_ACTIVITY table for the activity end time and activity status after the completion of each individual ETL program (either successfully or with errors). For successful completion of the activity, the procedure updates the status as 'COMPLETED-SUCCESS'. When an error occurs, the procedure updates the activity status as 'COMPLETED-ERROR', and also updates the corresponding error detail in the ERROR_DTL column.
Updates the record corresponding to the process in the DWC_INTRA_ETL_ PROCESS table for the process end time and status, after the completion of all individual intra-ETL programs. When all the individual programs succeed, the procedure updates the status to 'COMPLETED-SUCCESS', otherwise it updates the status to 'COMPLETED-ERROR'.
You can monitor the execution state of the intra-ETL, including current process progress, time taken by individual programs, or the complete process, by viewing the contents of the DWC_INTRA_ETL_PROCESS and DWC_INTRA_ETL_ACTIVITY tables corresponding to the maximum process key. Monitoring can be done both during and after the execution of the intra-ETL procedure.
To recover an intra-ETL process
Identify the errors by looking at the corresponding error details that are tracked against the individual programs in the DWC_INTRA_ETL_ACTIVITY table.
Correct the causes of the errors.
Re-invoke the intra-ETL process.
The INTRA_ETL_FLW process identifies whether it is a normal run or recovery run by referring the DWC_INTRA_ETL_ACTIVITY table. During a recovery run, INTRA_ETL_FLW executes only the necessary programs. For example, in the case of a derived population error as a part of the previous run, this recovery run executes the individual derived population programs which produced errors in the previous run. After their successful completion, the run executes the aggregate population programs and materialized view refresh in the appropriate order.
In this way, the intra-ETL error recovery is almost transparent, without involving the data warehouse or ETL administrator. The administrator must only correct the causes of the errors and re-invoke the intra-ETL process. The intra-ETL process identifies and executes the programs that generated errors.
To troubleshoot the performance of the intra-ETL:
Check the execution plan as described in "Checking the Execution Plan".
Monitor parallel DML executions as described in "Monitoring PARALLEL DML Executions".
Check that data mining models were created correctly as described in "Troubleshooting Data Mining Model Creation".
Use SQLDeveloper or other tools to view the package body of the code generated by Oracle Warehouse Builder.
For example, take the following steps to examine a map:
Copy out the main query statement from code viewer.
Copy from "CURSOR "AGGREGATOR_c" IS …." to end of the query, which is right above another "CURSOR "AGGREGATOR_c$1" IS".
In SQLDeveloper worksheet, issue the following statement to turn on the parallel DML:
Alter session enable parallel dml;
Paste the main query statement into another SQL Developer worksheet and view the execution plan by clicking F6.
Carefully examine the execution plan to make the mapping runs according to a valid plan.
Check that you are running mapping in parallel mode by executing the following SQL statement to count the executed "Parallel DML/Query" statement
column name format a50 column value format 999,999 SELECT NAME, VALUE FROM GV$SYSSTAT WHERE UPPER (NAME) LIKE '%PARALLEL OPERATIONS%' OR UPPER (NAME) LIKE '%PARALLELIZED%' OR UPPER (NAME) LIKE '%PX%' ;
If you run mapping in parallel mode, you should see "DML statements parallelized" increased by 1 (one) every time the mapping was invoked. If not, you do not see this increase, then the mapping was not invoked as "parallel DML".
If you see "queries parallelized" increased by 1 (one) instead, then typically it means that the SELECT statement inside of the INSERT was parallelized, but that INSERT itself was not parallelized.
After the data mining models are created, check the error log in ocdm_sys.dwc_intra_etl_activity table. For example, execute the following code.
set line 160 col ACTIVITY_NAME format a30 col ACTIVITY_STATUS format a20 col error_dtl format a80 select activity_name, activity_status, error_dtl from dwc_intra_etl_activity;
If all models are created successfully, the activity_status is all "COMPLETED-SUCCESS". If the activity_status is "COMPLETED-ERROR" for a certain step, check the ERROR_DTL column, and fix the problem accordingly.
The following examples illustrate how to troubleshoot some common error messages returned in ERROR_DTL and ACTIVITY_NAME when working with Oracle Communications Data Model:
Example 4-2, "Troubleshooting an ORA-20991 Error for Oracle Communications Data Model"
Example 4-3, "Troubleshooting the "Message not available ... [Language=ZHS]" Error"
Example 4-4, "Troubleshooting an ORA-40113 Error for Oracle Communications Data Model"
Example 4-5, "Troubleshooting an ORA-40112 Error for Oracle Communications Data Model"
Example 4-6, "Troubleshooting an ORG-11130 Error for Oracle Communications Data Model"
Example 4-2 Troubleshooting an ORA-20991 Error for Oracle Communications Data Model
Assume that the returned error is ORA-20991: Message not available ... [Language=ZHS]CURRENT_MONTH_KEY.
This error may happen when there is not enough data in the DWR_BSNS_MO table. For example, if the calendar data is populated with 2004~2009 data, the mining model refresh for Year 2010 may result in this error.
To fix this error, execute the Oracle Communications Data Model calendar utility script again to populate the calendar with sufficient data. For example:
Execute Calendar_Population.run('2005-01-01',10);
See Oracle Communications Data Model Reference for information on the calendar population utility script.
Example 4-3 Troubleshooting the "Message not available ... [Language=ZHS]" Error
Assume that the returned error is Message not available ... [Language=ZHS].
'ZHS' is a code for a language. The language name it relates to can appear as different name depending on the database environment. This error happens when ocdm_sys.DWC_MESSAGE.LANGUAGE does not contain messages for the current language.
Check the values in the DWC_MESSAGE table and, if required, update to the language code specified by the Oracle session variable USERENV('lang').
Example 4-4 Troubleshooting an ORA-40113 Error for Oracle Communications Data Model
Assume that the returned error is ORA-40113: insufficient number of distinct target values, for 'create_churn_svm_model.
This error happens when the target column for the training model contains only one value or no value when it is expecting more than one value.
For example, for the churn_svm_model, the target column is:
ocdm_mining.DMV_CUST_CHRN_SRC_PRD.chrn_ind
To troubleshoot this error:
Execute a SQL query to check if there are enough values in this column.
Using the churn_svm_model as an example, issue the following statement.
select chrn_ind, count(*) from DMV_CUST_CHRN_SRC_PRD group by chrn_ind;
The following is a result of the query.
C COUNT(*) - ---------- 1 1228 0 4911
Check the following tables to ensure customer churn indicators are set properly:
ocdm_sys.dwr_cust.chrn_dt should contain the value for the churned customers.
ocdm_sys.dwd_acct_sttstc should contain the correct value for each customer in the most recent six months.
Execute the following statement to refresh the mining source materialized views in the ocdm_mining schema:
exec pkg_ocdm_mining.refresh_mining_source;
Example 4-5 Troubleshooting an ORA-40112 Error for Oracle Communications Data Model
Assume that the returned error is ORA-40112:insufficient number of valid data rows, for "create_ltv_glmr_model"
For this model, the target column is ocdm_mining.DMV_CUST_LTV_PRDCT_SRC.TOT_PYMT_RVN.
To troubleshoot this error:
Execute the following SQL statement:
select count(TOT_PYMT_RVN) from DMV_CUST_LTV_PRDCT_SRC;
Check to see that the value returned by this query is greater than 0 (zero) and similar to number of customers. If the number is 0 or too small, check the Oracle Communications Data Model intra-ETL execution status as described in "Monitoring PARALLEL DML Executions".
Example 4-6 Troubleshooting an ORG-11130 Error for Oracle Communications Data Model
Assume that the returned error is ORG-11130:no data found in the collection, for "create_sentiment_svm_model".
This error occurs when there is not enough data in the source table for Text sentiment model training: ocdm_mining.dm_cust_cmmnt.
To ensure that some text is loaded for customer sentiment analysis:
Issue the following SQL statement.
Select OVRAL_RSLT_CD, count(CUST_COMMENT) from DWB_EVT_PRTY_INTRACN group by OVRAL_RSLT_CD;
Check the number of text comments from the customer interaction table DWB_EVT_PRTY_INTRACN.
If there is not enough data in the customer interaction table, check the ETL logic from the source system to the Oracle Communications Data Model.
|
Copyright © 2011, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|