| Oracle® Database PL/SQL Language Reference 11g Release 2 (11.2) Part Number E25519-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Database PL/SQL Language Reference 11g Release 2 (11.2) Part Number E25519-05 |
|
|
PDF · Mobi · ePub |
A composite data type stores values that have internal components. You can pass entire composite variables to subprograms as parameters, and you can access internal components of composite variables individually. Internal components can be either scalar or composite. You can use scalar components wherever you can use scalar variables. PL/SQL lets you define two kinds of composite data types, collection and record. You can use composite components wherever you can use composite variables of the same type.
Note:
If you pass a composite variable as a parameter to a remote subprogram, then you must create a redundant loop-backDATABASE LINK, so that when the remote subprogram compiles, the type checker that verifies the source uses the same definition of the user-defined composite variable type as the invoker uses. For information about the CREATE DATABASE LINK statement, see Oracle Database SQL Language Reference.In a collection, the internal components always have the same data type, and are called elements. You can access each element of a collection variable by its unique index, with this syntax: variable_name(index). To create a collection variable, you either define a collection type and then create a variable of that type or use %TYPE.
In a record, the internal components can have different data types, and are called fields. You can access each field of a record variable by its name, with this syntax: variable_name.field_name. To create a record variable, you either define a RECORD type and then create a variable of that type or use %ROWTYPE or %TYPE.
You can create a collection of records, and a record that contains collections.
See Also:
"BULK COLLECT Clause" for information about retrieving query results into a collection
"Collection Variable Declaration" for syntax and semantics of collection type definition and collection variable declaration
Note:
Several examples in this chapter define procedures that print their composite variables. Several of those procedures invoke this standalone procedure, which prints either its integer parameter (if it is notNULL) or the string 'NULL':
CREATE OR REPLACE PROCEDURE print (n INTEGER) IS
BEGIN
IF n IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE(n);
ELSE
DBMS_OUTPUT.PUT_LINE('NULL');
END IF;
END print;
/
Some examples in this chapter define functions that return values of composite types.
You can understand the examples in this chapter without completely understanding PL/SQL procedures and functions, which are explained in Chapter 8, "PL/SQL Subprograms".
PL/SQL has three collection types—associative array, VARRAY (variable-size array), and nested table. Table 5-1 summarizes their similarities and differences.
Table 5-1 PL/SQL Collection Types
| Collection Type | Number of Elements |
Index Type | Dense or Sparse |
Uninitialized Status |
Where Defined |
Can Be ADT Attribute Data Type |
|---|---|---|---|---|---|---|
|
Unspecified |
String or |
Either |
Empty |
In PL/SQL block or package |
No |
|
|
Specified |
Integer |
Always dense |
Null |
In PL/SQL block or package or at schema level |
Only if defined at schema level |
|
|
Unspecified |
Integer |
Starts dense, can become sparse |
Null |
In PL/SQL block or package or at schema level |
Only if defined at schema level |
If the number of elements is specified, it is the maximum number of elements in the collection. If the number of elements is unspecified, the maximum number of elements in the collection is the upper limit of the index type.
A dense collection has no gaps between elements—every element between the first and last element is defined and has a value (the value can be NULL unless the element has a NOT NULL constraint). A sparse collection has gaps between elements.
An empty collection exists but has no elements. To add elements to an empty collection, invoke the EXTEND method (described in "EXTEND Collection Method").
A null collection (also called an atomically null collection) does not exist. To change a null collection to an existing collection, you must initialize it, either by making it empty or by assigning a non-NULL value to it (for details, see "Collection Constructors" and "Assigning Values to Collection Variables"). You cannot use the EXTEND method to initialize a null collection.
A collection type defined in a PL/SQL block is a local type. It is available only in the block, and is stored in the database only if the block is in a standalone or package subprogram. (Standalone and package subprograms are explained in "Nested, Package, and Standalone Subprograms".)
A collection type defined in a package specification is a public item. You can reference it from outside the package by qualifying it with the package name (package_name.type_name). It is stored in the database until you drop the package. (Packages are explained in Chapter 10, "PL/SQL Packages.")
A collection type defined at schema level is a standalone type. You create it with the "CREATE TYPE Statement". It is stored in the database until you drop it with the "DROP TYPE Statement".
Note:
A collection type defined in a package specification is incompatible with an identically defined local or standalone collection type (see Example 5-31 and Example 5-32).Can Be ADT Attribute Data Type
To be an ADT attribute data type, a collection type must be a standalone collection type. For other restrictions, see Restrictions on datatype.
Translating Non-PL/SQL Composite Types to PL/SQL Composite Types
If you have code or business logic that uses another language, you can usually translate the array and set types of that language directly to PL/SQL collection types. For example:
| Non-PL/SQL Composite Type | Equivalent PL/SQL Composite Type |
|---|---|
| Hash table | Associative array |
| Unordered table | Associative array |
| Set | Nested table |
| Bag | Nested table |
| Array | VARRAY |
See Also:
Oracle Database SQL Language Reference for information about theCAST function, which converts one SQL data type or collection-typed value into another SQL data type or collection-typed value.An associative array (formerly called PL/SQL table or index-by table) is a set of key-value pairs. Each key is a unique index, used to locate the associated value with the syntax variable_name(index).
The data type of index can be either a string type or PLS_INTEGER. Indexes are stored in sort order, not creation order. For string types, sort order is determined by the initialization parameters NLS_SORT and NLS_COMP.
Like a database table, an associative array:
Is empty (but not null) until you populate it
Can hold an unspecified number of elements, which you can access without knowing their positions
Unlike a database table, an associative array:
Does not need disk space or network operations
Cannot be manipulated with DML statements
Example 5-1 defines a type of associative array indexed by string, declares a variable of that type, populates the variable with three elements, changes the value of one element, and prints the values (in sort order, not creation order). (FIRST and NEXT are collection methods, described in "Collection Methods".)
Example 5-1 Associative Array Indexed by String
DECLARE
-- Associative array indexed by string:
TYPE population IS TABLE OF NUMBER -- Associative array type
INDEX BY VARCHAR2(64); -- indexed by string
city_population population; -- Associative array variable
i VARCHAR2(64); -- Scalar variable
BEGIN
-- Add elements (key-value pairs) to associative array:
city_population('Smallville') := 2000;
city_population('Midland') := 750000;
city_population('Megalopolis') := 1000000;
-- Change value associated with key 'Smallville':
city_population('Smallville') := 2001;
-- Print associative array:
i := city_population.FIRST; -- Get first element of array
WHILE i IS NOT NULL LOOP
DBMS_Output.PUT_LINE
('Population of ' || i || ' is ' || city_population(i));
i := city_population.NEXT(i); -- Get next element of array
END LOOP;
END;
/
Result:
Population of Megalopolis is 1000000 Population of Midland is 750000 Population of Smallville is 2001
Example 5-2 defines a type of associative array indexed by PLS_INTEGER and a function that returns an associative array of that type.
Example 5-2 Function Returns Associative Array Indexed by PLS_INTEGER
DECLARE TYPE sum_multiples IS TABLE OF PLS_INTEGER INDEX BY PLS_INTEGER; n PLS_INTEGER := 5; -- number of multiples to sum for display sn PLS_INTEGER := 10; -- number of multiples to sum m PLS_INTEGER := 3; -- multiple FUNCTION get_sum_multiples ( multiple IN PLS_INTEGER, num IN PLS_INTEGER ) RETURN sum_multiples IS s sum_multiples; BEGIN FOR i IN 1..num LOOP s(i) := multiple * ((i * (i + 1)) / 2); -- sum of multiples END LOOP; RETURN s; END get_sum_multiples; BEGIN DBMS_OUTPUT.PUT_LINE ( 'Sum of the first ' || TO_CHAR(n) || ' multiples of ' || TO_CHAR(m) || ' is ' || TO_CHAR(get_sum_multiples (m, sn)(n)) ); END; /
Result:
Sum of the first 5 multiples of 3 is 45
See Also:
Table 5-1 for a summary of associative array characteristics
"assoc_array_type_def ::=" for the syntax of an associative array type definition
When declaring an associative array constant, you must create a function that populates the associative array with its initial value and then invoke the function in the constant declaration, as in Example 5-3. (The function does for the associative array what a constructor does for a varray or nested table. For information about constructors, see "Collection Constructors".)
Example 5-3 Declaring Associative Array Constant
CREATE OR REPLACE PACKAGE My_Types AUTHID DEFINER IS TYPE My_AA IS TABLE OF VARCHAR2(20) INDEX BY PLS_INTEGER; FUNCTION Init_My_AA RETURN My_AA; END My_Types; / CREATE OR REPLACE PACKAGE BODY My_Types IS FUNCTION Init_My_AA RETURN My_AA IS Ret My_AA; BEGIN Ret(-10) := '-ten'; Ret(0) := 'zero'; Ret(1) := 'one'; Ret(2) := 'two'; Ret(3) := 'three'; Ret(4) := 'four'; Ret(9) := 'nine'; RETURN Ret; END Init_My_AA; END My_Types; / DECLARE v CONSTANT My_Types.My_AA := My_Types.Init_My_AA(); BEGIN DECLARE Idx PLS_INTEGER := v.FIRST(); BEGIN WHILE Idx IS NOT NULL LOOP DBMS_OUTPUT.PUT_LINE(TO_CHAR(Idx, '999')||LPAD(v(Idx), 7)); Idx := v.NEXT(Idx); END LOOP; END; END; /
Result:
-10 -ten 0 zero 1 one 2 two 3 three 4 four 9 nine PL/SQL procedure successfully completed.
National Language Support (NLS) parameters such as NLS_SORT, NLS_COMP, and NLS_DATE_FORMAT affect associative arrays indexed by string.
See Also:
Oracle Database Globalization Support Guide for information about linguistic sort parametersThe initialization parameters NLS_SORT and NLS_COMP determine the storage order of string indexes of an associative array. If you change the value of either parameter after populating an associative array indexed by string, then the collection methods FIRST, LAST, NEXT, and PRIOR (described in "Collection Methods") might return unexpected values or raise exceptions. If you must change these parameter values during your session, restore their original values before operating on associative arrays indexed by string.
In the declaration of an associative array indexed by string, the string type must be VARCHAR2 or one of its subtypes. However, you can populate the associative array with indexes of any data type that the TO_CHAR function can convert to VARCHAR2. (For information about TO_CHAR, see Oracle Database SQL Language Reference.)
If your indexes have data types other than VARCHAR2 and its subtypes, ensure that these indexes remain consistent and unique if the values of initialization parameters change. For example:
Do not use TO_CHAR(SYSDATE) as an index.
If the value of NLS_DATE_FORMAT changes, then the value of (TO_CHAR(SYSDATE)) might also change.
Do not use different NVARCHAR2 indexes that might be converted to the same VARCHAR2 value.
Do not use CHAR or VARCHAR2 indexes that differ only in case, accented characters, or punctuation characters.
If the value of NLS_SORT ends in _CI (case-insensitive comparisons) or _AI (accent- and case-insensitive comparisons), then indexes that differ only in case, accented characters, or punctuation characters might be converted to the same value.
If you pass an associative array as a parameter to a remote database, and the local and the remote databases have different NLS_SORT or NLS_COMP values, then:
The collection method FIRST, LAST, NEXT or PRIOR (described in "Collection Methods") might return unexpected values or raise exceptions.
Indexes that are unique on the local database might not be unique on the remote database, raising the predefined exception VALUE_ERROR.
An associative array is appropriate for:
A relatively small lookup table, which can be constructed in memory each time you invoke the subprogram or initialize the package that declares it
Passing collections to and from the database server
Declare formal subprogram parameters of associative array types. With Oracle Call Interface (OCI) or an Oracle precompiler, bind the host arrays to the corresponding actual parameters. PL/SQL automatically converts between host arrays and associative arrays indexed by PLS_INTEGER.
Note:
You cannot declare an associative array type at schema level. Therefore, to pass an associative array variable as a parameter to a standalone subprogram, you must declare the type of that variable in a package specification. Doing so makes the type available to both the invoked subprogram (which declares a formal parameter of that type) and the invoking subprogram or anonymous block (which declares and passes the variable of that type). See Example 10-2.Tip:
The most efficient way to pass collections to and from the database server is to use associative arrays with theFORALL statement or BULK COLLECT clause. For details, see "FORALL Statement" and "BULK COLLECT Clause".An associative array is intended for temporary data storage. To make an associative array persistent for the life of a database session, declare it in a package specification and populate it in the package body.
A varray (variable-size array) is an array whose number of elements can vary from zero (empty) to the declared maximum size. To access an element of a varray variable, use the syntax variable_name(index). The lower bound of index is 1; the upper bound is the current number of elements. The upper bound changes as you add or delete elements, but it cannot exceed the maximum size. When you store and retrieve a varray from the database, its indexes and element order remain stable.
Figure 5-1shows a varray variable named Grades, which has maximum size 10 and contains seven elements. Grades(n) references the nth element of Grades. The upper bound of Grades is 7, and it cannot exceed 10.
Figure 5-1 Varray of Maximum Size 10 with 7 Elements

The database stores a varray variable as a single object. If a varray variable is less than 4 KB, it resides inside the table of which it is a column; otherwise, it resides outside the table but in the same tablespace.
An uninitialized varray variable is a null collection. You must initialize it, either by making it empty or by assigning a non-NULL value to it. For details, see "Collection Constructors" and "Assigning Values to Collection Variables".
Example 5-4 defines a local VARRAY type, declares a variable of that type (initializing it with a constructor), and defines a procedure that prints the varray. The example invokes the procedure three times: After initializing the variable, after changing the values of two elements individually, and after using a constructor to the change the values of all elements. (For an example of a procedure that prints a varray that might be null or empty, see Example 5-24.)
Example 5-4 Varray (Variable-Size Array)
DECLARE
TYPE Foursome IS VARRAY(4) OF VARCHAR2(15); -- VARRAY type
-- varray variable initialized with constructor:
team Foursome := Foursome('John', 'Mary', 'Alberto', 'Juanita');
PROCEDURE print_team (heading VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
FOR i IN 1..4 LOOP
DBMS_OUTPUT.PUT_LINE(i || '.' || team(i));
END LOOP;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_team('2001 Team:');
team(3) := 'Pierre'; -- Change values of two elements
team(4) := 'Yvonne';
print_team('2005 Team:');
-- Invoke constructor to assign new values to varray variable:
team := Foursome('Arun', 'Amitha', 'Allan', 'Mae');
print_team('2009 Team:');
END;
/
Result:
2001 Team: 1.John 2.Mary 3.Alberto 4.Juanita --- 2005 Team: 1.John 2.Mary 3.Pierre 4.Yvonne --- 2009 Team: 1.Arun 2.Amitha 3.Allan 4.Mae ---
See Also:
Table 5-1 for a summary of varray characteristics
"varray_type_def ::=" for the syntax of a VARRAY type definition
"CREATE TYPE Statement" for information about creating standalone VARRAY types
Oracle Database SQL Language Reference for more information about varrays
A varray is appropriate when:
You know the maximum number of elements.
You usually access the elements sequentially.
Because you must store or retrieve all elements at the same time, a varray might be impractical for large numbers of elements.
In the database, a nested table is a column type that stores an unspecified number of rows in no particular order. When you retrieve a nested table value from the database into a PL/SQL nested table variable, PL/SQL gives the rows consecutive indexes, starting at 1. Using these indexes, you can access the individual rows of the nested table variable. The syntax is variable_name(index). The indexes and row order of a nested table might not remain stable as you store and retrieve the nested table from the database.
The amount of memory that a nested table variable occupies can increase or decrease dynamically, as you add or delete elements.
An uninitialized nested table variable is a null collection. You must initialize it, either by making it empty or by assigning a non-NULL value to it. For details, see "Collection Constructors" and "Assigning Values to Collection Variables".
Example 5-5 defines a local nested table type, declares a variable of that type (initializing it with a constructor), and defines a procedure that prints the nested table. (The procedure uses the collection methods FIRST and LAST, described in "Collection Methods".) The example invokes the procedure three times: After initializing the variable, after changing the value of one element, and after using a constructor to the change the values of all elements. After the second constructor invocation, the nested table has only two elements. Referencing element 3 would raise error ORA-06533.
Example 5-5 Nested Table of Local Type
DECLARE
TYPE Roster IS TABLE OF VARCHAR2(15); -- nested table type
-- nested table variable initialized with constructor:
names Roster := Roster('D Caruso', 'J Hamil', 'D Piro', 'R Singh');
PROCEDURE print_names (heading VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
FOR i IN names.FIRST .. names.LAST LOOP -- For first to last element
DBMS_OUTPUT.PUT_LINE(names(i));
END LOOP;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_names('Initial Values:');
names(3) := 'P Perez'; -- Change value of one element
print_names('Current Values:');
names := Roster('A Jansen', 'B Gupta'); -- Change entire table
print_names('Current Values:');
END;
/
Result:
Initial Values: D Caruso J Hamil D Piro R Singh --- Current Values: D Caruso J Hamil P Perez R Singh --- Current Values: A Jansen B Gupta
Example 5-6 defines a standalone nested table type, nt_type, and a standalone procedure to print a variable of that type, print_nt. (The procedure uses the collection methods FIRST and LAST, described in "Collection Methods".) An anonymous block declares a variable of type nt_type, initializing it to empty with a constructor, and invokes print_nt twice: After initializing the variable and after using a constructor to the change the values of all elements.
Example 5-6 Nested Table of Standalone Type
CREATE OR REPLACE TYPE nt_type IS TABLE OF NUMBER;
/
CREATE OR REPLACE PROCEDURE print_nt (nt nt_type) IS
i NUMBER;
BEGIN
i := nt.FIRST;
IF i IS NULL THEN
DBMS_OUTPUT.PUT_LINE('nt is empty');
ELSE
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT('nt.(' || i || ') = '); print(nt(i));
i := nt.NEXT(i);
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END print_nt;
/
DECLARE
nt nt_type := nt_type(); -- nested table variable initialized to empty
BEGIN
print_nt(nt);
nt := nt_type(90, 9, 29, 58);
print_nt(nt);
END;
/
Result:
nt is empty --- nt.(1) = 90 nt.(2) = 9 nt.(3) = 29 nt.(4) = 58 ---
See Also:
Table 5-1 for a summary of nested table characteristics
"nested_table_type_def ::=" for the syntax of a nested table type definition
"CREATE TYPE Statement" for information about creating standalone nested table types
"INSTEAD OF Triggers on Nested Table Columns of Views" for information about triggers that update nested table columns of views
Oracle Database SQL Language Reference for more information about nested tables
Conceptually, a nested table is like a one-dimensional array with an arbitrary number of elements. However, a nested table differs from an array in these important ways:
An array has a declared number of elements, but a nested table does not. The size of a nested table can increase dynamically.
An array is always dense. A nested array is dense initially, but it can become sparse, because you can delete elements from it.
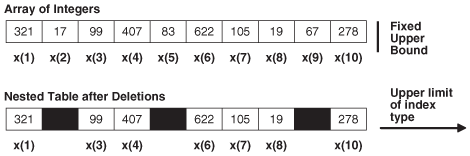
Figure 5-2 shows the important differences between a nested table and an array.
A nested table is appropriate when:
The number of elements is not set.
Index values are not consecutive.
You must delete or update some elements, but not all elements simultaneously.
Nested table data is stored in a separate store table, a system-generated database table. When you access a nested table, the database joins the nested table with its store table. This makes nested tables suitable for queries and updates that affect only some elements of the collection.
You would create a separate lookup table, with multiple entries for each row of the main table, and access it through join queries.
Note:
This topic applies only to varrays and nested tables. Associative arrays do not have constructors. In this topic, collection means varray or nested table.A collection constructor (constructor) is a system-defined function with the same name as a collection type, which returns a collection of that type. The syntax of a constructor invocation is:
collection_type ( [ value [, value ]... ] )
If the parameter list is empty, the constructor returns an empty collection. Otherwise, the constructor returns a collection that contains the specified values. For semantic details, see "collection_constructor".
You can assign the returned collection to a collection variable (of the same type) in the variable declaration and in the executable part of a block.
Example 5-7 invokes a constructor twice: to initialize the varray variable team to empty in its declaration, and to give it new values in the executable part of the block. The procedure print_team shows the initial and final values of team. To determine when team is empty, print_team uses the collection method COUNT, described in "Collection Methods". (For an example of a procedure that prints a varray that might be null, see Example 5-24.)
Example 5-7 Initializing Collection (Varray) Variable to Empty
DECLARE TYPE Foursome IS VARRAY(4) OF VARCHAR2(15); team Foursome := Foursome(); -- initialize to empty PROCEDURE print_team (heading VARCHAR2) IS BEGIN DBMS_OUTPUT.PUT_LINE(heading); IF team.COUNT = 0 THEN DBMS_OUTPUT.PUT_LINE('Empty'); ELSE FOR i IN 1..4 LOOP DBMS_OUTPUT.PUT_LINE(i || '.' || team(i)); END LOOP; END IF; DBMS_OUTPUT.PUT_LINE('---'); END; BEGIN print_team('Team:'); team := Foursome('John', 'Mary', 'Alberto', 'Juanita'); print_team('Team:'); END; /
Result:
Team: Empty --- Team: 1.John 2.Mary 3.Alberto 4.Juanita ---
You can assign a value to a collection variable in these ways:
Invoke a constructor to create a collection and assign it to the collection variable, as explained in "Collection Constructors".
Use the assignment statement (described in "Assignment Statement") to assign it the value of another existing collection variable.
Pass it to a subprogram as an OUT or IN OUT parameter, and then assign the value inside the subprogram.
To assign a value to a scalar element of a collection variable, reference the element as collection_variable_name(index) and assign it a value as instructed in "Assigning Values to Variables".
See Also:
"BULK COLLECT Clause"You can assign a collection to a collection variable only if they have the same data type. Having the same element type is not enough.
In Example 5-8, VARRAY types triplet and trio have the same element type, VARCHAR(15). Collection variables group1 and group2 have the same data type, triplet, but collection variable group3 has the data type trio. The assignment of group1 to group2 succeeds, but the assignment of group1 to group3 fails.
Example 5-8 Data Type Compatibility for Collection Assignment
DECLARE
TYPE triplet IS VARRAY(3) OF VARCHAR2(15);
TYPE trio IS VARRAY(3) OF VARCHAR2(15);
group1 triplet := triplet('Jones', 'Wong', 'Marceau');
group2 triplet;
group3 trio;
BEGIN
group2 := group1; -- succeeds
group3 := group1; -- fails
END;
/
Result:
ERROR at line 10: ORA-06550: line 10, column 13: PLS-00382: expression is of wrong type ORA-06550: line 10, column 3: PL/SQL: Statement ignored
To a varray or nested table variable, you can assign the value NULL or a null collection of the same data type. Either assignment makes the variable null.
Example 5-7 initializes the nested table variable dname_tab to a non-null value; assigns a null collection to it, making it null; and re-initializes it to a different non-null value.
Example 5-9 Assigning Null Value to Nested Table Variable
DECLARE
TYPE dnames_tab IS TABLE OF VARCHAR2(30);
dept_names dnames_tab := dnames_tab(
'Shipping','Sales','Finance','Payroll'); -- Initialized to non-null value
empty_set dnames_tab; -- Not initialized, therefore null
PROCEDURE print_dept_names_status IS
BEGIN
IF dept_names IS NULL THEN
DBMS_OUTPUT.PUT_LINE('dept_names is null.');
ELSE
DBMS_OUTPUT.PUT_LINE('dept_names is not null.');
END IF;
END print_dept_names_status;
BEGIN
print_dept_names_status;
dept_names := empty_set; -- Assign null collection to dept_names.
print_dept_names_status;
dept_names := dnames_tab (
'Shipping','Sales','Finance','Payroll'); -- Re-initialize dept_names
print_dept_names_status;
END;
/
Result:
dept_names is not null.
dept_names is null.
dept_names is not null.
To a nested table variable, you can assign the result of a SQL MULTISET operation or SQL SET function invocation.
The SQL MULTISET operators combine two nested tables into a single nested table. The elements of the two nested tables must have comparable data types. For information about the MULTISET operators, see Oracle Database SQL Language Reference.
The SQL SET function takes a nested table argument and returns a nested table of the same data type whose elements are distinct (the function eliminates duplicate elements). For information about the SET function, see Oracle Database SQL Language Reference.
Example 5-10 assigns the results of several MULTISET operations and one SET function invocation of the nested table variable answer, using the procedure print_nested_table to print answer after each assignment. The procedure use the collection methods FIRST and LAST, described in "Collection Methods".
Example 5-10 Assigning Set Operation Results to Nested Table Variable
DECLARE
TYPE nested_typ IS TABLE OF NUMBER;
nt1 nested_typ := nested_typ(1,2,3);
nt2 nested_typ := nested_typ(3,2,1);
nt3 nested_typ := nested_typ(2,3,1,3);
nt4 nested_typ := nested_typ(1,2,4);
answer nested_typ;
PROCEDURE print_nested_table (nt nested_typ) IS
output VARCHAR2(128);
BEGIN
IF nt IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Result: null set');
ELSIF nt.COUNT = 0 THEN
DBMS_OUTPUT.PUT_LINE('Result: empty set');
ELSE
FOR i IN nt.FIRST .. nt.LAST LOOP -- For first to last element
output := output || nt(i) || ' ';
END LOOP;
DBMS_OUTPUT.PUT_LINE('Result: ' || output);
END IF;
END print_nested_table;
BEGIN
answer := nt1 MULTISET UNION nt4;
print_nested_table(answer);
answer := nt1 MULTISET UNION nt3;
print_nested_table(answer);
answer := nt1 MULTISET UNION DISTINCT nt3;
print_nested_table(answer);
answer := nt2 MULTISET INTERSECT nt3;
print_nested_table(answer);
answer := nt2 MULTISET INTERSECT DISTINCT nt3;
print_nested_table(answer);
answer := SET(nt3);
print_nested_table(answer);
answer := nt3 MULTISET EXCEPT nt2;
print_nested_table(answer);
answer := nt3 MULTISET EXCEPT DISTINCT nt2;
print_nested_table(answer);
END;
/
Result:
Result: 1 2 3 1 2 4 Result: 1 2 3 2 3 1 3 Result: 1 2 3 Result: 3 2 1 Result: 3 2 1 Result: 2 3 1 Result: 3 Result: empty set
Although a collection has only one dimension, you can model a multidimensional collection with a collection whose elements are collections.
In Example 5-11, nva is a two-dimensional varray—a varray of varrays of integers.
Example 5-11 Two-Dimensional Varray (Varray of Varrays)
DECLARE
TYPE t1 IS VARRAY(10) OF INTEGER; -- varray of integer
va t1 := t1(2,3,5);
TYPE nt1 IS VARRAY(10) OF t1; -- varray of varray of integer
nva nt1 := nt1(va, t1(55,6,73), t1(2,4), va);
i INTEGER;
va1 t1;
BEGIN
i := nva(2)(3);
DBMS_OUTPUT.PUT_LINE('i = ' || i);
nva.EXTEND;
nva(5) := t1(56, 32); -- replace inner varray elements
nva(4) := t1(45,43,67,43345); -- replace an inner integer element
nva(4)(4) := 1; -- replace 43345 with 1
nva(4).EXTEND; -- add element to 4th varray element
nva(4)(5) := 89; -- store integer 89 there
END;
/
Result:
i = 73
In Example 5-12, ntb1 is a nested table of nested tables of strings, and ntb2 is a nested table of varrays of integers.
Example 5-12 Nested Tables of Nested Tables and Varrays of Integers
DECLARE
TYPE tb1 IS TABLE OF VARCHAR2(20); -- nested table of strings
vtb1 tb1 := tb1('one', 'three');
TYPE ntb1 IS TABLE OF tb1; -- nested table of nested tables of strings
vntb1 ntb1 := ntb1(vtb1);
TYPE tv1 IS VARRAY(10) OF INTEGER; -- varray of integers
TYPE ntb2 IS TABLE OF tv1; -- nested table of varrays of integers
vntb2 ntb2 := ntb2(tv1(3,5), tv1(5,7,3));
BEGIN
vntb1.EXTEND;
vntb1(2) := vntb1(1);
vntb1.DELETE(1); -- delete first element of vntb1
vntb1(2).DELETE(1); -- delete first string from second table in nested table
END;
/
In Example 5-13, ntb1 is a nested table of associative arrays, and ntb2 is a nested table of varrays of strings.
Example 5-13 Nested Tables of Associative Arrays and Varrays of Strings
DECLARE
TYPE tb1 IS TABLE OF INTEGER INDEX BY PLS_INTEGER; -- associative arrays
v4 tb1;
v5 tb1;
TYPE ntb1 IS TABLE OF tb1 INDEX BY PLS_INTEGER; -- nested table of
v2 ntb1; -- associative arrays
TYPE va1 IS VARRAY(10) OF VARCHAR2(20); -- varray of strings
v1 va1 := va1('hello', 'world');
TYPE ntb2 IS TABLE OF va1 INDEX BY PLS_INTEGER; -- nested table of varrays
v3 ntb2;
BEGIN
v4(1) := 34; -- populate associative array
v4(2) := 46456;
v4(456) := 343;
v2(23) := v4; -- populate nested table of associative arrays
v3(34) := va1(33, 456, 656, 343); -- populate nested table of varrays
v2(35) := v5; -- assign empty associative array to v2(35)
v2(35)(2) := 78;
END;
/
You cannot compare associative array variables to the value NULL or to each other.
Except for Comparing Nested Tables for Equality and Inequality, you cannot natively compare two collection variables with relational operators (listed in Table 2-5). This restriction also applies to implicit comparisons. For example, a collection variable cannot appear in a DISTINCT, GROUP BY, or ORDER BY clause.
To determine if one collection variable is less than another (for example), you must define what less than means in that context and write a function that returns TRUE or FALSE. For information about writing functions, see Chapter 8, "PL/SQL Subprograms."
You can compare varray and nested table variables to the value NULL with the "IS [NOT] NULL Operator", but not with the relational operators equal (=) and not equal (<>, !=, ~=, or ^=).
Example 5-14 compares a varray variable and a nested table variable to NULL correctly.
Example 5-14 Comparing Varray and Nested Table Variables to NULL
DECLARE
TYPE Foursome IS VARRAY(4) OF VARCHAR2(15); -- VARRAY type
team Foursome; -- varray variable
TYPE Roster IS TABLE OF VARCHAR2(15); -- nested table type
names Roster := Roster('Adams', 'Patel'); -- nested table variable
BEGIN
IF team IS NULL THEN
DBMS_OUTPUT.PUT_LINE('team IS NULL');
ELSE
DBMS_OUTPUT.PUT_LINE('team IS NOT NULL');
END IF;
IF names IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE('names IS NOT NULL');
ELSE
DBMS_OUTPUT.PUT_LINE('names IS NULL');
END IF;
END;
/
Result:
team IS NULL names IS NOT NULL
If two nested table variables have the same nested table type, and that nested table type does not have elements of a record type, then you can compare the two variables for equality or inequality with the relational operators equal (=) and not equal (<>, !=, ~=, ^=). Two nested table variables are equal if and only if they have the same set of elements (in any order).
See Also:
"Record Comparisons"Example 5-15 compares nested table variables for equality and inequality with relational operators.
Example 5-15 Comparing Nested Tables for Equality and Inequality
DECLARE TYPE dnames_tab IS TABLE OF VARCHAR2(30); -- element type is not record type dept_names1 dnames_tab := dnames_tab('Shipping','Sales','Finance','Payroll'); dept_names2 dnames_tab := dnames_tab('Sales','Finance','Shipping','Payroll'); dept_names3 dnames_tab := dnames_tab('Sales','Finance','Payroll'); BEGIN IF dept_names1 = dept_names2 THEN DBMS_OUTPUT.PUT_LINE('dept_names1 = dept_names2'); END IF; IF dept_names2 != dept_names3 THEN DBMS_OUTPUT.PUT_LINE('dept_names2 != dept_names3'); END IF; END; /
Result:
dept_names1 = dept_names2 dept_names2 != dept_names3
You can compare nested table variables, and test some of their properties, with SQL multiset conditions (described in Oracle Database SQL Language Reference).
Example 5-16 uses the SQL multiset conditions and two SQL functions that take nested table variable arguments, CARDINALITY (described in Oracle Database SQL Language Reference) and SET (described in Oracle Database SQL Language Reference).
Example 5-16 Comparing Nested Tables with SQL Multiset Conditions
DECLARE
TYPE nested_typ IS TABLE OF NUMBER;
nt1 nested_typ := nested_typ(1,2,3);
nt2 nested_typ := nested_typ(3,2,1);
nt3 nested_typ := nested_typ(2,3,1,3);
nt4 nested_typ := nested_typ(1,2,4);
PROCEDURE testify (
truth BOOLEAN := NULL,
quantity NUMBER := NULL
) IS
BEGIN
IF truth IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE (
CASE truth
WHEN TRUE THEN 'True'
WHEN FALSE THEN 'False'
END
);
END IF;
IF quantity IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE(quantity);
END IF;
END;
BEGIN
testify(truth => (nt1 IN (nt2,nt3,nt4))); -- condition
testify(truth => (nt1 SUBMULTISET OF nt3)); -- condition
testify(truth => (nt1 NOT SUBMULTISET OF nt4)); -- condition
testify(truth => (4 MEMBER OF nt1)); -- condition
testify(truth => (nt3 IS A SET)); -- condition
testify(truth => (nt3 IS NOT A SET)); -- condition
testify(truth => (nt1 IS EMPTY)); -- condition
testify(quantity => (CARDINALITY(nt3))); -- function
testify(quantity => (CARDINALITY(SET(nt3)))); -- 2 functions
END;
/
Result:
True True True False False True False 4 3
A collection method is a PL/SQL subprogram—either a function that returns information about a collection or a procedure that operates on a collection. Collection methods make collections easier to use and your applications easier to maintain. Table 5-2 summarizes the collection methods.
Note:
With a null collection,EXISTS is the only collection method that does not raise the predefined exception COLLECTION_IS_NULL.| Method | Type | Description |
|---|---|---|
|
|
Procedure |
Deletes elements from collection. |
|
|
Procedure |
Deletes elements from end of varray or nested table. |
|
|
Procedure |
Adds elements to end of varray or nested table. |
|
|
Function |
Returns |
|
|
Function |
Returns first index in collection. |
|
|
Function |
Returns last index in collection. |
|
|
Function |
Returns number of elements in collection. |
|
|
Function |
Returns maximum number of elements that collection can have. |
|
|
Function |
Returns index that precedes specified index. |
|
|
Function |
Returns index that succeeds specified index. |
The basic syntax of a collection method invocation is:
collection_name.method
For detailed syntax, see "Collection Method Invocation".
A collection method invocation can appear anywhere that an invocation of a PL/SQL subprogram of its type (function or procedure) can appear, except in a SQL statement. (For general information about PL/SQL subprograms, see Chapter 8, "PL/SQL Subprograms.")
In a subprogram, a collection parameter assumes the properties of the argument bound to it. You can apply collection methods to such parameters. For varray parameters, the value of LIMIT is always derived from the parameter type definition, regardless of the parameter mode.
DELETE is a procedure that deletes elements from a collection. This method has these forms:
DELETE deletes all elements from a collection of any type.
This operation immediately frees the memory allocated to the deleted elements.
From an associative array or nested table (but not a varray):
DELETE(n) deletes the element whose index is n, if that element exists; otherwise, it does nothing.
DELETE(m,n) deletes all elements whose indexes are in the range m..n, if both m and n exist and m <= n; otherwise, it does nothing.
For these two forms of DELETE, PL/SQL keeps placeholders for the deleted elements. Therefore, the deleted elements are included in the internal size of the collection, and you can restore a deleted element by assigning a valid value to it.
Example 5-17 declares a nested table variable, initializing it with six elements; deletes and then restores the second element; deletes a range of elements and then restores one of them; and then deletes all elements. The restored elements occupy the same memory as the corresponding deleted elements. The procedure print_nt prints the nested table variable after initialization and after each DELETE operation. The type nt_type and procedure print_nt are defined in Example 5-6.
Example 5-17 DELETE Method with Nested Table
DECLARE nt nt_type := nt_type(11, 22, 33, 44, 55, 66); BEGIN print_nt(nt); nt.DELETE(2); -- Delete second element print_nt(nt); nt(2) := 2222; -- Restore second element print_nt(nt); nt.DELETE(2, 4); -- Delete range of elements print_nt(nt); nt(3) := 3333; -- Restore third element print_nt(nt); nt.DELETE; -- Delete all elements print_nt(nt); END; /
Result:
nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(2) = 2222 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(3) = 3333 nt.(5) = 55 nt.(6) = 66 --- nt is empty ---
Example 5-18 populates an associative array indexed by string and deletes all elements, which frees the memory allocated to them. Next, the example replaces the deleted elements—that is, adds new elements that have the same indexes as the deleted elements. The new replacement elements do not occupy the same memory as the corresponding deleted elements. Finally, the example deletes one element and then a range of elements. The procedure print_aa_str shows the effects of the operations.
Example 5-18 DELETE Method with Associative Array Indexed by String
DECLARE
TYPE aa_type_str IS TABLE OF INTEGER INDEX BY VARCHAR2(10);
aa_str aa_type_str;
PROCEDURE print_aa_str IS
i VARCHAR2(10);
BEGIN
i := aa_str.FIRST;
IF i IS NULL THEN
DBMS_OUTPUT.PUT_LINE('aa_str is empty');
ELSE
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT('aa_str.(' || i || ') = '); print(aa_str(i));
i := aa_str.NEXT(i);
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END print_aa_str;
BEGIN
aa_str('M') := 13;
aa_str('Z') := 26;
aa_str('C') := 3;
print_aa_str;
aa_str.DELETE; -- Delete all elements
print_aa_str;
aa_str('M') := 13; -- Replace deleted element with same value
aa_str('Z') := 260; -- Replace deleted element with new value
aa_str('C') := 30; -- Replace deleted element with new value
aa_str('W') := 23; -- Add new element
aa_str('J') := 10; -- Add new element
aa_str('N') := 14; -- Add new element
aa_str('P') := 16; -- Add new element
aa_str('W') := 23; -- Add new element
aa_str('J') := 10; -- Add new element
print_aa_str;
aa_str.DELETE('C'); -- Delete one element
print_aa_str;
aa_str.DELETE('N','W'); -- Delete range of elements
print_aa_str;
aa_str.DELETE('Z','M'); -- Does nothing
print_aa_str;
END;
/
Result:
aa_str.(C) = 3 aa_str.(M) = 13 aa_str.(Z) = 26 --- aa_str is empty --- aa_str.(C) = 30 aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(N) = 14 aa_str.(P) = 16 aa_str.(W) = 23 aa_str.(Z) = 260 --- aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(N) = 14 aa_str.(P) = 16 aa_str.(W) = 23 aa_str.(Z) = 260 --- aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(Z) = 260 --- aa_str.(J) = 10 aa_str.(M) = 13 aa_str.(Z) = 260 ---
TRIM is a procedure that deletes elements from the end of a varray or nested table. This method has these forms:
TRIM removes one element from the end of the collection, if the collection has at least one element; otherwise, it raises the predefined exception SUBSCRIPT_BEYOND_COUNT.
TRIM(n) removes n elements from the end of the collection, if there are at least n elements at the end; otherwise, it raises the predefined exception SUBSCRIPT_BEYOND_COUNT.
TRIM operates on the internal size of a collection. That is, if DELETE deletes an element but keeps a placeholder for it, then TRIM considers the element to exist. Therefore, TRIM can delete a deleted element.
PL/SQL does not keep placeholders for trimmed elements. Therefore, trimmed elements are not included in the internal size of the collection, and you cannot restore a trimmed element by assigning a valid value to it.
Caution:
Do not depend on interaction betweenTRIM and DELETE. Treat nested tables like either fixed-size arrays (and use only DELETE) or stacks (and use only TRIM and EXTEND).Example 5-19 declares a nested table variable, initializing it with six elements; trims the last element; deletes the fourth element; and then trims the last two elements—one of which is the deleted fourth element. The procedure print_nt prints the nested table variable after initialization and after the TRIM and DELETE operations. The type nt_type and procedure print_nt are defined in Example 5-6.
Example 5-19 TRIM Method with Nested Table
DECLARE nt nt_type := nt_type(11, 22, 33, 44, 55, 66); BEGIN print_nt(nt); nt.TRIM; -- Trim last element print_nt(nt); nt.DELETE(4); -- Delete fourth element print_nt(nt); nt.TRIM(2); -- Trim last two elements print_nt(nt); END; /
Result:
nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 nt.(6) = 66 --- nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(4) = 44 nt.(5) = 55 --- nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 nt.(5) = 55 --- nt.(1) = 11 nt.(2) = 22 nt.(3) = 33 ---
EXTEND is a procedure that adds elements to the end of a varray or nested table. The collection can be empty, but not null. (To make a collection empty or add elements to a null collection, use a constructor. For more information, see "Collection Constructors".)
The EXTEND method has these forms:
EXTEND appends one null element to the collection.
EXTEND(n) appends n null elements to the collection.
EXTEND(n,i) appends n copies of the ith element to the collection.
EXTEND operates on the internal size of a collection. That is, if DELETE deletes an element but keeps a placeholder for it, then EXTEND considers the element to exist.
Example 5-20 declares a nested table variable, initializing it with three elements; appends two copies of the first element; deletes the fifth (last) element; and then appends one null element. Because EXTEND considers the deleted fifth element to exist, the appended null element is the sixth element. The procedure print_nt prints the nested table variable after initialization and after the EXTEND and DELETE operations. The type nt_type and procedure print_nt are defined in Example 5-6.
Example 5-20 EXTEND Method with Nested Table
DECLARE nt nt_type := nt_type(11, 22, 33); BEGIN print_nt(nt); nt.EXTEND(2,1); -- Append two copies of first element print_nt(nt); nt.DELETE(5); -- Delete fifth element print_nt(nt); nt.EXTEND; -- Append one null element print_nt(nt); END; /
Result:
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
---
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
nt.(4) = 11
nt.(5) = 11
---
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
nt.(4) = 11
---
nt.(1) = 11
nt.(2) = 22
nt.(3) = 33
nt.(4) = 11
nt.(6) = NULL
---
EXISTS is a function that tells you whether the specified element of a varray or nested table exists.
EXISTS(n) returns TRUE if the nth element of the collection exists and FALSE otherwise. If n is out of range, EXISTS returns FALSE instead of raising the predefined exception SUBSCRIPT_OUTSIDE_LIMIT.
For a deleted element, EXISTS(n) returns FALSE, even if DELETE kept a placeholder for it.
Example 5-21 initializes a nested table with four elements, deletes the second element, and prints either the value or status of elements 1 through 6.
Example 5-21 EXISTS Method with Nested Table
DECLARE TYPE NumList IS TABLE OF INTEGER; n NumList := NumList(1,3,5,7); BEGIN n.DELETE(2); -- Delete second element FOR i IN 1..6 LOOP IF n.EXISTS(i) THEN DBMS_OUTPUT.PUT_LINE('n(' || i || ') = ' || n(i)); ELSE DBMS_OUTPUT.PUT_LINE('n(' || i || ') does not exist'); END IF; END LOOP; END; /
Result:
n(1) = 1 n(2) does not exist n(3) = 5 n(4) = 7 n(5) does not exist n(6) does not exist
FIRST and LAST are functions. If the collection has at least one element, FIRST and LAST return the indexes of the first and last elements, respectively (ignoring deleted elements, even if DELETE kept placeholders for them). If the collection has only one element, FIRST and LAST return the same index. If the collection is empty, FIRST and LAST return NULL.
For an associative array indexed by PLS_INTEGER, the first and last elements are those with the smallest and largest indexes, respectively.
Example 5-22 shows the values of FIRST and LAST for an associative array indexed by PLS_INTEGER, deletes the first and last elements, and shows the values of FIRST and LAST again.
Example 5-22 FIRST and LAST Values for Associative Array Indexed by PLS_INTEGER
DECLARE
TYPE aa_type_int IS TABLE OF INTEGER INDEX BY PLS_INTEGER;
aa_int aa_type_int;
PROCEDURE print_first_and_last IS
BEGIN
DBMS_OUTPUT.PUT_LINE('FIRST = ' || aa_int.FIRST);
DBMS_OUTPUT.PUT_LINE('LAST = ' || aa_int.LAST);
END print_first_and_last;
BEGIN
aa_int(1) := 3;
aa_int(2) := 6;
aa_int(3) := 9;
aa_int(4) := 12;
DBMS_OUTPUT.PUT_LINE('Before deletions:');
print_first_and_last;
aa_int.DELETE(1);
aa_int.DELETE(4);
DBMS_OUTPUT.PUT_LINE('After deletions:');
print_first_and_last;
END;
/
Result:
Before deletions: FIRST = 1 LAST = 4 After deletions: FIRST = 2 LAST = 3
For an associative array indexed by string, the first and last elements are those with the lowest and highest key values, respectively. Key values are in sorted order (for more information, see "NLS Parameter Values Affect Associative Arrays Indexed by String").
Example 5-23 shows the values of FIRST and LAST for an associative array indexed by string, deletes the first and last elements, and shows the values of FIRST and LAST again.
Example 5-23 FIRST and LAST Values for Associative Array Indexed by String
DECLARE
TYPE aa_type_str IS TABLE OF INTEGER INDEX BY VARCHAR2(10);
aa_str aa_type_str;
PROCEDURE print_first_and_last IS
BEGIN
DBMS_OUTPUT.PUT_LINE('FIRST = ' || aa_str.FIRST);
DBMS_OUTPUT.PUT_LINE('LAST = ' || aa_str.LAST);
END print_first_and_last;
BEGIN
aa_str('Z') := 26;
aa_str('A') := 1;
aa_str('K') := 11;
aa_str('R') := 18;
DBMS_OUTPUT.PUT_LINE('Before deletions:');
print_first_and_last;
aa_str.DELETE('A');
aa_str.DELETE('Z');
DBMS_OUTPUT.PUT_LINE('After deletions:');
print_first_and_last;
END;
/
Result:
Before deletions: FIRST = A LAST = Z After deletions: FIRST = K LAST = R
For a varray that is not empty, FIRST always returns 1. For every varray, LAST always equals COUNT (see Example 5-26).
Example 5-24 prints the varray team using a FOR LOOP statement with the bounds team.FIRST and team.LAST. Because a varray is always dense, team(i) inside the loop always exists.
Example 5-24 Printing Varray with FIRST and LAST in FOR LOOP
DECLARE
TYPE team_type IS VARRAY(4) OF VARCHAR2(15);
team team_type;
PROCEDURE print_team (heading VARCHAR2)
IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
IF team IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Does not exist');
ELSIF team.FIRST IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Has no members');
ELSE
FOR i IN team.FIRST..team.LAST LOOP
DBMS_OUTPUT.PUT_LINE(i || '. ' || team(i));
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_team('Team Status:');
team := team_type(); -- Team is funded, but nobody is on it.
print_team('Team Status:');
team := team_type('John', 'Mary'); -- Put 2 members on team.
print_team('Initial Team:');
team := team_type('Arun', 'Amitha', 'Allan', 'Mae'); -- Change team.
print_team('New Team:');
END;
/
Result:
Team Status: Does not exist --- Team Status: Has no members --- Initial Team: 1. John 2. Mary --- New Team: 1. Arun 2. Amitha 3. Allan 4. Mae ---
For a nested table, LAST equals COUNT unless you delete elements from its middle, in which case LAST is larger than COUNT (see Example 5-27).
Example 5-25 prints the nested table team using a FOR LOOP statement with the bounds team.FIRST and team.LAST. Because a nested table can be sparse, the FOR LOOP statement prints team(i) only if team.EXISTS(i) is TRUE.
Example 5-25 Printing Nested Table with FIRST and LAST in FOR LOOP
DECLARE
TYPE team_type IS TABLE OF VARCHAR2(15);
team team_type;
PROCEDURE print_team (heading VARCHAR2) IS
BEGIN
DBMS_OUTPUT.PUT_LINE(heading);
IF team IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Does not exist');
ELSIF team.FIRST IS NULL THEN
DBMS_OUTPUT.PUT_LINE('Has no members');
ELSE
FOR i IN team.FIRST..team.LAST LOOP
DBMS_OUTPUT.PUT(i || '. ');
IF team.EXISTS(i) THEN
DBMS_OUTPUT.PUT_LINE(team(i));
ELSE
DBMS_OUTPUT.PUT_LINE('(to be hired)');
END IF;
END LOOP;
END IF;
DBMS_OUTPUT.PUT_LINE('---');
END;
BEGIN
print_team('Team Status:');
team := team_type(); -- Team is funded, but nobody is on it.
print_team('Team Status:');
team := team_type('Arun', 'Amitha', 'Allan', 'Mae'); -- Add members.
print_team('Initial Team:');
team.DELETE(2,3); -- Remove 2nd and 3rd members.
print_team('Current Team:');
END;
/
Result:
Team Status: Does not exist --- Team Status: Has no members --- Initial Team: 1. Arun 2. Amitha 3. Allan 4. Mae --- Current Team: 1. Arun 2. (to be hired) 3. (to be hired) 4. Mae ---
COUNT is a function that returns the number of elements in the collection (ignoring deleted elements, even if DELETE kept placeholders for them).
For a varray, COUNT always equals LAST. If you increase or decrease the size of a varray (with the EXTEND or TRIM method), the value of COUNT changes.
Example 5-26 shows the values of COUNT and LAST for a varray after initialization with four elements, after EXTEND(3), and after TRIM(5).
Example 5-26 COUNT and LAST Values for Varray
DECLARE
TYPE NumList IS VARRAY(10) OF INTEGER;
n NumList := NumList(1,3,5,7);
PROCEDURE print_count_and_last IS
BEGIN
DBMS_OUTPUT.PUT('n.COUNT = ' || n.COUNT || ', ');
DBMS_OUTPUT.PUT_LINE('n.LAST = ' || n.LAST);
END print_count_and_last;
BEGIN
print_count_and_last;
n.EXTEND(3);
print_count_and_last;
n.TRIM(5);
print_count_and_last;
END;
/
Result:
n.COUNT = 4, n.LAST = 4 n.COUNT = 7, n.LAST = 7 n.COUNT = 2, n.LAST = 2
For a nested table, COUNT equals LAST unless you delete elements from the middle of the nested table, in which case COUNT is smaller than LAST.
Example 5-27 shows the values of COUNT and LAST for a nested table after initialization with four elements, after deleting the third element, and after adding two null elements to the end. Finally, the example prints the status of elements 1 through 8.
Example 5-27 COUNT and LAST Values for Nested Table
DECLARE
TYPE NumList IS TABLE OF INTEGER;
n NumList := NumList(1,3,5,7);
PROCEDURE print_count_and_last IS
BEGIN
DBMS_OUTPUT.PUT('n.COUNT = ' || n.COUNT || ', ');
DBMS_OUTPUT.PUT_LINE('n.LAST = ' || n.LAST);
END print_count_and_last;
BEGIN
print_count_and_last;
n.DELETE(3); -- Delete third element
print_count_and_last;
n.EXTEND(2); -- Add two null elements to end
print_count_and_last;
FOR i IN 1..8 LOOP
IF n.EXISTS(i) THEN
IF n(i) IS NOT NULL THEN
DBMS_OUTPUT.PUT_LINE('n(' || i || ') = ' || n(i));
ELSE
DBMS_OUTPUT.PUT_LINE('n(' || i || ') = NULL');
END IF;
ELSE
DBMS_OUTPUT.PUT_LINE('n(' || i || ') does not exist');
END IF;
END LOOP;
END;
/
Result:
n.COUNT = 4, n.LAST = 4 n.COUNT = 3, n.LAST = 4 n.COUNT = 5, n.LAST = 6 n(1) = 1 n(2) = 3 n(3) does not exist n(4) = 7 n(5) = NULL n(6) = NULL n(7) does not exist n(8) does not exist
LIMIT is a function that returns the maximum number of elements that the collection can have. If the collection has no maximum number of elements, LIMIT returns NULL. Only a varray has a maximum size.
Example 5-28 and prints the values of LIMIT and COUNT for an associative array with four elements, a varray with two elements, and a nested table with three elements.
Example 5-28 LIMIT and COUNT Values for Different Collection Types
DECLARE
TYPE aa_type IS TABLE OF INTEGER INDEX BY PLS_INTEGER;
aa aa_type; -- associative array
TYPE va_type IS VARRAY(4) OF INTEGER;
va va_type := va_type(2,4); -- varray
TYPE nt_type IS TABLE OF INTEGER;
nt nt_type := nt_type(1,3,5); -- nested table
BEGIN
aa(1):=3; aa(2):=6; aa(3):=9; aa(4):= 12;
DBMS_OUTPUT.PUT('aa.COUNT = '); print(aa.COUNT);
DBMS_OUTPUT.PUT('aa.LIMIT = '); print(aa.LIMIT);
DBMS_OUTPUT.PUT('va.COUNT = '); print(va.COUNT);
DBMS_OUTPUT.PUT('va.LIMIT = '); print(va.LIMIT);
DBMS_OUTPUT.PUT('nt.COUNT = '); print(nt.COUNT);
DBMS_OUTPUT.PUT('nt.LIMIT = '); print(nt.LIMIT);
END;
/
Result:
aa.COUNT = 4 aa.LIMIT = NULL va.COUNT = 2 va.LIMIT = 4 nt.COUNT = 3 nt.LIMIT = NULL
PRIOR and NEXT are functions that let you move backward and forward in the collection (ignoring deleted elements, even if DELETE kept placeholders for them). These methods are useful for traversing sparse collections.
Given an index:
PRIOR returns the index of the preceding existing element of the collection, if one exists. Otherwise, PRIOR returns NULL.
For any collection c, c.PRIOR(c.FIRST) returns NULL.
NEXT returns the index of the succeeding existing element of the collection, if one exists. Otherwise, NEXT returns NULL.
For any collection c, c.NEXT(c.LAST) returns NULL.
The given index need not exist. However, if the collection is a varray, then the index cannot exceed LIMIT.
Example 5-29 initializes a nested table with six elements, deletes the fourth element, and then shows the values of PRIOR and NEXT for elements 1 through 7. Elements 4 and 7 do not exist. Element 2 exists, despite its null value.
Example 5-29 PRIOR and NEXT Methods
DECLARE TYPE nt_type IS TABLE OF NUMBER; nt nt_type := nt_type(18, NULL, 36, 45, 54, 63); BEGIN nt.DELETE(4); DBMS_OUTPUT.PUT_LINE('nt(4) was deleted.'); FOR i IN 1..7 LOOP DBMS_OUTPUT.PUT('nt.PRIOR(' || i || ') = '); print(nt.PRIOR(i)); DBMS_OUTPUT.PUT('nt.NEXT(' || i || ') = '); print(nt.NEXT(i)); END LOOP; END; /
Result:
nt(4) was deleted. nt.PRIOR(1) = NULL nt.NEXT(1) = 2 nt.PRIOR(2) = 1 nt.NEXT(2) = 3 nt.PRIOR(3) = 2 nt.NEXT(3) = 5 nt.PRIOR(4) = 3 nt.NEXT(4) = 5 nt.PRIOR(5) = 3 nt.NEXT(5) = 6 nt.PRIOR(6) = 5 nt.NEXT(6) = NULL nt.PRIOR(7) = 6 nt.NEXT(7) = NULL
For an associative array indexed by string, the prior and next indexes are determined by key values, which are in sorted order (for more information, see "NLS Parameter Values Affect Associative Arrays Indexed by String"). Example 5-1 uses FIRST, NEXT, and a WHILE LOOP statement to print the elements of an associative array.
Example 5-30 prints the elements of a sparse nested table from first to last, using FIRST and NEXT, and from last to first, using LAST and PRIOR.
Example 5-30 Printing Elements of Sparse Nested Table
DECLARE
TYPE NumList IS TABLE OF NUMBER;
n NumList := NumList(1, 2, NULL, NULL, 5, NULL, 7, 8, 9, NULL);
idx INTEGER;
BEGIN
DBMS_OUTPUT.PUT_LINE('First to last:');
idx := n.FIRST;
WHILE idx IS NOT NULL LOOP
DBMS_OUTPUT.PUT('n(' || idx || ') = ');
print(n(idx));
idx := n.NEXT(idx);
END LOOP;
DBMS_OUTPUT.PUT_LINE('--------------');
DBMS_OUTPUT.PUT_LINE('Last to first:');
idx := n.LAST;
WHILE idx IS NOT NULL LOOP
DBMS_OUTPUT.PUT('n(' || idx || ') = ');
print(n(idx));
idx := n.PRIOR(idx);
END LOOP;
END;
/
Result:
First to last: n(1) = 1 n(2) = 2 n(3) = NULL n(4) = NULL n(5) = 5 n(6) = NULL n(7) = 7 n(8) = 8 n(9) = 9 n(10) = NULL -------------- Last to first: n(10) = NULL n(9) = 9 n(8) = 8 n(7) = 7 n(6) = NULL n(5) = 5 n(4) = NULL n(3) = NULL n(2) = 2 n(1) = 1
A collection type defined in a package specification is incompatible with an identically defined local or standalone collection type.
Note:
The examples in this topic define packages and procedures, which are explained in Chapter 10, "PL/SQL Packages" and Chapter 8, "PL/SQL Subprograms," respectively.In Example 5-31, the package specification and the anonymous block define the collection type NumList identically. The package defines a procedure, print_numlist, which has a NumList parameter. The anonymous block declares the variable n1 of the type pkg.NumList (defined in the package) and the variable n2 of the type NumList (defined in the block). The anonymous block can pass n1 to print_numlist, but it cannot pass n2 to print_numlist.
Example 5-31 Identically Defined Package and Local Collection Types
CREATE OR REPLACE PACKAGE pkg AS TYPE NumList IS TABLE OF NUMBER; PROCEDURE print_numlist (nums NumList); END pkg; / CREATE OR REPLACE PACKAGE BODY pkg AS PROCEDURE print_numlist (nums NumList) IS BEGIN FOR i IN nums.FIRST..nums.LAST LOOP DBMS_OUTPUT.PUT_LINE(nums(i)); END LOOP; END; END pkg; / DECLARE TYPE NumList IS TABLE OF NUMBER; -- local type identical to package type n1 pkg.NumList := pkg.NumList(2,4); -- package type n2 NumList := NumList(6,8); -- local type BEGIN pkg.print_numlist(n1); -- succeeds pkg.print_numlist(n2); -- fails END; /
Result:
pkg.print_numlist(n2); -- fails * ERROR at line 7: ORA-06550: line 7, column 3: PLS-00306: wrong number or types of arguments in call to 'PRINT_NUMLIST' ORA-06550: line 7, column 3: PL/SQL: Statement ignored
Example 5-32 defines a standalone collection type NumList that is identical to the collection type NumList defined in the package specification in Example 5-31. The anonymous block declares the variable n1 of the type pkg.NumList (defined in the package) and the variable n2 of the standalone type NumList. The anonymous block can pass n1 to print_numlist, but it cannot pass n2 to print_numlist.
Example 5-32 Identically Defined Package and Standalone Collection Types
CREATE OR REPLACE TYPE NumList IS TABLE OF NUMBER; -- standalone collection type identical to package type / DECLARE n1 pkg.NumList := pkg.NumList(2,4); -- package type n2 NumList := NumList(6,8); -- standalone type BEGIN pkg.print_numlist(n1); -- succeeds pkg.print_numlist(n2); -- fails END; /
Result:
pkg.print_numlist(n2); -- fails * ERROR at line 7: ORA-06550: line 7, column 3: PLS-00306: wrong number or types of arguments in call to 'PRINT_NUMLIST' ORA-06550: line 7, column 3: PL/SQL: Statement ignored
You can create a record variable in any of these ways:
Define a RECORD type and then declare a variable of that type.
Use %TYPE to declare a record variable of the same type as a previously declared record variable.
Use %ROWTYPE to declare a record variable that represents either a full or partial row of a database table or view.
For syntax and semantics, see "Record Variable Declaration".
For a record variable of a RECORD type, the initial value of each field is NULL unless you specify a different initial value for it when you define the type. For a record variable declared with %TYPE, each field inherits the initial value of its corresponding field in the referenced record. See Example 5-34.
For a record variable declared with %ROWTYPE, the initial value of each field is NULL. See Example 5-39.
When declaring a record constant, you must create a function that populates the record with its initial value and then invoke the function in the constant declaration, as in Example 5-33.
Example 5-33 Declaring Record Constant
CREATE OR REPLACE PACKAGE My_Types AUTHID DEFINER IS TYPE My_Rec IS RECORD (a NUMBER, b NUMBER); FUNCTION Init_My_Rec RETURN My_Rec; END My_Types; / CREATE OR REPLACE PACKAGE BODY My_Types IS FUNCTION Init_My_Rec RETURN My_Rec IS Rec My_Rec; BEGIN Rec.a := 0; Rec.b := 1; RETURN Rec; END Init_My_Rec; END My_Types; / DECLARE r CONSTANT My_Types.My_Rec := My_Types.Init_My_Rec(); BEGIN DBMS_OUTPUT.PUT_LINE('r.a = ' || r.a); DBMS_OUTPUT.PUT_LINE('r.b = ' || r.b); END; /
Result:
r.a = 0 r.b = 1 PL/SQL procedure successfully completed.
A RECORD type defined in a PL/SQL block is a local type. It is available only in the block, and is stored in the database only if the block is in a standalone or package subprogram. (Standalone and package subprograms are explained in "Nested, Package, and Standalone Subprograms").
A RECORD type defined in a package specification is a public item. You can reference it from outside the package by qualifying it with the package name (package_name.type_name). It is stored in the database until you drop the package with the DROP PACKAGE statement. (Packages are explained in Chapter 10, "PL/SQL Packages.")
You cannot create a RECORD type at schema level. Therefore, a RECORD type cannot be an ADT attribute data type.
Note:
ARECORD type defined in a package specification is incompatible with an identically defined local RECORD type (see Example 5-37).To define a RECORD type, specify its name and define its fields. To define a field, specify its name and data type. By default, the initial value of a field is NULL. You can specify the NOT NULL constraint for a field, in which case you must also specify a non-NULL initial value. Without the NOT NULL constraint, a non-NULL initial value is optional.
Example 5-34 defines a RECORD type named DeptRecTyp, specifying an initial value for each field except loc_id. Next, it declares the variable dept_rec of the type DeptRecTyp and the variable dept_rec_2 of the type dept_rec%TYPE. Finally, it prints the fields of the two record variables, showing that in both records, loc_id has the value NULL, and all other fields have their default values.
Example 5-34 RECORD Type Definition and Variable Declarations
DECLARE
TYPE DeptRecTyp IS RECORD (
dept_id NUMBER(4) NOT NULL := 10,
dept_name VARCHAR2(30) NOT NULL := 'Administration',
mgr_id NUMBER(6) := 200,
loc_id NUMBER(4)
);
dept_rec DeptRecTyp;
dept_rec_2 dept_rec%TYPE;
BEGIN
DBMS_OUTPUT.PUT_LINE('dept_rec:');
DBMS_OUTPUT.PUT_LINE('---------');
DBMS_OUTPUT.PUT_LINE('dept_id: ' || dept_rec.dept_id);
DBMS_OUTPUT.PUT_LINE('dept_name: ' || dept_rec.dept_name);
DBMS_OUTPUT.PUT_LINE('mgr_id: ' || dept_rec.mgr_id);
DBMS_OUTPUT.PUT_LINE('loc_id: ' || dept_rec.loc_id);
DBMS_OUTPUT.PUT_LINE('-----------');
DBMS_OUTPUT.PUT_LINE('dept_rec_2:');
DBMS_OUTPUT.PUT_LINE('-----------');
DBMS_OUTPUT.PUT_LINE('dept_id: ' || dept_rec.dept_id);
DBMS_OUTPUT.PUT_LINE('dept_name: ' || dept_rec.dept_name);
DBMS_OUTPUT.PUT_LINE('mgr_id: ' || dept_rec.mgr_id);
DBMS_OUTPUT.PUT_LINE('loc_id: ' || dept_rec.loc_id);
END;
/
Result:
dept_rec: --------- dept_id: 10 dept_name: Administration mgr_id: 200 loc_id: ----------- dept_rec_2: ----------- dept_id: 10 dept_name: Administration mgr_id: 200 loc_id: PL/SQL procedure successfully completed.
Example 5-35 defines two RECORD types, name_rec and contact. The type contact has a field of type name_rec.
Example 5-35 RECORD Type with RECORD Field (Nested Record)
DECLARE TYPE name_rec IS RECORD ( first employees.first_name%TYPE, last employees.last_name%TYPE ); TYPE contact IS RECORD ( name name_rec, -- nested record phone employees.phone_number%TYPE ); friend contact; BEGIN friend.name.first := 'John'; friend.name.last := 'Smith'; friend.phone := '1-650-555-1234'; DBMS_OUTPUT.PUT_LINE ( friend.name.first || ' ' || friend.name.last || ', ' || friend.phone ); END; /
Result:
John Smith, 1-650-555-1234
Example 5-36 defines a VARRAY type, full_name, and a RECORD type, contact. The type contact has a field of type full_name.
Example 5-36 RECORD Type with Varray Field
DECLARE TYPE full_name IS VARRAY(2) OF VARCHAR2(20); TYPE contact IS RECORD ( name full_name := full_name('John', 'Smith'), -- varray field phone employees.phone_number%TYPE ); friend contact; BEGIN friend.phone := '1-650-555-1234'; DBMS_OUTPUT.PUT_LINE ( friend.name(1) || ' ' || friend.name(2) || ', ' || friend.phone ); END; /
Result:
John Smith, 1-650-555-1234
A RECORD type defined in a package specification is incompatible with an identically defined local RECORD type.
Note:
The example in this topic defines a package and a procedure, which are explained in Chapter 10, "PL/SQL Packages" and Chapter 8, "PL/SQL Subprograms," respectively.In Example 5-37, the package pkg and the anonymous block define the RECORD type rec_type identically. The package defines a procedure, print_rec_type, which has a rec_type parameter. The anonymous block declares the variable r1 of the package type (pkg.rec_type) and the variable r2 of the local type (rec_type). The anonymous block can pass r1 to print_rec_type, but it cannot pass r2 to print_rec_type.
Example 5-37 Identically Defined Package and Local RECORD Types
CREATE OR REPLACE PACKAGE pkg AS TYPE rec_type IS RECORD ( -- package RECORD type f1 INTEGER, f2 VARCHAR2(4) ); PROCEDURE print_rec_type (rec rec_type); END pkg; / CREATE OR REPLACE PACKAGE BODY pkg AS PROCEDURE print_rec_type (rec rec_type) IS BEGIN DBMS_OUTPUT.PUT_LINE(rec.f1); DBMS_OUTPUT.PUT_LINE(rec.f2); END; END pkg; / DECLARE TYPE rec_type IS RECORD ( -- local RECORD type f1 INTEGER, f2 VARCHAR2(4) ); r1 pkg.rec_type; -- package type r2 rec_type; -- local type BEGIN r1.f1 := 10; r1.f2 := 'abcd'; r2.f1 := 25; r2.f2 := 'wxyz'; pkg.print_rec_type(r1); -- succeeds pkg.print_rec_type(r2); -- fails END; /
Result:
pkg.print_rec_type(r2); -- fails * ERROR at line 14: ORA-06550: line 14, column 3: PLS-00306: wrong number or types of arguments in call to 'PRINT_REC_TYPE' ORA-06550: line 14, column 3: PL/SQL: Statement ignored
The %ROWTYPE attribute lets you declare a record variable that represents either a full or partial row of a database table or view. For every column of the full or partial row, the record has a field with the same name and data type. If the structure of the row changes, then the structure of the record changes accordingly.
The record fields do not inherit the constraints or initial values of the corresponding columns (see Example 5-39).
To declare a record variable that always represents a full row of a database table or view, use this syntax:
variable_name table_or_view_name%ROWTYPE;
For every column of the table or view, the record has a field with the same name and data type.
Example 5-38 declares a record variable that represents a row of the table departments, assigns values to its fields, and prints them. Compare this example to Example 5-34.
Example 5-38 %ROWTYPE Variable Represents Full Database Table Row
DECLARE
dept_rec departments%ROWTYPE;
BEGIN
-- Assign values to fields:
dept_rec.department_id := 10;
dept_rec.department_name := 'Administration';
dept_rec.manager_id := 200;
dept_rec.location_id := 1700;
-- Print fields:
DBMS_OUTPUT.PUT_LINE('dept_id: ' || dept_rec.department_id);
DBMS_OUTPUT.PUT_LINE('dept_name: ' || dept_rec.department_name);
DBMS_OUTPUT.PUT_LINE('mgr_id: ' || dept_rec.manager_id);
DBMS_OUTPUT.PUT_LINE('loc_id: ' || dept_rec.location_id);
END;
/
Result:
dept_id: 10 dept_name: Administration mgr_id: 200 loc_id: 1700
Example 5-39 creates a table with two columns, each with an initial value and a NOT NULL constraint. Then it declares a record variable that represents a row of the table and prints its fields, showing that they did not inherit the initial values or NOT NULL constraints.
Example 5-39 %ROWTYPE Variable Does Not Inherit Initial Values or Constraints
DROP TABLE t1; CREATE TABLE t1 ( c1 INTEGER DEFAULT 0 NOT NULL, c2 INTEGER DEFAULT 1 NOT NULL ); DECLARE t1_row t1%ROWTYPE; BEGIN DBMS_OUTPUT.PUT('t1.c1 = '); print(t1_row.c1); DBMS_OUTPUT.PUT('t1.c2 = '); print(t1_row.c2); END; /
Result:
t1.c1 = NULL t1.c2 = NULL
To declare a record variable that can represent a partial row of a database table or view, use this syntax:
variable_name cursor%ROWTYPE;
A cursor is associated with a query. For every column that the query selects, the record variable must have a corresponding, type-compatible field. If the query selects every column of the table or view, then the variable represents a full row; otherwise, the variable represents a partial row. The cursor must be either an explicit cursor or a strong cursor variable.
See Also:
"FETCH Statement" for complete syntax
"Cursors" for information about cursors
"Explicit Cursors" for information about explicit cursors
"Cursor Variables" for information about cursor variables
Example 5-40 defines an explicit cursor whose query selects only the columns first_name, last_name, and phone_number from the employees table in the sample schema HR. Then the example declares a record variable that has a field for each column that the cursor selects. The variable represents a partial row of employees. Compare this example to Example 5-35.
Example 5-40 %ROWTYPE Variable Represents Partial Database Table Row
DECLARE
CURSOR c IS
SELECT first_name, last_name, phone_number
FROM employees;
friend c%ROWTYPE;
BEGIN
friend.first_name := 'John';
friend.last_name := 'Smith';
friend.phone_number := '1-650-555-1234';
DBMS_OUTPUT.PUT_LINE (
friend.first_name || ' ' ||
friend.last_name || ', ' ||
friend.phone_number
);
END;
/
Result:
John Smith, 1-650-555-1234
Example 5-40 defines an explicit cursor whose query is a join and then declares a record variable that has a field for each column that the cursor selects. (For information about joins, see Oracle Database SQL Language Reference.)
Note:
In this topic, record variable means either a record variable or a record component of a composite variable (for example,friend.name in Example 5-35).To any record variable, you can assign a value to each field individually.
In some cases, you can assign the value of one record variable to another record variable.
If a record variable represents a full or partial row of a database table or view, you can assign the represented row to the record variable.
You can assign the value of one record variable to another record variable only in these cases:
The two variables have the same RECORD type (as in Example 5-42).
The target variable is declared with a RECORD type, the source variable is declared with %ROWTYPE, their fields match in number and order, and corresponding fields have the same data type (as in Example 5-43).
For record components of composite variables, the types of the composite variables need not match (see Example 5-44).
Example 5-42 Assigning Record to Another Record of Same RECORD Type
DECLARE
TYPE name_rec IS RECORD (
first employees.first_name%TYPE DEFAULT 'John',
last employees.last_name%TYPE DEFAULT 'Doe'
);
name1 name_rec;
name2 name_rec;
BEGIN
name1.first := 'Jane'; name1.last := 'Smith';
DBMS_OUTPUT.PUT_LINE('name1: ' || name1.first || ' ' || name1.last);
name2 := name1;
DBMS_OUTPUT.PUT_LINE('name2: ' || name2.first || ' ' || name2.last);
END;
/
Result:
name1: Jane Smith name2: Jane Smith
Example 5-43 Assigning %ROWTYPE Record to RECORD Type Record
DECLARE
TYPE name_rec IS RECORD (
first employees.first_name%TYPE DEFAULT 'John',
last employees.last_name%TYPE DEFAULT 'Doe'
);
CURSOR c IS
SELECT first_name, last_name
FROM employees;
target name_rec;
source c%ROWTYPE;
BEGIN
source.first_name := 'Jane'; source.last_name := 'Smith';
DBMS_OUTPUT.PUT_LINE (
'source: ' || source.first_name || ' ' || source.last_name
);
target := source;
DBMS_OUTPUT.PUT_LINE (
'target: ' || target.first || ' ' || target.last
);
END;
/
Result:
source: Jane Smith target: Jane Smith
Example 5-44 assigns the value of one nested record to another nested record. The nested records have the same RECORD type, but the records in which they are nested do not.
Example 5-44 Assigning Nested Record to Another Record of Same RECORD Type
DECLARE
TYPE name_rec IS RECORD (
first employees.first_name%TYPE,
last employees.last_name%TYPE
);
TYPE phone_rec IS RECORD (
name name_rec, -- nested record
phone employees.phone_number%TYPE
);
TYPE email_rec IS RECORD (
name name_rec, -- nested record
email employees.email%TYPE
);
phone_contact phone_rec;
email_contact email_rec;
BEGIN
phone_contact.name.first := 'John';
phone_contact.name.last := 'Smith';
phone_contact.phone := '1-650-555-1234';
email_contact.name := phone_contact.name;
email_contact.email := (
email_contact.name.first || '.' ||
email_contact.name.last || '@' ||
'example.com'
);
DBMS_OUTPUT.PUT_LINE (email_contact.email);
END;
/
Result:
John.Smith@example.com
If a record variable represents a full or partial row of a database table or view, you can assign the represented row to the record variable.
The syntax of a simple SELECT INTO statement is:
SELECT select_list INTO record_variable_name FROM table_or_view_name;
For each column in select_list, the record variable must have a corresponding, type-compatible field. The columns in select_list must appear in the same order as the record fields.
See Also:
"SELECT INTO Statement" for complete syntaxIn Example 5-45, the record variable rec1 represents a partial row of the employees table—the columns last_name and employee_id. The SELECT INTO statement selects from employees the row for which job_id is 'AD_PRES' and assigns the values of the columns last_name and employee_id in that row to the corresponding fields of rec1.
Example 5-45 SELECT INTO Assigns Values to Record Variable
DECLARE
TYPE RecordTyp IS RECORD (
last employees.last_name%TYPE,
id employees.employee_id%TYPE
);
rec1 RecordTyp;
BEGIN
SELECT last_name, employee_id INTO rec1
FROM employees
WHERE job_id = 'AD_PRES';
DBMS_OUTPUT.PUT_LINE ('Employee #' || rec1.id || ' = ' || rec1.last);
END;
/
Result:
Employee #100 = King
The syntax of a simple FETCH statement is:
FETCH cursor INTO record_variable_name;
A cursor is associated with a query. For every column that the query selects, the record variable must have a corresponding, type-compatible field. The cursor must be either an explicit cursor or a strong cursor variable.
See Also:
"FETCH Statement" for complete syntax
"Cursors" for information about all cursors
"Explicit Cursors" for information about explicit cursors
"Cursor Variables" for information about cursor variables
In Example 5-46, each variable of RECORD type EmpRecTyp represents a partial row of the employees table—the columns employee_id and salary. Both the cursor and the function return a value of type EmpRecTyp. In the function, a FETCH statement assigns the values of the columns employee_id and salary to the corresponding fields of a local variable of type EmpRecTyp.
Example 5-46 FETCH Assigns Values to Record that Function Returns
DECLARE
TYPE EmpRecTyp IS RECORD (
emp_id employees.employee_id%TYPE,
salary employees.salary%TYPE
);
CURSOR desc_salary RETURN EmpRecTyp IS
SELECT employee_id, salary
FROM employees
ORDER BY salary DESC;
highest_paid_emp EmpRecTyp;
next_highest_paid_emp EmpRecTyp;
FUNCTION nth_highest_salary (n INTEGER) RETURN EmpRecTyp IS
emp_rec EmpRecTyp;
BEGIN
OPEN desc_salary;
FOR i IN 1..n LOOP
FETCH desc_salary INTO emp_rec;
END LOOP;
CLOSE desc_salary;
RETURN emp_rec;
END nth_highest_salary;
BEGIN
highest_paid_emp := nth_highest_salary(1);
next_highest_paid_emp := nth_highest_salary(2);
DBMS_OUTPUT.PUT_LINE(
'Highest Paid: #' ||
highest_paid_emp.emp_id || ', $' ||
highest_paid_emp.salary
);
DBMS_OUTPUT.PUT_LINE(
'Next Highest Paid: #' ||
next_highest_paid_emp.emp_id || ', $' ||
next_highest_paid_emp.salary
);
END;
/
Result:
Highest Paid: #100, $26460 Next Highest Paid: #101, $18742.5
The SQL statements INSERT, UPDATE, and DELETE have an optional RETURNING INTO clause that can return the affected row in a PL/SQL record variable. For information about this clause, see "RETURNING INTO Clause".
In Example 5-47, the UPDATE statement updates the salary of an employee and returns the name and new salary of the employee in a record variable.
Example 5-47 UPDATE Statement Assigns Values to Record Variable
DECLARE
TYPE EmpRec IS RECORD (
last_name employees.last_name%TYPE,
salary employees.salary%TYPE
);
emp_info EmpRec;
old_salary employees.salary%TYPE;
BEGIN
SELECT salary INTO old_salary
FROM employees
WHERE employee_id = 100;
UPDATE employees
SET salary = salary * 1.1
WHERE employee_id = 100
RETURNING last_name, salary INTO emp_info;
DBMS_OUTPUT.PUT_LINE (
'Salary of ' || emp_info.last_name || ' raised from ' ||
old_salary || ' to ' || emp_info.salary
);
END;
/
Result:
Salary of King raised from 26460 to 29106
Assigning the value NULL to a record variable assigns the value NULL to each of its fields. This assignment is recursive; that is, if a field is a record, then its fields are also assigned the value NULL.
Example 5-48 prints the fields of a record variable (one of which is a record) before and after assigning NULL to it.
Example 5-48 Assigning NULL to Record Variable
DECLARE
TYPE age_rec IS RECORD (
years INTEGER DEFAULT 35,
months INTEGER DEFAULT 6
);
TYPE name_rec IS RECORD (
first employees.first_name%TYPE DEFAULT 'John',
last employees.last_name%TYPE DEFAULT 'Doe',
age age_rec
);
name name_rec;
PROCEDURE print_name AS
BEGIN
DBMS_OUTPUT.PUT(NVL(name.first, 'NULL') || ' ');
DBMS_OUTPUT.PUT(NVL(name.last, 'NULL') || ', ');
DBMS_OUTPUT.PUT(NVL(TO_CHAR(name.age.years), 'NULL') || ' yrs ');
DBMS_OUTPUT.PUT_LINE(NVL(TO_CHAR(name.age.months), 'NULL') || ' mos');
END;
BEGIN
print_name;
name := NULL;
print_name;
END;
/
Result:
John Doe, 35 yrs 6 mos NULL NULL, NULL yrs NULL mos
Records cannot be tested natively for nullity, equality, or inequality. These BOOLEAN expressions are illegal:
My_Record IS NULL
My_Record_1 = My_Record_2
My_Record_1 > My_Record_2
You must write your own functions to implement such tests. For information about writing functions, see Chapter 8, "PL/SQL Subprograms."
The PL/SQL extension to the SQL INSERT statement lets you insert a record into a table. The record must represent a row of the table. For more information, see "INSERT Statement Extension". For restrictions on inserting records into tables, see "Restrictions on Record Inserts and Updates".
Example 5-49 creates the table schedule and initializes it by putting default values in a record and inserting the record into the table for each week. (The COLUMN formatting commands are from SQL*Plus.)
Example 5-49 Initializing Table by Inserting Record of Default Values
DROP TABLE schedule;
CREATE TABLE schedule (
week NUMBER,
Mon VARCHAR2(10),
Tue VARCHAR2(10),
Wed VARCHAR2(10),
Thu VARCHAR2(10),
Fri VARCHAR2(10),
Sat VARCHAR2(10),
Sun VARCHAR2(10)
);
DECLARE
default_week schedule%ROWTYPE;
i NUMBER;
BEGIN
default_week.Mon := '0800-1700';
default_week.Tue := '0800-1700';
default_week.Wed := '0800-1700';
default_week.Thu := '0800-1700';
default_week.Fri := '0800-1700';
default_week.Sat := 'Day Off';
default_week.Sun := 'Day Off';
FOR i IN 1..6 LOOP
default_week.week := i;
INSERT INTO schedule VALUES default_week;
END LOOP;
END;
/
COLUMN week FORMAT 99
COLUMN Mon FORMAT A9
COLUMN Tue FORMAT A9
COLUMN Wed FORMAT A9
COLUMN Thu FORMAT A9
COLUMN Fri FORMAT A9
COLUMN Sat FORMAT A9
COLUMN Sun FORMAT A9
SELECT * FROM schedule;
Result:
WEEK MON TUE WED THU FRI SAT SUN ---- --------- --------- --------- --------- --------- --------- --------- 1 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 2 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 3 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 4 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 5 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 6 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off
To efficiently insert a collection of records into a table, put the INSERT statement inside a FORALL statement. For information about the FORALL statement, see "FORALL Statement".
The PL/SQL extension to the SQL UPDATE statement lets you update one or more table rows with a record. The record must represent a row of the table. For more information, see "UPDATE Statement Extensions". For restrictions on updating table rows with a record, see "Restrictions on Record Inserts and Updates".
Example 5-50 updates the first three weeks of the table schedule (defined in Example 5-49) by putting the new values in a record and updating the first three rows of the table with that record.
Example 5-50 Updating Rows with Record
DECLARE
default_week schedule%ROWTYPE;
BEGIN
default_week.Mon := 'Day Off';
default_week.Tue := '0900-1800';
default_week.Wed := '0900-1800';
default_week.Thu := '0900-1800';
default_week.Fri := '0900-1800';
default_week.Sat := '0900-1800';
default_week.Sun := 'Day Off';
FOR i IN 1..3 LOOP
default_week.week := i;
UPDATE schedule
SET ROW = default_week
WHERE week = i;
END LOOP;
END;
/
SELECT * FROM schedule;
Result:
WEEK MON TUE WED THU FRI SAT SUN ---- --------- --------- --------- --------- --------- --------- --------- 1 Day Off 0900-1800 0900-1800 0900-1800 0900-1800 0900-1800 Day Off 2 Day Off 0900-1800 0900-1800 0900-1800 0900-1800 0900-1800 Day Off 3 Day Off 0900-1800 0900-1800 0900-1800 0900-1800 0900-1800 Day Off 4 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 5 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off 6 0800-1700 0800-1700 0800-1700 0800-1700 0800-1700 Day Off Day Off
To efficiently update a set of rows with a collection of records, put the UPDATE statement inside a FORALL statement. For information about the FORALL statement, see "FORALL Statement".
These restrictions apply to record inserts and updates:
Record variables are allowed only in these places:
On the right side of the SET clause in an UPDATE statement
In the VALUES clause of an INSERT statement
In the INTO subclause of a RETURNING clause
Record variables are not allowed in a SELECT list, WHERE clause, GROUP BY clause, or ORDER BY clause.
The keyword ROW is allowed only on the left side of a SET clause. Also, you cannot use ROW with a subquery.
In an UPDATE statement, only one SET clause is allowed if ROW is used.
If the VALUES clause of an INSERT statement contains a record variable, no other variable or value is allowed in the clause.
If the INTO subclause of a RETURNING clause contains a record variable, no other variable or value is allowed in the subclause.
These are not supported:
Nested RECORD types
Functions that return a RECORD type
Record inserts and updates using the EXECUTE IMMEDIATE statement.
|
Copyright © 1996, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|