Scheduling¶
All of the large-scale Dask collections like Dask Array, Dask DataFrame, and Dask Bag and the fine-grained APIs like delayed and futures generate task graphs where each node in the graph is a normal Python function and edges between nodes are normal Python objects that are created by one task as outputs and used as inputs in another task. After Dask generates these task graphs, it needs to execute them on parallel hardware. This is the job of a task scheduler. Different task schedulers exist, and each will consume a task graph and compute the same result, but with different performance characteristics.
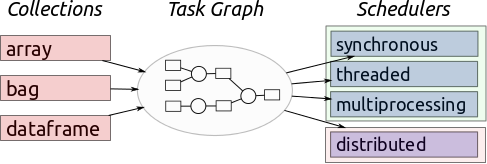
Dask has two families of task schedulers:
Single machine scheduler: This scheduler provides basic features on a local process or thread pool. This scheduler was made first and is the default. It is simple and cheap to use, although it can only be used on a single machine and does not scale
Distributed scheduler: This scheduler is more sophisticated, offers more features, but also requires a bit more effort to set up. It can run locally or distributed across a cluster
For different computations you may find better performance with particular scheduler settings. This document helps you understand how to choose between and configure different schedulers, and provides guidelines on when one might be more appropriate.
Local Threads¶
import dask
dask.config.set(scheduler='threads') # overwrite default with threaded scheduler
The threaded scheduler executes computations with a local multiprocessing.pool.ThreadPool.
It is lightweight and requires no setup.
It introduces very little task overhead (around 50us per task)
and, because everything occurs in the same process,
it incurs no costs to transfer data between tasks.
However, due to Python’s Global Interpreter Lock (GIL),
this scheduler only provides parallelism when your computation is dominated by non-Python code,
as is primarily the case when operating on numeric data in NumPy arrays, Pandas DataFrames,
or using any of the other C/C++/Cython based projects in the ecosystem.
The threaded scheduler is the default choice for Dask Array, Dask DataFrame, and Dask Delayed. However, if your computation is dominated by processing pure Python objects like strings, dicts, or lists, then you may want to try one of the process-based schedulers below (we currently recommend the distributed scheduler on a local machine).
Local Processes¶
Note
The distributed scheduler described a couple sections below is often a better choice today. We encourage readers to continue reading after this section.
import dask.multiprocessing
dask.config.set(scheduler='processes') # overwrite default with multiprocessing scheduler
The multiprocessing scheduler executes computations with a local multiprocessing.Pool.
It is lightweight to use and requires no setup.
Every task and all of its dependencies are shipped to a local process,
executed, and then their result is shipped back to the main process.
This means that it is able to bypass issues with the GIL and provide parallelism
even on computations that are dominated by pure Python code,
such as those that process strings, dicts, and lists.
However, moving data to remote processes and back can introduce performance penalties, particularly when the data being transferred between processes is large. The multiprocessing scheduler is an excellent choice when workflows are relatively linear, and so does not involve significant inter-task data transfer as well as when inputs and outputs are both small, like filenames and counts.
This is common in basic data ingestion workloads, such as those are common in Dask Bag, where the multiprocessing scheduler is the default:
>>> import dask.bag as db
>>> db.read_text('*.json').map(json.loads).pluck('name').frequencies().compute()
{'alice': 100, 'bob': 200, 'charlie': 300}
For more complex workloads, where large intermediate results may be depended upon by multiple downstream tasks, we generally recommend the use of the distributed scheduler on a local machine. The distributed scheduler is more intelligent about moving around large intermediate results.
Single Thread¶
import dask
dask.config.set(scheduler='synchronous') # overwrite default with single-threaded scheduler
The single-threaded synchronous scheduler executes all computations in the local thread with no parallelism at all. This is particularly valuable for debugging and profiling, which are more difficult when using threads or processes.
For example, when using IPython or Jupyter notebooks, the %debug, %pdb, or %prun magics
will not work well when using the parallel Dask schedulers
(they were not designed to be used in a parallel computing context).
However, if you run into an exception and want to step into the debugger,
you may wish to rerun your computation under the single-threaded scheduler
where these tools will function properly.
Dask Distributed (local)¶
from dask.distributed import Client
client = Client()
# or
client = Client(processes=False)
The Dask distributed scheduler can either be setup on a cluster or run locally on a personal machine. Despite having the name “distributed”, it is often pragmatic on local machines for a few reasons:
It provides access to asynchronous API, notably Futures
It provides a diagnostic dashboard that can provide valuable insight on performance and progress
It handles data locality with more sophistication, and so can be more efficient than the multiprocessing scheduler on workloads that require multiple processes
You can read more about using the Dask distributed scheduler on a single machine in these docs.
Dask Distributed (Cluster)¶
You can also run Dask on a distributed cluster. There are a variety of ways to set this up depending on your cluster. We recommend referring to the setup documentation for more information.
Configuration¶
You can configure the global default scheduler by using the dask.config.set(scheduler...) command.
This can be done globally:
dask.config.set(scheduler='threads')
x.compute()
or as a context manager:
with dask.config.set(scheduler='threads'):
x.compute()
or within a single compute call:
x.compute(scheduler='threads')
Additionally some of the scheduler support other keyword arguments. For example, the pool-based single-machine scheduler allows you to provide custom pools or specify the desired number of workers:
from multiprocessing.pool import ThreadPool
with dask.config.set(pool=ThreadPool(4)):
...
with dask.config.set(num_workers=4):
...