| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
This chapter discusses the matching, merging and data duplication features of Oracle Warehouse Builder.
This chapter contains the following topics:
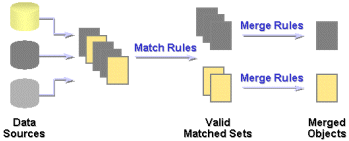
Oracle Warehouse Builder implements general-purpose data matching and merging capabilities that can be applied to any type of data.
You can write the list of rows matched by your algorithms to a target table. You can also implement complex deduplication logic to generated merged records, again using a variety of built-in merge rules or implementing your own merge rules.
Oracle Warehouse Builder matching and merging provides the following functionality:
Determine matches using built-in algorithms, such as the Jaro-Winkler and Levenshtein edit distance algorithms, or using a custom algorithm you implement.
Use weighting to determine matches between records.
Generate a table containing candidate matches, as input to some other merge logic, such as an existing master data management application.
Generate a table with merged data records, with merge logic based on built-in merge rules, custom-implemented merge logic, or complex merge rules that can combine packaged and custom rules.
Cross reference data to track and audit matches.
Built-in advanced matching rules for person, firm and address data.
Oracle Warehouse Builder matching and merging can be combined with Oracle Warehouse Builder name and address cleansing functionality to support householding, which is the process of identifying unique households in name and address data.
See Chapter 22, "Name and Address Cleansing" for details on name and address cleansing.
Note:
Oracle Warehouse Builder exposes its matching and merging functionality through the Match Merge operator used in an Oracle Warehouse Builder ETL mapping. Users of third-party ETL products can still use Oracle Warehouse Builder for matching and merging, while retaining their existing ETL solution.Use the third-party ETL tool to load match-merge input data in a staging table.
Use an Oracle Warehouse Builder ETL mapping to apply match-merge and load the results into an output table.
Use the third-party ETL tool to pick up the merged results from the output table for further processing.
Because the deployed code for the mapping is just a PL/SQL package loaded in the database where the matching and merging takes place, this technique can be used from any ETL tool that can call logic from a PL/SQL package.
Figure 23-1 shows a mapping that uses a Match Merge operator. Notice that the Match Merge operator is preceded by a Name and Address operator, NAMEADDR, and a staging table, CLN_CUSTOMERS. In many scenarios, when cleansing and deduplicating name and address data, it makes sense to combine the Match Merge operator with the Name and Address operator in a mapping. Performing name and address cleansing on your source data provides clean and standardized input data for matching and merging. This improves the quality of your results, and can improve performance because cleansed rows are more easily identified as matches
Figure 23-1 Match Merge Operator in a Mapping
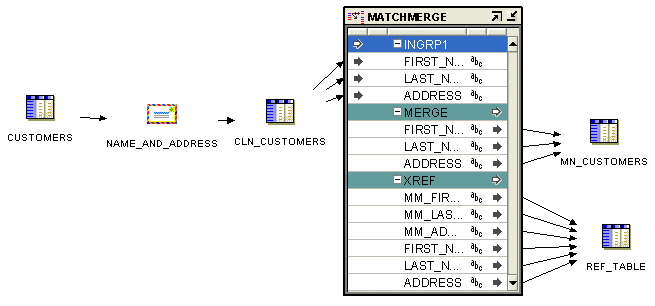
The simple mapping represents the flow of data for the matching and merging process:
The Customers table provides input to the Name and Address operator, which stores its output in the CLN_CUSTOMERS table.
The CLN_CUSTOMERS table provides FIRST, LAST, and ADDRESS columns as inputs to the Match Merge operator.
The Match Merge operator provides FIRST, LAST, and ADDRESS input to the MM_CUSTOMERS table (the actual deduplicated rows), and FIRST, LAST, ADDRESS, MM_FIRST, MM_LAST, and MM_ADDRESS input to the REF_TABLE table, which identifies the groups of matched rows from the input.
Details of how this matching process works are described in "Overview of the Matching and Merging Process".
Matching determines which records refer to the same logical data. Oracle Warehouse Builder provides a variety of match rules to compare records. Match rules range from a simple exact match to sophisticated algorithms that can discover and correct common data entry errors.
Merging consolidates matched records into a single consolidated "golden" record based on survivorship rules called merge rules that you select or define for creating a merged value for each column.
If you have some other tool, such as a packaged MDM application, that has logic for merging duplicate records, you can still use Oracle Warehouse Builder to generate the set of candidate matched rows and store those in an intermediate table.
See Also:
The following concepts and terms are important in understanding the matching and merging process.
Match bins are containers for similar records and are used to identify potential matches. The match bin attributes are used to determine how records are grouped into match bins. While performing matching, Oracle Warehouse Builder compares only records within the same match bin. Match bins limit the number of potential matches in a data set, thus improving performance of the match algorithm.
Before performing matching, Oracle Warehouse Builder divides the source records into smaller groups of similar records. Match bin attributes are the source attributes used to determine how records are grouped. Records having the same match bin attributes reside in the same match bin. Match bin attributes also limit match bins to manageable sets.
Select match bin attributes carefully to fulfill the following two conflicting needs:
Ensure that any records that could match reside in the same match bin.
Keep the size of the match bin as small as possible.
A small match bin is desirable for efficiency, because records that are binned must be tested against each other to identify matches. The larger the bin, the slower the performance.
A match record set consists of one or more similar records within the match bin. After matching, each match bin contains one or more match record sets. You can define match rules that determine if two records are similar.
A merged record contains data that is merged using multiple records in the match record set. Each match record set generates its own merged record.
You use the Match Merge operator to match and merge records. This operator accepts records from an input source, determines the records that are logically the same, and constructs a new merged record from the matched records.
The high-level tasks involved in matching and merging process include the following:
Figure 23-2 represents high-level tasks involved in the matching and merging process.
The match bin is constructed using the match bin attributes. Records with the same match bin attribute values reside in the same match bin. A small match bin is desirable for efficiency.
Match rules are applied to all the records in each match bin to generate one or more match record sets. Match rules determine if two records match. The matching algorithm is an n X n algorithm where all records in the match bin are compared.
One important point of this algorithm is the transitive matching. Consider three records A, B, and C. If record A equals record B and record B equals record C, then record A equals record C.
See Also:
"Match Rules" for information about the types of match rules and how to create them.A single merge record is constructed from each match record set. You can create specific rules to define merge attributes by using merge rules.
See Also:
"Merge Rules" for more information about the types of merge rules.Match rules are used to determine if two records are logically similar. Oracle Warehouse Builder enables you to use different types of rules to match source records. You can define match rules using the MatchMerge Wizard or the MatchMerge Editor. Use the editor to edit existing match rules or add new rules.
Match rules can be active or passive. Active rules are generated and run in the order specified. Passive rules are generated but are not automatically run. A passive rule may be run by a custom rule.
Table 23-1 describes the types of match rules.
Table 23-1 Types of Match Rules
| Match Rule | Description |
|---|---|
|
All Match |
Matches all rows within a match bin |
|
None Match |
Turns off matching. No rows match within the match bin. |
|
Conditional |
Matches rows based on the algorithm you set. For more information about Conditional match rules and how to create one, see "Conditional Match Rules". |
|
Weight |
Matches rows based on scores that you assign to the attributes. For more information about Weight match rules and how to create one, see "Weight Match Rules". |
|
Person |
Matches records based on the names of people. For more information about Person match rules and how to create one, see "Person Match Rules". |
|
Firm |
Matches records based on the name of the organization or firm. For more information about Firm match rules and how to create one, see "Firm Match Rules". |
|
Address |
Matches records based on postal addresses. For more information about Address match rules and how to create one, see "Address Match Rules". |
|
Custom |
Matches records based on a custom comparison algorithm that you define. For more information about Custom match rules and how to create one, see "Custom Match Rules". |
Conditional match rules specify the conditions under which records match.
A conditional match rule enables you to combine multiple attribute comparisons into one composite rule. When multiple attribute is involved in a rule, two records are considered to be a match only if all comparisons are true. Oracle Warehouse Builder displays an AND icon in the left-most column of subsequent conditions.
You can specify how attributes are compared using comparison algorithms.
Identifies the attribute that is tested for a particular condition. You can select from any input attribute (INGRP1).
The order of execution. You can change the position of a rule by clicking on the row header and dragging the row to its new location. The row headers are the boxes to the left of the Attribute column.
You use a list of methods to determine a match. Table 23-2 describes the algorithms.
The minimum similarity value required for two strings to match, as calculated by the Edit Distance, Standardized Edit Distance, Jaro-Winkler, or Standardized Jaro-Winkler algorithms. Enter a value between 0 and 100. A value of 100 indicates an exact match, and a value of 0 indicates no similarity.
Lists options for handling empty strings in a match.
Each attribute in a conditional match rule is assigned a comparison algorithm, which specifies how the attribute values are compared. Multiple attributes may be compared in one rule with a separate comparison algorithm selected for each.
Table 23-2 describes the types of comparisons.
Table 23-2 Types of Comparison Algorithms for Conditional Match Rules
| Algorithm | Description |
|---|---|
|
Exact |
Attributes match if their values are the same. For example, "Dog" and "dog!" would not match, because the second string is not capitalized and contains an extra character. For data types other than |
|
Standardized Exact |
Standardizes the values of the attributes before comparing them for an exact match. With standardization, the comparison ignores case, spaces, and nonalphanumeric characters. Using this algorithm, "Dog" and "dog!" would match. |
|
Soundex |
Converts the data to a Soundex representation and then compares the text strings. If the Soundex representations match, then the two attribute values are considered matched. |
|
Edit Distance |
A "similarity score" in the range 0 to 100 is entered. If the similarity of the two attributes equals or greater than the specified value, then the attribute values are considered matched. The similarity algorithm computes the edit distance between two strings. A value of 100 indicates that the two values are identical; a value of zero indicates no similarity whatsoever. For example, if the string "tootle" is compared with the string "tootles", then the edit distance is 1. The length of the string "tootles" is 7. The similarity value is therefore (6/7)*100 or 85. The algorithm used here is the Levenshtein edit distance algorithm. |
|
Standardized Edit Distance |
Standardizes the values of the attribute before using the Similarity algorithm to determine a match. With standardization, the comparison ignores case, spaces, and nonalphanumeric characters. |
|
Partial Name |
The values of a string attribute are considered a match if the value of one entire attribute is contained within the other, starting with the first word. For example, "Midtown Power" would match "Midtown Power and Light", but would not match "Northern Midtown Power". The comparison ignores case and nonalphanumeric characters. |
|
Abbreviation |
The values of a string attribute are considered a match if one string contains words that are abbreviations of corresponding words in the other. Before attempting to find an abbreviation, this algorithm performs a Std Exact comparison on the entire string. The comparison ignores case and nonalphanumeric character. For each word, the match rule looks for abbreviations, as follows. If the larger of the words being compared contains all of the letters from the shorter word, and the letters appear in the same order as the shorter word, then the words are considered a match. For example, "Intl. Business Products" would match "International Bus Prd". |
|
Acronym |
The values of a string attribute are considered a match if one string is an acronym for the other. Before attempting to identify an acronym, this algorithm performs a Std Exact comparison on the entire string. If no match is found, then each word of one string is compared to the corresponding word in the other string. If the entire word does not match, then each character of the word in one string is compared to the first character of each remaining word in the other string. If the characters are the same, then the names are considered a match. For example, "Chase Manhattan Bank NA" matches "CMB North America". The comparison ignores case and nonalphanumeric characters. |
|
Jaro-Winkler |
Matches strings based on their similarity value using an improved comparison system over the Edit Distance algorithm. The Jaro-Winkler algorithm accounts for the length of the strings and penalizes more for errors at the beginning. It also recognizes common typographical errors. The strings match when their similarity value equals or greater than the Similarity Score that you specify. A similarity value of 100 indicates that the two strings are identical. A value of zero indicates no similarity whatsoever. The value actually calculated by the algorithm (0.0 to 1.0) is multiplied by 100 to correspond to the Edit Distance scores. |
|
Standardized Jaro-Winkler |
Eliminates case, spaces, and nonalphanumeric characters before using the Jaro-Winkler algorithm to determine a match. |
|
Double Metaphone |
Matches phonetically similar strings using an improved coding system over the Soundex algorithm. It generates two codes for strings that could be pronounced in multiple ways. If the primary codes match for the two strings, or if the secondary codes match, then the strings match. The Double Metaphone algorithm accounts for alternate pronunciations in Italian, Spanish, French, and Germanic and Slavic languages. Unlike the Soundex algorithm, Double Metaphone encodes the first letter, so that "Kathy" and "Cathy" evaluate to the same phonetic code. |
To define a conditional match rule, complete the following steps:
On the top portion of the Match Rules tab or the Match Rules page, select Conditional in the Rule Type column.
A Details section is displayed.
Click Add to add a new row.
Select an attribute in the Attribute column.
In the Algorithm column, select a comparison algorithm. See Table 23-2 for descriptions.
Specify a similarity score for the Edit Distance, Standardized Edit Distance, Jaro-Winkler, or Standardized Jaro-Winkler algorithms.
Select a method for handling blanks.
The following discussions illustrate how some basic match rules apply to real data and how multiple match rules can interact with each other.
Consider how you could use the Match Merge operator to manage a customer mailing list. Use matching to find records that refer to the same person in a table of customer data containing 10,000 rows.
For example, you can define a match rule that screens records that have similar first and last names. Through matching, you may discover that 5 rows could refer to the same person. You can then merge those records into one new record. For example, you can create a merge rule to retain the values from the one of the five matched records with the longest address. The newly merged table now contains one record for each customer.
Table 23-3 shows records that refer to the same person before using the Match Merge operator.
| Row | First Name | Last Name | SSN | Address | Unit | Zip |
|---|---|---|---|---|---|---|
|
1 |
Jane |
Doe |
NULL |
123 Main Street |
NULL |
22222 |
|
2 |
Jane |
Doe |
111111111 |
NULL |
NULL |
22222 |
|
3 |
J. |
Doe |
NULL |
123 Main Street |
Apt 4 |
22222 |
|
4 |
NULL |
Smith |
111111111 |
123 Main Street |
Apt 4 |
22222 |
|
5 |
Jane |
Smith-Doe |
111111111 |
NULL |
NULL |
22222 |
Table 23-4 shows the single record for Jane Doe after using the Match Merge operator. Notice that the new record includes data from different rows in the sample.
If you create multiple match rule, Oracle Warehouse Builder determines two rows match if those rows satisfy any of the match rules. In other words, Oracle Warehouse Builder evaluates multiple match rules using OR logic.
The following example illustrates how Oracle Warehouse Builder evaluates multiple match rules.
In the top portion of the Match Rules tab, create two match rules as described in Table 23-5.
| Name | Position | Rule Type | Usage | Description |
|---|---|---|---|---|
|
Rule_1 |
1 |
Conditional |
Active |
Match SSN |
|
Rule_2 |
2 |
Conditional |
Active |
Match Last Name and PHN |
In the lower portion of the tab, assign the details to Rule_1 as described in Table 23-6.
| Attribute | Position | Algorithm | Similarity Score | Blank Matching |
|---|---|---|---|---|
|
SSN |
1 |
Exact |
0 |
Do not match if either is blank |
For Rule_2, assign the details as described in Table 23-7.
| Attribute | Position | Algorithm | Similarity Score | Blank Matching |
|---|---|---|---|---|
|
LastName |
1 |
Exact |
0 |
Do not match if either is blank |
|
PHN |
2 |
Exact |
0 |
Do not match if either is blank |
Assume that you have the data listed in Table 23-8.
| Row | First Name | Last Name | PHN | SSN |
|---|---|---|---|---|
|
A |
John |
Doe |
650-123-1111 |
NULL |
|
B |
Jonathan |
Doe |
650-123-1111 |
555-55-5555 |
|
C |
John |
Dough |
650-123-1111 |
555-55-5555 |
According to Rule_1, rows B and C match. According to Rule_2, rows A and B match. Therefore, because Oracle Warehouse Builder handles match rules using OR logic, all three records match.
The general rule is, if A matches B, and B matches C, then A matches C. Assign a conditional match rule based on similarity such as described in Table 23-9.
Table 23-9 Conditional Match Rule
| Attribute | Position | Algorithm | Similarity Score | Blank Matching |
|---|---|---|---|---|
|
LastName |
1 |
Similarity |
80 |
Do not match if either is blank |
Assume that you have the data listed in Table 23-10.
| Row | First Name | Last Name | PHN | SSN |
|---|---|---|---|---|
|
A |
John |
Jones |
650-123-1111 |
NULL |
|
B |
Jonathan |
James |
650-123-1111 |
555-55-5555 |
|
C |
John |
Jamos |
650-123-1111 |
555-55-5555 |
Jones matches James with a similarity of 80, and James matches Jamos with a similarity of 80. Jones does not match Jamos because the similarity is 60, which is less than the threshold of 80. However, because Jones matches James, and James matches Jamos, all three records match (Jones, James, and Jamos).
A weighted match rule enables you to assign an integer weight to each attribute included in the rule. You must also specify a threshold. For each attribute, the Match Merge operator multiplies the weight by the similarity score, and sums the scores. If the sum equals or exceeds the threshold, then the two records being compared are considered a match.
Weight match rules are most useful when you must compare a large number of attributes, without having a single attribute that is different causing a non-match, as can happen with conditional rules.
Weight rules implicitly invoke the similarity algorithm to compare two attribute values. This algorithm returns an integer, a percentage value in the range 0 to 100, which represents the degree to which two values are alike. A value of 100 indicates that the two values are identical; a value of zero indicates no similarity whatsoever.
The method used to determine a match. Choose from these algorithms:
Edit Distance: Calculates the number of deletions, insertions, or substitutions required to transform one string into another.
Jaro-Winkler: Uses an improved comparison system over the Edit Distance algorithm. It accounts for the length of the strings and penalizes more for errors at the beginning. It also recognizes common typographical errors.
Identifies the attribute that is tested for a particular condition. You can select from any input attribute (INGRP1).
The weight value for the attribute. This value should be greater than the value of Required Score to Match.
The similarity value when one of the records is empty.
A value that represents the similarity required for a match. A value of 100 indicates that the two values are identical. A value of zero indicates there is no similarity.
Table 23-11 displays the attribute values contained in two separate records that are read in the following order.
Table 23-11 Example of Weight Match Rule
| Record Number | First Name | Middle Name | Last Name |
|---|---|---|---|
|
Record 1 |
Robert |
Steve |
Paul |
|
Record 2 |
Steven |
Paul |
You define a match rule that uses the Edit Distance similarity algorithm. The Required Score to Match is 120. The attributes for first name and middle name are defined with a Maximum Score of 50 and Score When Blank of 20. The attribute for last name has a Maximum Score of 80 and a Score When Blank of 0.
Consider an example of the comparison of Record 1 and Record 2 using the weight match rule.
Because first name is blank for Record 2, the Blank Score = 20.
The similarity of middle name in the two records is 0.83. Since the weight assigned to this attribute is 50, the similarity score for this attribute is 41.5 (0.83 X 50).
Because the last name attributes are the same, the similarity score for the last name is 1. The weighted score is 80 (1 X 80).
The total score for this comparison is 143 (20+43+80). Since this is more than the value defined for Required Score to Match, the records are considered a match.
To use the Weight match rule, complete the following steps:
On the Match Rules tab or the Match Rules page, select Weight as the Rule Type.
The Details tab is displayed at the bottom of the page.
Select Add at the bottom of the page to add a new row.
For each row, select an attribute to add to the rule using the Attribute column.
In Maximum Score, assign a weight to each attribute. Oracle Warehouse Builder compares each attribute using a similarity algorithm that returns a score between 0 and 100 to represent the similarity between the rows.
In Score When Blank, assign a value to be used when the attribute is blank in one of the records.
In Required score to match, assign an overall score for the match.
For two rows to be considered a match, the total counts must be greater than the value specified in the Required score to match parameter.
Built-in Person rules provide an easy and convenient way for matching names of individuals. Person match rules are most effective when the data has first been corrected using the Name and Address operator.
When you use Person match rules, you must specify which data within the record represents the name of the person. The data can come from multiple columns. Each column must be assigned an input role that specifies what the data represents.
To define a Person match rule, you must define the Person Attributes that are part of the rule. For example, you can create a Person match rule that uses the Person Attributes first name and last name for comparison. For each Person Attribute, you must define the Person Role that the attribute uses. Next you define the rule options used for the comparison. For example, while comparing last names, you can specify that hyphenated last names should be considered a match.
Table 23-12 describes the roles for different parts of a name that are used for matching. On the Match Rules page or Match Rules tab, use the Roles column on the Person Attributes tab to define person details.
Table 23-12 Name Roles for Person Match Rules
| Role | Description |
|---|---|
|
Prename |
Prenames are compared only if the following are true:
|
|
First Name Standardized |
Compares the first names. By default, the first names must match, but you can specify other comparison options as well. First names match if both are blank. A blank first name does not matches a nonblank first name unless the Prename role has been assigned and the "Mrs. Match" option is set. If a Last_name role has not been assigned, then a role of First_name_std must be assigned. |
|
Middle Name Standardized, Middle Name 2 Standardized, Middle Name 3 Standardized |
Compares the middle names. By default, the middle names must match, but other comparison options can be specified. If multiple middle name role is assigned, then attributes assigned to the different roles are cross-compared. For example, values for Middle_name_std is compared not only against other Middle_name_std values, but also against Middle_name_2_std, if that role is also assigned. Middle names match if either or both are blank. If any of the middle name roles are assigned, then the First_name_std role must also be assigned. |
|
Last Name |
Compares the last names. By default, the last names must match, but you can specify other comparison options. The last names match if both are blank, but not if only one is blank. |
|
Maturity Post Name |
Compares the post name, such as "Jr.", "III," and so on. The post names match if the values are the same, or if either value is blank. |
Table 23-13 describes the options that determine a match for Person match rules. Use the Details tab of the Match Rules tab or the Match Rules page to define person details.
Table 23-13 Options for Person Match Rule
| Option | Description |
|---|---|
|
Detect switched name order |
Detects switched name orders such as matching "Elmer Fudd" to "Fudd Elmer". You can select this option if you selected First Name and Last Name roles for attributes on the Person Attributes tab. |
|
Match on initials |
Matches initials to names such as "R"' and "Robert". You can select this option for first name and middle name roles. |
|
Match on substrings |
Matches substrings to names such as "Rob" to "Robert". You can select this option for first name and middle name roles. |
|
Similarity Score |
Records are considered a match if the similarity is greater than or equal to the score. For example, "Susan" matches "Susen" if the score is less than or equal to 80. Uses a similarity score to determine a match, as calculated by the Edit Distance or Jaro-Winkler algorithm. A value of 100 requires an exact match, and a value of 0 requires no similarity whatsoever. |
|
Match on Phonetic Codes |
Determines a match using either the Soundex or the Double Metaphone algorithm. |
|
Detect compound name |
Matches compound names to names such as "De Anne" to "Deanne". You can select this option for the first name role. |
|
"Mrs" Match |
Matches prenames to first and last names such as "Mrs. Washington" to "George Washington". You can select this option for the prename role. |
|
Match hyphenated names |
Matches hyphenated names to unhyphenated names such as "Reese-Jones" to "Reese". You can select this option for the last name role. |
|
Detect missing hyphen |
The operator detects missing hyphens, such as matching "Hillary Rodham Clinton" to "Hillary Rodham-Clinton". You can select this option for the last name role. |
To define a Person match rule, complete the following steps:
On the Match Rules tab, select Person as the Rule Type.
The Person Attributes tab and Details tab are displayed at the bottom of the page.
In the left panel of the Person Attributes tab, select the attributes that describe a full name and use the right arrow to move them to the Name Roles section.
For each attribute, select the role that it plays in a name.
You must define either the Last Name or First Name Standardized for the match rule to be effective. See Table 23-12 for the types of roles that you can assign.
Select the Details tab and select the applicable options as listed in Table 23-13.
Built-in Firm match rules provide an easy and convenient way for matching business names. Firm match rules are most effective when the data has first been corrected using the Name and Address operator. Similar to the Person rule, this rule requires users to set what data within the record represents the name of the firm. The data can come from multiple columns and each column specified must be assigned an input role that indicates what the data represents.
You need not assign a firm role to every attribute, and not every role must be assigned to an attribute. The attributes assigned to firm roles are used in the match rule to compare the records. The attributes are compared based on the role that they have been assigned and other comparison options that you have set. For a complete list of firm roles and how each role is treated in a firm match rule, see "Firm Roles".
Firm roles define the parts of a firm name that are used for matching. The options that you can select for firm role are Firm1 or Firm2. If you select one attribute for firm name, then select Firm1 as the role. If you select two attributes, then designate one of them as Firm1 and the other as Firm2.
Firm1: If this role is assigned, then the business names represented by Firm1 are compared. Firm1 name is not compared against Firm2 names unless the Cross-match firm1 and firm2 box is checked. By default, the firm names must match, but other comparison options can also be specified. Firm1 names do not match if either or both names are blank.
Firm2: If this role is assigned, then the values of the attribute assigned to Firm2 is compared. Firm2 names are not compared against Firm1 names unless the Cross-match firm1 and firm2 box is checked. By default, the firm names must match, but other comparison options can also be specified. Firm2 names do not match if either or both names are blank. If a Firm1 role is not assigned, then a Firm2 role must be assigned.
Table 23-14 describes the rule options that you can set for each component of the firm name to determine a match.
Table 23-14 Options for Firm Rules
| Option | Description |
|---|---|
|
Strip noise words |
Removes the following words from Firm1 and Firm2 before matching: THE, AND, CORP, CORPORATION, CO, COMPANY, INC, INCORPORATED, LTD, TO, OF, and BY. |
|
Cross-match firm1 and firm2 |
When comparing two records for matching, in addition to matching firm1 to firm1 and firm2 to firm2 of the respective records, match firm1 against firm2 for the records. |
|
Match on partial firm name |
Uses the Partial Name algorithm to determine a match. For example, match "Midtown Power" to "Midtown Power and Light". |
|
Match on abbreviations |
Uses the Abbreviation algorithm to determine a match. For example, match "International Business Machines" to "IBM". |
|
Match on acronyms |
Uses the Acronym algorithm to determine a match. For example, match "CMB, North America" to "Chase Manhattan Bank, NA". |
|
Similarity score |
Uses a similarity score to determine a match, as calculated by the Edit Distance or Jaro-Winkler algorithm. Enter a value between 0 and 100 as the minimum similarity value required for a match. A value of 100 requires an exact match, and a value of 0 requires no similarity whatsoever. Two records are considered as a match if the similarity is greater than or equal to the value of similarity score. |
To define a Firm match rule, complete the following steps:
On the Match Rules tab or the Match Rules page, select Firm as the Rule Type.
The Firm Attributes tab and Details tab are displayed at the bottom of the page.
In the left panel of the Firm Attributes tab, select one or two attributes that represent the firm name and click the right shuttle button.
The attributes are moved to the Firm Roles box.
For each attribute, click Roles. From the list, select Firm 1 for the first attribute, and Firm 2 for the second attribute, if it exists.
On the Details tab, select the applicable options. For more details, see "Firm Details".
Address match rules provide a method of matching records based on postal addresses. Address match rules are most effective when the data has first been corrected using a Name and Address operator.
Address match rules work differently depending on whether the address being processed has been corrected using the Name and Address operator. Generally, corrected addresses have been identified in a postal matching database, and are therefore syntactically correct, legal, and existing addresses according to the Postal Service of the country containing the address. Corrected addresses can be processed more quickly, because the match rule can ensure assumptions about their format.
Uncorrected addresses may be syntactically correct, but have not been found in a postal matching database. Addresses may have not been found because they are not in the database, or because there is no postal matching database installed for the country containing the address. Address match rules determine whether an address has been corrected based on the Is_found role. If the Is_found role is not assigned, then the match rule performs the comparisons for both the corrected and uncorrected addresses.
To create an Address match rule, assign address roles to the various attributes. The attributes assigned to address roles are used in the match rule to compare the records. Attributes are compared depending on which role they have been assigned, and what other comparison options have been set.
Table 23-15 describes the address roles that you can select for each part of an address.
| Role | Description |
|---|---|
|
Primary Address |
Compares the primary addresses. Primary addresses can be, for example, street addresses ("100 Main Street") or PO boxes ("PO Box 100"). By default, the primary addresses must match, but a similarity option can also be specified. The Primary_address role must be assigned. |
|
Unit Number |
Unit numbers (such as suite numbers, floor numbers, or apartment numbers) are compared if the primary addresses match. The unit numbers match if both are blank, but not if one is blank, unless the Match on blank secondary address option is set. If the Allow differing secondary address option is set, then the unit numbers are ignored. |
|
PO Box |
Compares the Post Office Boxes. The PO Box is just the number portion of the PO Box ("100"), and is a subset of the primary address, when the primary address represents a PO Box ("PO Box 100"). If the primary address represents a street address, then the PO Box is blank. |
|
Dual Primary Address |
The Dual_primary_address is compared against the other record's Dual_primary_address and Primary_address to determine a match. |
|
Dual Unit Number |
Compares the Dual_unit_number address with the Dual_unit_number and Unit_number of the other record. The unit numbers match if one or both are blank. To assign the Dual_unit_number role, the Dual_primary_address role must also be assigned. |
|
Dual PO Box |
Dual_PO_Box address of a record is compared with the Dual_PO_Box and the PO_Box of the other record. To assign the Dual_PO_Box role, the Dual_primary_address role must also be assigned. |
|
City |
Compares the cities for uncorrected addresses. For corrected addresses, the cities are only compared if the postal codes do not match. If both City and State roles match, then the address line roles, such as Primary_address, can be compared. By default, the cities must match. But you may specify a last line similarity option. The cities match if both are blank, but not if only one is blank. If the City role is assigned, then the State role must also be assigned. |
|
State |
Assign this role only when also assigning the City role. The states are compared for uncorrected addresses. For corrected addresses, the states are only compared if the postal codes do not match. If both State and City roles match, then the address line roles, such as Primary_address, can be compared. By default, the states must match, but a last line similarity option may be specified. The states match if both are blank, but not if only one is blank. If the State role is assigned, then the City role must also be assigned. |
|
Postal Code |
For uncorrected address data, the operator does not use Postal Code. The postal codes are compared for corrected addresses. For uncorrected addresses, the Postal_code role is not used. To match, the postal codes must be the same. The postal codes are not considered a match if one or both are blank. If the postal codes match, then the address line roles, such as Primary_address, can be compared. If the postal codes do not match, then City and State roles are compared to determine whether the address line roles should be compared. |
|
Is Found |
The Is_found_flag attributes are not compared, but instead are used to determine whether an address has been found in a postal matching database, and therefore represents a legal address according to the postal service of the country containing the address. This determination is important because the type of comparison done during matching depends on whether the address has been found in the postal database. |
Table 23-16 describes the options for determining a match for an Address rule.
Table 23-16 Options for Address Roles
| Option | Description |
|---|---|
|
Allow differing secondary address |
Enable addresses to match even if the unit numbers are not null and are different. |
|
Match on blank secondary address |
Enable addresses to match even if exactly one unit number is null. |
|
Match on either street or post office box |
Match records if either the street address or the post office box match. |
|
Address line similarity |
Match if address line similarity >= the score. All spaces and non-alpanumeric characters are removed before the similarity is calculated. |
|
Last line similarity |
Match if the last line similarity >= score. The last line consists of city and state. All spaces and nonalphanumeric characters are removed before the similarity is calculated. |
To define an Address match rule, complete the following steps:
On the Match Rules tab or the Match Rules page, select Address as the Rule Type.
The Address Attributes tab and Details tab are displayed at the bottom of the page.
In the left panel of the Address Attributes tab, select the attribute that represents the primary address. Use the right shuttle key to move it to the Address Roles Attributes column.
Click Role Required and designate that attribute as the Primary Address.
You must designate one attribute as the primary address. If you do not assign the Primary Address role, then the match rule is invalid.
Add other attributes and designate their roles as necessary. See Table 23-15 for the types of roles that you can assign.
Select the Details tab and select the applicable options as listed in Table 23-16.
Custom match rules enable you to write your own comparison algorithms to match records. You can use any input attributes or match functions within this comparison. You can use an active custom rule to control the execution of passive rules.
Consider the following three passive built-in rules:
NAME_MATCH: built-in name rule
ADDRESS_MATCH: built-in address rule
TN_MATCH: built-in conditional rule
You can create a custom rule to specify that two records can be considered a match if any two of these rules are satisfied. Example 23-1 describes the PL/SQL code used to create the custom match rule that implements this example.
Example 23-1 Creating a Custom Rule Using Existing Passive Rules
BEGIN
RETURN(
(NAME_MATCH(THIS_,THAT_) AND ADDRESS_MATCH(THIS_,THAT_))
OR
(NAME_MATCH(THIS_,THAT_) AND TN_MATCH(THIS_,THAT_))
OR
(ADDRESS_MATCH(THIS_,THAT_) AND TN_MATCH(THIS_,THAT_))
);
END;
To define a Custom match rule, complete the following steps:
On the Match Rules tab or the Match Rules page, select Custom as the Rule Type.
A Details field is displayed at the bottom of the page with the skeleton of a PL/SQL program.
Click Edit to open the Custom Match Rules Editor.
For more information about using the editor, select Help Topic from the Help menu.
To enter PL/SQL code, use any combination of the following:
To read in a file, select Open File from the Code menu.
To enter text, first position the cursor using the mouse or arrow keys, then begin typing. You can also use the commands on the Edit and Search menus.
To reference any function, parameter, or transformation in the navigation tree, first position the cursor, then double-click or drag-and-drop the object onto the Implementation field.
To validate your code, select Validate from the Test menu.
The validation results appear on the Messages tab.
To save your code, select Save from the Code menu.
To close the Custom Match Rules Editor, select Close from the Code menu.
Matching produces a set of records that are logically the same. Merging is the process of creating one record from the set of matched records. A Merge rule is applied to attributes in the matched record set to obtain a single value for the attribute in the merged record.
You can define one Merge rule for all the attributes in the Merge record or define a rule for each attribute. For instance, if the merged record is a customer record, it may have attributes such as ADDRESS1, ADDRESS2, CITY, STATE, and ZIP. You can write five rules that select the value of each attribute from up to five different records, or one Record rule that selects the values of all five attributes from one record. Use Record rules when multiple attributes compose a logical unit, such as an address. For example, City, State, and Zip Code might be three different attributes, but the data for these attributes should all come from the same record.
Table 23-17 describes the types of merge rules.
| Merge Rule | Description |
|---|---|
|
Any |
Uses the first nonblank value |
|
Match ID |
Merges records that have been output from another Match Merge operator |
|
Rank |
Ranks the records from the match set. The associated attribute from the highest ranked record is used to populate the merge attribute value |
|
Sequence |
Specify a database sequence for this rule. The next value of the sequence is used for the value. |
|
Min Max |
Specify an attribute and a relation to choose the record to be used as a source for the merge attribute. |
|
Copy |
Choose a value from a different previously merged value. |
|
Custom |
Create a PL/SQL package function to select the merge value. The operator provides the signature of this function. The user is responsible for the implementation of the rule from "BEGIN" to "END;" The matched records and merge record are parameters for this function. |
|
Any Record |
Identical to the Any rule, except that an Any Record rule applies to multiple attributes |
|
Rank Record |
Identical to the Rank rule, except that a Rank Record rule applies to multiple attributes |
|
Min Max Record |
Identical to the Min Max rule, except that a Min Max Record rule applies to multiple attributes |
|
Custom Record |
Identical to the Custom rule, except that a Custom Record rule applies to multiple attributes |
Use the Match ID merge rule to merge records that have been output in the XREF group from another Match Merge operator. No other operator is valid for this type of input. For more information, see "Example: Using Two Match Merge Operators for Householding".
Identifies the sequence that is used by the rule.
Lists all sequences defined in the current project.
Sets the sequence for the rule to the sequence currently selected in the list. Move a sequence from the sequences list to Select Sequence.
Use the Rank and Rank Record rules when merging data from multiple sources. These rules enable you to identify your preference for certain sources. Your data must have a second input attribute on which the rule is based.
For example, the second attribute might identify the data source, and these data sources are ranked in order of reliability. The most reliable value would be used in the merged record. The merge rule might look like this:
INGRP1.SOURCE = 'Order Entry'
An arbitrary name for the rule. Oracle Warehouse Builder creates a default name such as RULE_0 for each Rank merge rule. You can replace these names with meaningful ones.
The order of execution. You can change the position of a rule by clicking on the row header and dragging the row to its new location. The row headers are the boxes to the left of the Name column.
The custom SQL expression used in the ranking. Click the Ellipsis button to display the Rank Rule Editor (also called the Expression Builder User Interface). Use this editor to develop the ranking expression.
The Sequence rule uses the next value in a sequence.
Identifies the sequence that is used by the rule.
Lists all sequences defined in the current project.
Sets the sequence for the rule to the sequence currently selected in the list.
The Min Max and Min Max Record rules select an attribute value based on the size of another attribute value in the record.
For example, you might select the First Name value from the record in each bin that contains the longest Last Name value.
Lists all input attributes. Select the attribute whose values provide the order.
Select the characteristic for choosing a value in the selected attribute.
Minimum. Selects the smallest numeric value or the oldest date value.
Maximum. Selects the largest numeric value or the most recent date value.
Shortest. Selects the shortest character value.
Longest. Selects the longest character value.
The Copy rule uses the values from another merged attribute.
Lists the other merged attributes, which you selected on the Merge Attributes page.
The Custom and Custom Record rules use PL/SQL code that you provide to merge the records. The following is an example of a Custom merge rule, which returns the value of the TAXID attribute for record 1.
BEGIN RETURN M_MATCHES(1)."TAXID"; END;
The following is an example of a Custom Record merge rule, which returns a record for record 1:
BEGIN RETURN M_MATCHES(1); END;
Displays the PL/SQL code composing your custom algorithm. You can edit code directly in this field or use the Custom Merge Rule Editor.
Displays the Custom Merge Rule Editor.
Use the Match Merge operator to identify matching records in a data source and to merge them into a single record.
The Match Merge operator has one input group and two output groups, Merge and Xref. The source data is mapped to the input group. The Merge group contains records that have been merged after the matching process is complete. The Xref group provides a record of the merge process. Every record in the input group has a corresponding record in the Xref group. This record may contain the original attribute values and the merged attributes.
The Match Merge operator uses an ordered record stream as input. From this stream, it constructs the match bins. From each match bin, matched sets are constructed. From each matched set, a merged record is created. The initial query contains an ORDER BY clause consisting of the match bin attributes.
To match and merge source data using the Match Merge operator:
Drag and drop the operators representing the source data and the operator representing the merged data onto the Mapping Editor canvas.
For example, if your source data is stored in a table, and the merged data is stored in another table, drag and drop two Table operators that are bound to the tables onto the canvas.
Drag and drop a Match Merge operator onto the Mapping Editor canvas.
The MatchMerge Wizard is displayed.
On the Name page, the Name field contains a default name for the operator. You can change this name or accept the default name.
You can enter an optional description for the operator.
On the Groups page, you can rename groups or provide descriptions for them.
This page contains the following three groups:
INGRP1: Contains input attributes.
MERGE: Contains the merged records (usually this means fewer records than INGRP1).
XREF: Contains the link between the original and merged data sets. This is the tracking mechanism used when a merge is performed.
On the Input Connections page, move the attributes to match and merge from the Available Attributes section to the Mapped Attributes section. Click Next.
The Available Attributes section of this page displays nodes for each operator on the canvas. Expand a node to display the attributes contained in the operator, select the attributes, and use the shuttle arrows to move selected attributes to the Mapped Attributes section.
Note:
The Match Merge operator requires an ordered input data set. If you have source data from multiple operator, then use a Set Operation operator to combine the data and obtain an ordered data set.On the Input Attributes page, review the attribute data types and lengths.
In general, if you go through the wizard, you need not change any of these values. Oracle Warehouse Builder populates them based on the output attributes.
On the Merge Output page, select the attributes to be merged from the input attributes.
These attributes appear in the Merge output group (the cleansed group). The attributes in this group retain the name and properties of the input attributes.
On the Cross Reference Output page, select attributes for the XREF output group.
The Source Attributes section contains all the input attributes and the Merge attributes that you selected on the Merge Output page. The attributes from the Merge group are prefixed with MM_. The other attributes define the unmodified input attribute values. Select at least one attribute from the Merge group that provides a link between the input and Merge groups.
On the Match Bins page, specify the match bin attributes. These attributes are used to group source data into match bins.
After the first deployment, you can choose whether to match and merge all records or only new records. To match and merge only the new records, select Match New Records Only.
You must designate a condition that identifies new records. The Match Merge operator treats the new records in the following way:
No matching is performed for any records in a match bin unless the match bin contains a new record.
Old records are not compared with each other.
A matched record set is not presented to the merge processing unless the matched record set contains a new record.
An old record is not presented to the Xref output unless the record is matched to a new record.
For more information about match bin attributes and match bins, see "Overview of the Matching and Merging Process".
On the Define Match Rules page, define the match rules that is used to match the source data.
Match rules can be active or passive. A passive match rule is generated but not automatically invoked. You must define at least one active match rule.
For more information about the match rules, the types of match rules that you can define, and the steps used to define them, see "Match Rules".
On the Merge Rules page, define the rules that is used to merge the sets of matched records created from the source data.
You can define Merge rules for each attribute in a record or for the entire record. Oracle Warehouse Builder provides different types of Merge rules.
For more information about the types of Merge rules and the steps to create Merge rules, see "Merge Rules".
On the Summary page, review your selections. Click Back to modify any selection that you made. Click Next to complete creating the Match Merge operator.
Map the Merge group of the Match Merge operator to the input group of the operator that stores the merged data.
Be aware of the following considerations as you design your mapping:
Operating modes: A mapping that contains a Match Merge operator can only run in set-based mode. Operators may accept either set-based or row-based input and generate either set-based or row-based output. SQL is set-based, so a set of records is processed. PL/SQL is row-based, so each row is processed separately. When the Match Merge operator matches records, it compares each row with the subsequent row in the source, and generates row-based code only.
SQL-based operators before Match Merge: The Match Merge operator accepts set-based SQL input, but generates only row-based PL/SQL output. Any operators that generate only SQL code must precede the Match Merge operator. For example, the Joiner, Lookup, and Set operators generate set-based SQL output, so they must precede the Match Merge operator. If set-based operators appear after Match Merge operator, then the mapping is invalid. If you process the output of a match-merge mapping using a set-based SQL operator, then stage the output in an intermediate table.
PL/SQL input: The Match Merge operator requires SQL input except from another Match Merge operator, as described in "Example: Using Two Match Merge Operators for Householding". To precede a Match Merge operator with an operator that generates only PL/SQL output, then you must first load the data into a staging table.
Refining data from Match Merge operators: To achieve greater data refinement, map the XREF output from one Match Merge operator into another Match Merge operator. This scenario is the one exception to the SQL input rule for Match Merge operators. With additional design elements, the second Match Merge operator accepts PL/SQL. For more information, see "Example: Using Two Match Merge Operators for Householding".
Because the match-merge process generates only PL/SQL, you cannot map the Merge or XREF output groups of the Match Merge operator to a SQL-only operator such as a Sorter operator or another Match Merge operator.
Because the Match Merge operator only accepts SQL input, you cannot map the output of the Name and Address operator directly to the Match Merge operator. You must use a staging table.
Most match-merge operations can be performed by a single Match Merge operator. However, if you are directing the output to two different targets, then you must use two Match Merge operators in succession.
For example, when householding name and address data, you must merge the data first for addresses and then again for names. Assuming that you map the MERGE output to a target table, you can map the XREF group to another Match Merge operator.
Note:
Although you could map the XREF group to a staging table, this intermediate step adds significant overhead. The match-merge functionality is designed to support maximum performance using two Match Merge operators as described in this section.Figure 23-3 shows a mapping that uses two Match Merge operators. The XREF group from MM is mapped directly to MM_1. For this mapping to be valid, you must assign the Match ID generated for the first XREF group as the Match Bin rule on the second Match Merge operator.
Figure 23-3 Householding Data: XREF Group Merged to Second Match Merge Operator
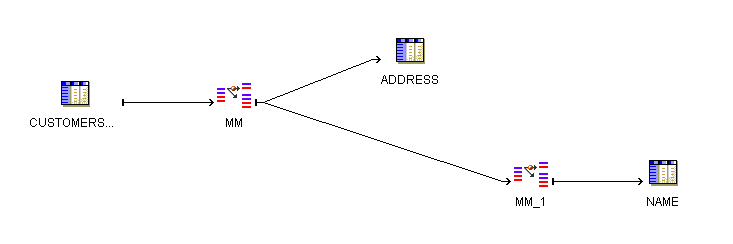
Note:
A more complete solution for the householding problem might apply name and address cleansing on individual records before performing the matching and merging to group customers into households.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|