| Oracle® Database Administrator's Guide 11g Release 2 (11.2) Part Number E25494-02 |
|
|
PDF · Mobi · ePub |
| Oracle® Database Administrator's Guide 11g Release 2 (11.2) Part Number E25494-02 |
|
|
PDF · Mobi · ePub |
This section contains:
See Also:
The Scheduler supports the following types of jobs:
Database jobs run Oracle Database program units, including PL/SQL anonymous blocks, PL/SQL stored procedures, and Java stored procedures. For a database job where the action is specified inline, job_type is set to 'PLSQL_BLOCK' or 'STORED_PROCEDURE', and job_action contains either the text of a PL/SQL anonymous block or the name of a stored procedure. (If a program is a named program object rather than program action specified inline, the corresponding program_type and program_action must be set accordingly.)
Database jobs that run on the originating database—the database on which they were created—are known as local database jobs, or just jobs. Database jobs that run on a target database other than the originating database are known as remote database jobs.
You can view run results for both local database and remote database jobs in the job log views on the originating database.
A local database job runs on the originating database, as the database user who is the job owner. The job owner is the name of the schema in which the job was created.
The target database for a remote database job can be an Oracle database on a remote host or another database instance on the same host as the originating database. You identify a remote database job by specifying the name of an existing database destination object in the destination_name attribute of the job.
Creating a remote database job requires Oracle Database 11g Release 2 or later. However, the target database for the job can be any release of Oracle Database. No patch is required for the target database; you only need to install a Scheduler agent on the target database host (even if the target database host is the same as the originating database host) and register the agent with the originating database. The agent must be installed from Oracle Client 11g Release 2 or higher.
Remote database jobs must run as a user that is valid on the target database. You specify the required user name and password with a credential object that you assign to the remote database job.
External jobs run external executables. An external executable is an operating system executable that runs outside the database, that is, external to the database. For an external job, job_type is specified as 'EXECUTABLE'. (If using named programs, the corresponding program_type would be 'EXECUTABLE'.) The job_action (or corresponding program_action) is the full operating system–dependent path of the desired external executable, excluding any command line arguments. An example might be /usr/local/bin/perl or C:\perl\bin\perl.
Note that a Windows batch file is not directly executable and must be run a command prompt (cmd.exe).
Like a database job, you can assign a schema when you create the external job. That schema then becomes the job owner. Although it is possible to create an external job in the SYS schema, Oracle recommends against this practice.
Both the CREATE JOB and CREATE EXTERNAL JOB privileges are required to create local or remote external jobs.
External executables must run as some operating system user. Thus, the Scheduler enables you to assign operating system credentials to any external job that you create. Like remote database jobs, you specify these credentials with a Scheduler credential object (a credential) and assign the credential to the external job.
There are two types of external jobs: local external jobs and remote external jobs. A local external job runs its external executable on the same computer as the database that schedules the job. A remote external job runs its executable on a remote host. The remote host does not need to have an Oracle database; you need only install and register a Scheduler agent.
Note:
On Windows, the host user that runs the external executable must be assigned theLog on as a batch job logon privilege.The following sections provide more details on local external jobs and remote external jobs:
A local external job runs its external executable on the same computer as the Oracle database that schedules the job. For such a job, the destination_name job attribute is NULL.
Local external jobs write stdout and stderr output to log files in the directory ORACLE_HOME/scheduler/log. You can retrieve the contents of these files with DBMS_SCHEDULER.GET_FILE.
You do not have to assign a credential to a local external job, although Oracle strongly recommends that you do so for improved security. If you do not assign a credential, the job runs with default credentials. Table 28-1 shows the default credentials for different platforms and different job owners.
Table 28-1 Default Credentials for Local External Jobs
| Job in SYS Schema? | Platform | Default Credentials |
|---|---|---|
|
Yes |
All |
User who installed Oracle Database. |
|
No |
UNIX and Linux |
Values of the |
|
No |
Windows |
User that the Note: You must manually enable and start this service. For improved security, Oracle recommends using a named user instead of the Local System account. |
Note:
Default credentials are included for compatibility with previous releases of Oracle Database, and may be deprecated in a future release. It is, therefore, best to assign a credential to every local external job.To disable the running of local external jobs that were not assigned credentials, remove the run_user attribute from the ORACLE_HOME/rdbms/admin/externaljob.ora file (UNIX and Linux) or stop the OracleJobScheduler service (Windows). These steps do not disable the running of local external jobs in the SYS schema.
See Also:
Your operating system–specific documentation for any post-installation configuration steps to support local external jobs
Example 29-8, "Creating a Local External Job and Retrieving stdout"
A remote external job runs its external executable on a remote host. The remote host may or may not have Oracle Database installed. To enable remote external jobs to run on a specific remote host, you must install a Scheduler agent on the remote host and register it with the local database. The database communicates with the agent to start external executables and to retrieve execution results.
When creating a remote external job, you specify the name of an existing external destination object in the destination_name attribute of the job.
Remote external jobs write stdout and stderr output to log files in the directory AGENT_HOME/data/log. You can retrieve the contents of these files with DBMS_SCHEDULER.GET_FILE. Example 29-8, "Creating a Local External Job and Retrieving stdout" illustrates how to retrieve stdout output. Although this example is for a local external job, the method is the same for remote external jobs.
A multiple-destination job is a job whose instances run on multiple target databases or hosts, but can be controlled and monitored from one central database. For DBAs or system administrators who must manage multiple databases or multiple hosts, a multiple-destination job can make administration considerably easier. With a multiple-destination job, you can:
Specify several databases or hosts on which a job must run.
Modify a job that is scheduled on multiple targets with a single operation.
Stop jobs running on one or more remote targets.
Determine the status (running, completed, failed, and so on) of the job instance at each of the remote targets.
Determine the overall status of the collection of job instances.
A multiple-destination job can be viewed as a single entity for certain purposes and as a collection of independently running jobs for other purposes. When creating or altering the job metadata, the multiple-destination job looks like a single entity. However, when the job instances are running, they are better viewed as a collection of jobs that are nearly identical copies of each other. The job created at the source database is known as the parent job, and the job instances that run at the various destinations are known as child jobs.
You create a multiple-destination job by assigning a destination group to the destination_name attribute of the job. The job runs at all destinations in the group at its scheduled time, or upon the detection of a specified event. The local host can be included as one of the destinations on which the job runs.
For a job whose action is a database program unit, you must specify a database destination group in the destination_name attribute. The members of a database destination group include database destinations and the keyword LOCAL, which indicates the originating (local) database. For a job whose action is an external executable, you must specify an external destination group in the destination_name attribute. The members of an external destination group include external destinations and the keyword LOCAL, which indicates the local host.
Note:
Database destinations do not necessarily have to reference remote databases; they can reference additional database instances running on the same host as the database that creates the job.Multiple-Destination Jobs and Time Zones
Some job destinations might be in time zones that are different from that of the database on which the parent job is created (the originating database). In this case, the start time of the job is always based on the time zone of the originating database. So, if you create the parent job in London, England, specify a start time of 8:00 p.m., and specify destinations at Tokyo, Los Angeles, and New York, then all child jobs start at 8:00 p.m. London time. Start times at all destinations may not be exact, due to varying system loads, issues that require retries, and so on.
Event-Based Multiple-Destination Jobs
In the case of a multiple-destination job that is event-based, when the parent job detects the event at its host, it starts all the child jobs at all destinations. The child jobs themselves do not detect events at their respective hosts.
The chain is the Scheduler mechanism that enables dependency-based scheduling. In its simplest form, it defines a group of program objects and the dependencies among them. A job can point to a chain instead of pointing to a single program object. The job then serves to start the chain. For a chain job, job_type is set to 'CHAIN'.
See Also:
You use a detached job to start a script or application that runs in a separate process, independently and asynchronously to the Scheduler. A detached job typically starts another process and then exits. Upon exit (when the job action is completed) a detached job remains in the running state. The running state indicates that the asynchronous process that the job started is still active. When the asynchronous process finishes its work, it must connect to the database and call DBMS_SCHEDULER.END_DETACHED_JOB_RUN, which ends the job.
Detached jobs cannot be executed using run_job to manually trigger execution, when the use_current_session parameter set to TRUE.
A job is detached if it points to a program object (program) that has its detached attribute set to TRUE (a detached program).
You use a detached job under the following two circumstances:
When it is impractical to wait for the launched asynchronous process to complete because would hold resources unnecessarily.
An example is sending a request to an asynchronous Web service. It could take hours or days for the Web service to respond, and you do not want to hold a Scheduler job slave while waiting for the response. (See "Scheduler Architecture" for information about job slaves.)
When it is impossible to wait for the launched asynchronous process to complete because the process shuts down the database.
An example would be using a Scheduler job to launch an RMAN script that shuts down the database, makes a cold backup, and then restarts the database. See Example 29-5.
A detached job works as follows:
When it is time for the job to start, the job coordinator assigns a job slave to the job, and the job slave runs the program action defined in the detached program. The program action can be a PL/SQL block, a stored procedure, or an external executable.
The program action performs an immediate-return call of another script or executable, referred to here as Process A, and then exits. Because the work of the program action is complete, the job slave exits, but leaves the job in a running state.
Process A performs its processing. If it runs any DML against the database, it must commit its work. When processing is complete, Process A logs in to the database and calls END_DETACHED_JOB_RUN.
The detached job is logged as completed.
You can also call STOP_JOB to end a running detached job.
See Also:
"Creating Detached Jobs" for an example of performing a cold backup of the database with a detached jobUse lightweight jobs when you have many short-duration jobs that run frequently. Under certain circumstances, using lightweight jobs can deliver a small performance gain.
Lightweight jobs have the following characteristics:
Unlike regular jobs, they are not schema objects.
They have significantly better create and drop times over regular jobs because they do not have the overhead of creating a schema object.
They have lower average session create time than regular jobs.
They have a small footprint on disk for job metadata and run-time data.
You designate a lightweight job by setting the job_style job attribute to 'LIGHTWEIGHT'. The other job style is 'REGULAR', which is the default.
Like programs and schedules, regular jobs are schema objects. In releases before Oracle Database 11g Release 1, the only job style supported by the Scheduler was regular.
A regular job offers the maximum flexibility but does entail some overhead when it is created or dropped. The user has fine-grained control of the privileges on the job, and the job can have as its action a program or a stored procedure owned by another user.
If a relatively small number of jobs that run infrequently need to be created, then regular jobs are preferred over lightweight jobs.
A lightweight job must reference a program object (program) to specify a job action. The program must be already enabled when the lightweight job is created, and the program type must be either 'PLSQL_BLOCK' or 'STORED_PROCEDURE'. Because lightweight jobs are not schema objects, you cannot grant privileges on them. A lightweight job inherits privileges from its specified program. Thus, any user who has a certain set of privileges on the program has corresponding privileges on the lightweight job.
See Also:
"Creating Jobs" and "Examples of Using the Scheduler" for examples of creating lightweight jobsA job instance represents a specific run of a job. Jobs that are scheduled to run only once have only one instance. Jobs that have a repeating schedule or that run each time an event occurs have multiple instances, each run of the job representing an instance. For example, a job that is scheduled to run only on Tuesday, Oct. 8th 2009 has one instance, a job that runs daily at noon for a week has seven instances, and a job that runs when a file arrives on a remote system has one instance for each file arrival event.
Multiple-destination jobs have one instance for each destination. If a multiple-destination job has a repeating schedule, then there is one instance for each run of the job at each destination.
When a job is created, only one entry is added to the Scheduler's job table to represent the job. Depending on the logging level set, each time the job runs, an entry is added to the job log. Therefore, if you create a job that has a repeating schedule, there is one entry in the job views (*_SCHEDULER_JOBS) and multiple entries in the job log. Each job instance log entry provides information about a particular run, such as the job completion status and the start and end time. Each run of the job is assigned a unique log id that appears in both the job log and job run details views (*_SCHEDULER_JOB_LOG and *_SCHEDULER_JOB_RUN_DETAILS).
When a job references a program object (program), you can supply job arguments to override the default program argument values, or provide values for program arguments that have no default value. You can also provide argument values to an inline action (for example, a stored procedure) that the job specifies.
A job cannot be enabled until all required program argument values are defined, either as defaults in a referenced program object, or as job arguments.
A common example of a job is one that runs a set of nightly reports. If different departments require different reports, you can create a program for this task that can be shared among different users from different departments. The program action runs a reports script, and the program has one argument: the department number. Each user can then create a job that points to this program and can specify the department number as a job argument.
To define what is executed and when, you assign relationships among programs, jobs, and schedules. Figure 28-5 illustrates examples of such relationships.
Figure 28-5 Relationships Among Programs, Jobs, and Schedules
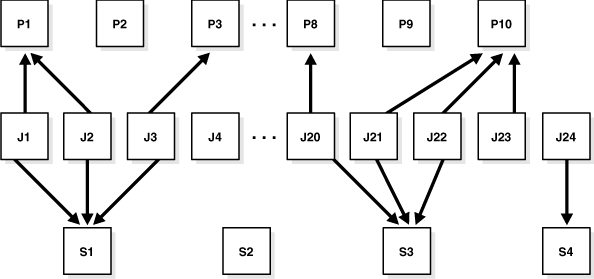
To understand Figure 28-5, consider a situation where tables are being analyzed. In this example, program P1 analyzes a table using the DBMS_STATS package. The program has an input parameter for the table name. Two jobs, J1 and J2, both point to the same program, but each supplies a different table name. Additionally, schedule S1 specifies a run time of 2:00 a.m. every day. The end result is that the two tables named in J1 and J2 are analyzed daily at 2:00 a.m.
Note that J4 points to no other entity, so it is self-contained with all relevant information defined in the job itself. P2, P9 and S2 illustrate that you can leave a program or schedule unassigned if you want. You can, for example, create a program that calculates a year-end inventory and temporarily leave it unassigned to any job.
|
Copyright © 2001, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|