| Oracle® Airlines Data Model Implementation and Operations Guide 11g Release 2 (11.2) Part Number E26211-02 |
|
|
PDF · Mobi · ePub |
| Oracle® Airlines Data Model Implementation and Operations Guide 11g Release 2 (11.2) Part Number E26211-02 |
|
|
PDF · Mobi · ePub |
This chapter provides information about customizing the access layer of Oracle Airlines Data Model. It includes the following topics:
The access layer of Oracle Airlines Data Model provides the calculated and summarized ("flattened") perspectives of the data needed by business intelligence tools. Access layer objects are populated using the data from the foundation layer 3NF objects.
The access layer objects in the oadm_sys schema include: derived and aggregate tables, tables that provide the dimension for the derived and aggregate tables, OLAP cubes, and materialized views. This layer also contains data mining models. The results of the these models are stored in derived tables.
When designing and customizing access layer objects:
Follow the general guidelines for customizing physical objects given in "General Recommendations When Designing Physical Structures".
Design the access layer objects to support the business intelligence reports and queries that your site makes. See Chapter 5, "Report and Query Customization."
The following topics provide specialized information about designing and customizing access layer objects:
Dimension tables are tables that store the dimension data for fact tables. There are two types of tables that act as dimensions to other tables in the Oracle Airlines Data Model:
In the foundation layer, DWR_ tables (also known as reference tables) act as dimension tables to the base (DWB_ ) tables.
In the access layer, DWM_ tables (simply called "dimension" tables) act as dimension tables to derived (DWD_ ) and aggregate (DWA_ ) tables. DWM_ tables provide a view of the data similar to the view provided by a dimension table in a star schema.
The default Oracle Airlines Data Model defines several dimension tables. For example, the DWR_SEG and DWM_SEG tables store the values of the segment information in different layers.
Derived tables are tables that have as values the result of a non-aggregate calculation against the data in the foundation layer tables. Derived tables have a DWD_ prefix.
There are two main types of derived tables in the default Oracle Airlines Data Model and the way you customize these tables varies by type:
Tables that hold the results of a calculation. For information on customizing these tables, see "Creating New Derived Tables for Calculated Data".
Result tables for the data mining models. For information on customizing data mining models, see "Customizing Data Mining Models in the Oracle Airlines Data Model".
See:
The Derived Tables topic in Oracle Airlines Data Model Reference for a list of all of the derived tables in the default Oracle Airlines Data Model. For a list of only those derived tables that are results tables for the data mining models, see the chapter on Data Mining Models in Oracle Airlines Data Model Reference.If, during fit-gap analysis, you identified a need for calculated data that is not provided by the default derived tables, you can meet this need by defining new tables. When designing these tables, name the tables following the convention of using the DWD_ prefix for derived tables.
Some derived (DWD_) tables define in the oadm_sys schema are the result tables for the data mining models defined in the Oracle Airlines Data Model. All Oracle Airlines Data Model data mining models use materialized views as source input. Those materialized views are defined in the oadm_mining_init.sql script in $ORACLE_HOME/oadm/pdm/mining. Different data mining models use different source materialized views.
When creating a customized Oracle Airlines Data Model warehouse, you can customize the data mining models in the following ways:
Create a new data mining model as discussed in "Creating a New Data Mining Model for Oracle Airlines Data Model".
Modify an existing data mining model as discussed in "Modifying a Data Mining Model in the Oracle Airlines Data Model".
To create a new data mining model:
Ensure that the oadm_sys schema includes a definition for materialized view that you can use as input to the new data mining model. Define a new materialized view, if necessary.
Create the new data mining model as you would any data mining model. Follow the instructions given in Oracle Data Mining Concepts.
Add any physical tables needed by the data mining model into the oadm_sys schema. When naming a data mining source table, use the prefix DM_ . When naming a data mining results table, use the prefix DWD_ .
To customize an Oracle Airlines Data Model data mining model, take the following steps:
Change the definition for source materialized views used as input to the data mining model.
Train the data mining model again by calling Oracle Airlines Data Model mining package.
Ensure that the data mining model reflects the new definition (for example, that a new column has been added).
Example 3-1 Adding a New Column to the create_cust_ltv_svm_rgrsn_model Data Mining Model
The create_cust_ltv_svm_rgrsn_model data mining model uses the dmv_cust_ltv_src materialized view as source input. To customize the create_cust_ltv_svm_rgrsn_model data mining model by adding a new column to the model, take the following steps:
Modify the following materialized views:
dmv_bkg_fact_src
dmv_lylty_acct_bal_src
dmv_cust_profile_src
Train customer life time value regression data mining model, execute the following statement.
pkg_oadm_mining.create_cust_ltv_svm_rgrsn
Issue the following statement to query the result table and ensure the new column is included in the query result.
SELECT attribute_name FROM TABLE( SELECT attribute_set FROM TABLE(DBMS_DATA_MINING.GET_MODEL_DETAILS_SVM('CUST_LTV_SVM_RGRSN')));
After you have populated Oracle Airlines Data Model foundation layer and executed the intra-ETL to populate derived tables, you can leverage the prebuilt Oracle Airlines Data Model data mining models for more advanced analysis and predictions.
This tutorial shows how to predict the Life Time Value of customers, who are frequent flier passengers, for next 6 months based on populated Oracle Airlines Data Model warehouse. Using prebuilt Oracle Airlines Data Model data mining models, you can easily and very quickly see the prediction results of your customers, without having to go through all of the data preparation, training, testing, and applying process that you must perform in a traditional from-scratch mining project.
After initially generating a data mining model, as time goes by, the customer information, behavior, and usage change. Consequently, you must refresh the previous trained data mining models based on the latest customer and usage data. You can follow the process in this tutorial to refresh the data mining models to acquire predictions on latest customer information.
This tutorial shows you how to investigate the Customer Life Time Value Prediction model through Oracle Airlines Data Model mining APIs. To use different parameters in the training process, or customize the model in more advanced fashion, you can either modify mining settings tables (with DM_ as prefix) or use the Oracle Data Miner GUI tool.
This tutorial consists of the following:
See:
Oracle Data Mining Concepts for more information about the Oracle Database data mining model training and scoring (applying) process.Before starting this tutorial:
Review the Oracle by Example (OBE) tutorial "Using Oracle Data Miner 11g Release 2." To access this tutorial, open the Oracle Learning Library in your browser by following the instructions in "Oracle Technology Network"; and, then, search for the tutorial by name.
Install Oracle Airlines Data Model.
Populate the base, reference and lookup tables.
Execute the intra-ETL.
Ensure that at least the following tables contain valid data:
DWB_LYLTY_ACCT_BAL_HIST_H DWD_BKG_FACT DWM_CLNDR DWM_FRQTFLR DWM_GEOGRY
Note:
If you have not populated the real data, and only want to learn the Oracle Airlines Data Model data mining model, you can use the sample data by taking the following steps:Ensure that during the install, you generated the calendar data covering range of 2005~2011. For example, the parameters of starting from 20050101 for 7 years satisfy this condition.
Download the sample data (oadm_sample_mining.dmp.zip) and import the data into your new oadm_sys schema.
This tutorial requires a valid, populated Oracle Airlines Data Model warehouse.
To prepare the environment, take the following steps:
In SQL Developer, connect to the oadm_sys schema.
Tip:
SQL Developer can be found on any Oracle Database Installation under$ORACLE_HOME/sqldeveloper.
Oracle by Example:
For more information about using SQL Developer, refer to tutorial "Getting Started with Oracle SQL Developer 3.0". To access this tutorial, open the Oracle Learning Library in your browser by following the instructions in "Oracle Technology Network"; and, then, search for the tutorial by name.After you connect to the oadm_sys schema, you can see all of the tables that have been created. You can narrow down the list by right clicking "Tables" and then applying filters.
(Optional) As mentioned in "Tutorial Prerequisites", if you have not populated those tables with your own data, you can try with some sample data. After you download the sample data, take the following steps to import the data.
Grant dba to oadm_sys by issuing the following statement:
grant dba to oadm_sys
Disable all foreign keys on those tables required by the tutorial.
First, issue the following statement that generates SQL statements.
SELECT 'ALTER TABLE ' || table_name || ' DISABLE CONSTRAINT ' ||
CONSTRAINT_NAME ' CASCADE;' FROM all_constraints
WHERE status='ENABLED' AND owner='OADM_SYS'
AND constraint_type=
'R' and table_name IN
('DWB_LYLTY_ACCT_BAL_HIST_H','DWD_BKG_FACT','DWM_CLNDR',
'DWM_FRQTFLR','DWM_GEOGRY') ;
Then, to actually disable the foreign keys for the following tables, execute the SQL statements generated by the previous SELECT statement:
DWB_LYLTY_ACCT_BAL_HIST_H DWD_BKG_FACT DWM_CLNDR DWM_FRQTFLR DWM_GEOGRY
Ensure that the sample dump, oadm_sample.dmp, is in default data dump directory, DATA_PUMP_DIR. Then, import the sample mining dump into oadm_sys schema by issuing the following statement. (Replace password with your password for oadm_sys.)
impdp oadm_sys/password directory=DATA_PUMP_DIR dumpfile=oadm_sample.dmp
content=DATA_ONLY table_exists_action=truncate
TABLES=oadm_sample.DWB_LYLTY_ACCT_BAL_HIST_H,
oadm_sample.DWD_BKG_FACT,oadm_sample.DWM_CLNDR,
oadm_sample.DWM_FRQTFLR,oadm_sample.DWM_GEOGRY
Review the tables to ensure that they contain valid data (either your own customer data or sample mining data).
Check the mining result table DWD_CUST_MNNG is empty before executing the model procedure in Oracle Airlines Data Model Mining APIs.
This tutorial uses two procedures from Oracle Airlines Data Model Mining APIs:
pkg_oadm_mining.refresh_mining_source that refreshes all mining source materialized views.
pkg_oadm_mining.create_cust_ltv_svm_rgrsn that generates the Customer Life Time Value Prediction Model.
Take the following steps to use the procedures:
Refresh the Oracle Airlines Data Model mining source materialized views by executing the following SQL statements.
SELECT count(*) FROM dmv_cust_ltv_src; exec pkg_oadm_mining.refresh_mining_source; SELECT count(*)FROM dmv_cust_ltv_src;
These statements:
Displays the number of records in dmv_cust_ltv_src materialized view before materialized view refresh.
Refreshes mining source materialized views.
Displays the number of records in dmv_cust_ltv_src materialized view after materialized view refresh.
Generate the Customer Life Time Value Prediction Model by executing the following statements:
SELECT count(*) FROM dwd_cust_mnng; SELECT count(*) FROM dwd_cust_ltv_svm_factor; EXEC pkg_oadm_mining. create_cust_ltv_svm_rgrsn; SELECT count(*) FROM dwd_cust_mnng; SELECT count(*) FROM dwd_cust_ltv_svm_factor;
These statements:
Shows the records count in dwd_cust_mnng table before data mining model build.
Shows the records counts in the dwd_cust_ltv_svm_factor table before data mining model build.
Trains data mining model.
Shows the records count in the dwd_cust_mnng table after data mining model build.
Shows the records count in the dwd_cust_ltv_svm_factor table after data mining model build.
After refreshing the mining source materialized views and building the data mining model, check the mining prediction results in dwd_cust_mnng table as shown in the following steps:
Issue the following query.
SELECT frqtflr_card_key, ltv_value, ltv_band_cd FROM dwd_cust_mnng;
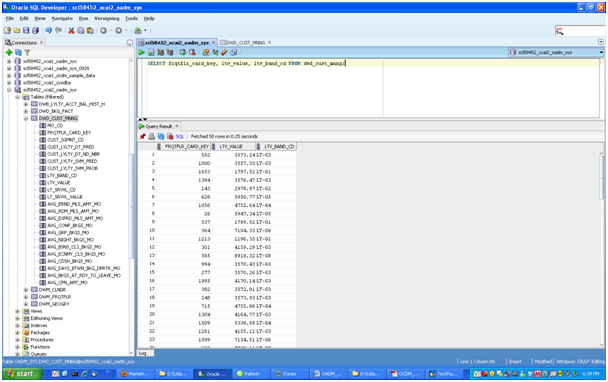
For each customer identified by frqtflr_card_key, the ltv_value column gives the prediction of customer life time value, a continuous value. The ltv_band_cd column is populated by binning the prediction value, ltv_value.
Aggregate tables are tables that aggregate or "roll up" the data to one level higher than a base or derived table. The aggregate tables in the default Oracle Airlines Data Model have a DWA_ prefix. These aggregate tables provide a view of the data similar to the view provided by a fact table in a snowflake schema while the dimensions of that fact table are DWM_ tables.
The default Oracle Airlines Data Model defines several aggregate tables. For example, the DWA_DLY_BKG_FACT table aggregates the values of the DWD_BKG_FACT table to the day, segment, and traffic category levels.
See:
The "Aggregate Tables" topic in Oracle Airlines Data Model Reference for a list of the aggregate tables in the default Oracle Airlines Data Model.If, during fit-gap analysis, you identified a need for aggregated data that is not provided by the default aggregate tables, you can define new materialized views. When designing these tables, keep the following points in mind:
Create a query for the materialized view that aggregates up only a single level. For example, if aggregating over time, then aggregate only from day to month.
Note:
When you must aggregate up many levels (for example in time, month, quarter, and year) or different hierarchies (for example, the fiscal and calendar hierarchies for a time dimension), do not define aDWA_ table; instead, define the aggregations by creating OLAP cubes.Name the tables following the conventions outlined in "General Naming Conventions for Physical Objects" and use an DWA_ prefix.
There is often much discussion regarding the 'best' modeling approach to take for any given data warehouse with each style, classic 3NF and dimensional having their own strengths and weaknesses. It is likely that data warehouses must do more to embrace the benefits of each model type rather than rely on just one - this is the approach that was adopted in designing the Oracle Airlines Data Model. The foundation layer of the Oracle Airlines Data Model is a 3NF model. The default Oracle Airlines Data Model also provides a dimensional model of the data. This dimensional model of the data is a perspective that summarizes and aggregates data, rather than preserving detailed transaction information.
Familiarize yourself with dimensional modeling by reading the following topics before you begin to customize the dimensional model of the default Oracle Airlines Data Model:
Characteristics of the OLAP Cubes in Oracle Airlines Data Model
Defining New Oracle OLAP Cubes for Oracle Airlines Data Model
Choosing a Cube Partitioning Strategy for Oracle Airlines Data Model
Choosing a Cube Data Maintenance Method for Oracle Airlines Data Model
The simplicity of a dimensional model is inherent because it defines objects that represent real-world business entities. Analysts know which business measures they are interested in examining, which dimensions and attributes make the data meaningful, and how the dimensions of their business are organized into levels and hierarchies.
In the simplest terms, a dimensional model identifies the following objects:
Measures. Measures store quantifiable business data (such as Booking or Partner Earning). Measures are sometimes called "facts". Measures are organized by one or more dimensions and may be stored or calculated at query time:
Stored Measures. Stored measures are loaded and stored at the leaf level. Commonly, there is also a percentage of summary data that is stored. Summary data that is not stored is dynamically aggregated when queried.
Calculated Measures. Calculated measures are measures whose values are calculated dynamically at query time. Only the calculation rules are stored in the database. Common calculations include measures such as ratios, differences, moving totals, and averages. Calculations do not require disk storage space, and they do not extend the processing time required for data maintenance.
Dimensions. A dimension is a structure that categorizes data to enable users to answer business questions. Commonly used dimensions are Account, Airport, and Flight, Geography, and Calendar. A dimension's structure is organized hierarchically based on parent-child relationships. These relationships enable:
Navigation between levels.
Hierarchies on dimensions enable drilling down to lower levels or navigation (rolling up) to higher levels. Drilling down on a Calendar Year dimension member 2005 typically navigates you to quarters Q1 2005 through Q4 2005. In a calendar year hierarchy, drilling down on Q1 2005 would navigate you to the months, January 05 through March 05. These kinds of relationships make it easy for users to navigate large volumes of multidimensional data.
Aggregation from child values to parent values.
The parent represents the aggregation of its children. Data values at lower levels aggregate into data values at higher levels. Dimensions are structured hierarchically so that data at different levels of aggregation are manipulated efficiently for analysis and display.
Allocation from parent values to child values.
The reverse of aggregation is allocation and is heavily used by planning budgeting, and similar applications. Here, the role of the hierarchy is to identify the children and descendants of particular dimension members of "top-down" allocation of budgets (among other uses).
Grouping of members for calculations.
Share and index calculations take advantage of hierarchical relationships (for example, the percentage of total ticket booking count contributed by each frequent flyer member level, or the percentage share of flown revenue for a certain segment, or sales revenue as a percentage of the geographical region for a sales agent location).
A dimension object helps to organize and group dimensional information into hierarchies. This represents natural 1:n relationships between columns or column groups (the levels of a hierarchy) that cannot be represented with constraint conditions. Going up a level in the hierarchy is called rolling up the data and going down a level in the hierarchy is called drilling down the data.
There are two ways that you can implement a dimensional model:
Relational tables in a star schema configuration. This traditional method of implementing a dimensional model is discussed in "Characteristics of Relational Star and Snowflake Tables".
Oracle OLAP Cubes. The physical model provided with Oracle Airlines Data Model provides a dimensional perspective of the data using Oracle OLAP cubes. This dimensional model is discussed in "Characteristics of the OLAP Dimensional Model".
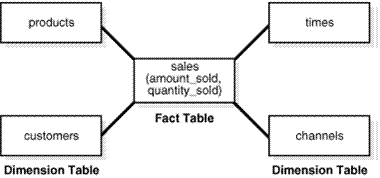
In the case of relational tables, the dimensional model has historically been implemented as a star or snowflake schema. Dimension tables (which contain information about hierarchies, levels, and attributes) join to one or more fact tables. Fact tables are the large tables that store quantifiable business measurements (such as Booking or Partner Earning) and typically have foreign keys to the dimension tables. Dimension tables, also known as lookup or reference tables. contain the relatively static or descriptive data in the data warehouse.
A star schema borders on a physical model, as drill paths, hierarchy and query profile are embedded in the data model itself rather than the data. This in part at least, is what makes navigation of the model so straightforward for end users. Star schemas usually have a large fact table surrounded by smaller dimension tables. Dimension tables do not change very much. Most of the information that the users need are in the fact tables. Therefore, star schemas have fewer table joins than do 3NF models.
A star schema is so called because the diagram resembles a star, with points radiating from a center. The center of the star consists of one or more fact tables and the points of the star are the dimension tables.
Snowflake schemas are slight variants of a simple star schema where the dimension tables are further normalized and broken down into multiple tables. The snowflake aspect only affects the dimensions and not the fact table and is therefore considered conceptually equivalent to star schemas. Snowflake dimensions are useful and indeed necessary when there are fact tables of differing granularity. A month-level derived or aggregate table (or materialized view) must be associated with a month level snowflake dimension table rather than the default (lower) Day level star dimension table.
When a relational table acts as a dimension to a fact table, it is recommended that you declare that table as a dimension (even though it is not necessary). Defined dimensions can yield significant performance benefits, and support the use of more complex types of rewrite.
To define and declare the structure of the dimension use the CREATE DIMENSION command. Use the LEVEL clause to identify the names of the dimension levels.
Note:
In the default Oracle Airlines Data Model, relational tables used as dimension tables are not defined using theCREATE DIMENSION command.To improve the data quality of the dimension data in the data warehouse, it is recommended that you validate the declarative information about the relationships between the dimension members after any modification to the dimension data.
To perform this validation, use the VALIDATE_DIMENSION procedure of the DBMS_DIMENSION package. When the VALIDATE_DIMENSION procedure encounters any errors, the procedure places the errors into the DIMENSION_EXCEPTIONS table. To find the exceptions identified by the VALIDATE_DIMENSION procedure, query the DIMENSION_EXCEPTIONS table.
You can schedule a call to the VALIDATE_DIMENSION procedure as a post-process step to the regular Incremental Dimension load script. This can be done before the call to refresh the derived or aggregate tables of the data model through materialized view refresh, intra-ETL package calls.
Note:
In the ETL delivered with the default Oracle Airlines Data Model, relational dimension tables are not validated.Oracle OLAP Cubes logically represent data similar to relational star tables, although the data is actually stored in multidimensional arrays. Like dimension tables, cube dimensions organize members into hierarchies, levels, and attributes. The cube stores the measure (fact) data. The dimensions form the edges of the cube.
Oracle OLAP is an OLAP server embedded in the Oracle Database. Oracle OLAP provides native multidimensional storage and speed-of-thought response times when analyzing data across multiple dimensions. The database provides rich support for analytics such as time series calculations, forecasting, advanced aggregation with additive and nonadditive operators, and allocation operations.
By integrating multidimensional objects and analytics into the database, Oracle provides the best of both worlds: the power of multidimensional analysis along with the reliability, availability, security, and scalability of the Oracle database.
Oracle OLAP is fully integrated into Oracle Database. At a technical level, this means:
The OLAP engine runs within the kernel of Oracle Database.
Dimensional objects are stored in Oracle Database in their native multidimensional format.
Cubes and other dimensional objects are first class data objects represented in the Oracle data dictionary.
Data security is administered in the standard way, by granting and revoking privileges to Oracle Database users and roles.
OLAP cubes, dimensions, and hierarchies are exposed to applications as relational views. Consequently, applications can query OLAP objects using SQL as described in "Oracle OLAP Cube Views" and Chapter 5, "Report and Query Customization."
Oracle OLAP cubes can be enhanced so that they are materialized views as described in "Cube Materialized Views".
See also:
Oracle OLAP User's Guide and"Characteristics of the OLAP Cubes in Oracle Airlines Data Model".The benefits to your organization are significant. Oracle OLAP offers the power of simplicity: One database, standard administration and security, standard interfaces and development tools.
The Oracle OLAP dimensional data model is highly structured. Structure implies rules that govern the relationships among the data and control how the data can be queried. Cubes are the physical implementation of the dimensional model, and thus are highly optimized for dimensional queries. The OLAP engine leverages this innate dimensionality in performing highly efficient cross-cube joins for inter-row calculations, outer joins for time series analysis, and indexing. Dimensions are pre-joined to the measures. The technology that underlies cubes is based on an indexed multidimensional array model, which provides direct cell access.
The OLAP engine manipulates dimensional objects in the same way that the SQL engine manipulates relational objects. However, because the OLAP engine is optimized to calculate analytic functions, and dimensional objects are optimized for analysis, analytic and row functions can be calculated much faster in OLAP than in SQL.
The dimensional model enables Oracle OLAP to support high-end business intelligence tools and applications such as OracleBI Discoverer Plus OLAP, OracleBI Spreadsheet Add-In, Oracle Business Intelligence Suite Enterprise Edition, BusinessObjects Enterprise, and Cognos ReportNet.
Oracle OLAP Dimensional Objects
Oracle OLAP dimensional objects include cubes, measures, dimensions, hierarchies, levels and attributes. The OLAP dimensional objects are described in detail in Oracle OLAP User's Guide. Figure 3-2 shows the general relationships among the objects.
Figure 3-2 Diagram of the OLAP Dimensional Model
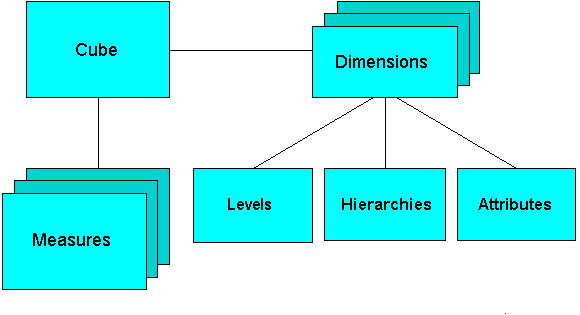
When you define an OLAP cube, Oracle OLAP automatically generates a set of relational views on the cube and its dimensions and hierarchies
Cube view. Each cube has a cube view that presents the data for all the measures and calculated measures in the cube. You can use a cube view like a fact table in a star or snowflake schema. However, the cube view contains all the summary data in addition to the detail level data. The default name of a cube view is cube_VIEW.
Dimension and hierarchy views. Each dimension has one dimension view plus a hierarchy view for each hierarchy associated with the dimension. The default name for a dimension view is dimension_VIEW. For a hierarchy view, the default name is dimension_hierarchy_VIEW.
These views are related in the same way as fact and dimension tables in a star schema. Cube views serve the same function as fact tables, and hierarchy views and dimension views serve the same function as dimension tables. Typical queries join a cube view with either a hierarchy view or a dimension view.
SQL applications query these views to display the information-rich contents of these objects to analysts and decision makers. You can also create custom views that follow the structure expected by your applications, using the system-generated views like base tables.
See also:
The discussion on querying dimensional objects in Oracle OLAP User's Guide and Chapter 5, "Report and Query Customization."Oracle OLAP cubes can be enhanced so that they are materialized views. A cube that has been enhanced in this way is called a cube materialized view and has a CB$ prefix. Cube materialized views can be incrementally refreshed through the Oracle Database materialized view subsystem, and they can serve as targets for transparent rewrite of queries against the source tables.
The OLAP dimensions associated with a cube materialized view are also defined with materialized view capabilities.
Necessary Cube Characteristics for Cube Materialized Views
A cube must conform to these requirements, before it can be designated as a cube materialized view:
All dimensions of the cube have at least one level and one level-based hierarchy. Ragged and skip-level hierarchies are not supported. The dimensions must be mapped.
All dimensions of the cube use the same aggregation operator, which is either SUM, MIN, or MAX.
The cube has one or more dimensions and one or more measures.
The cube is fully defined and mapped. For example, if the cube has five measures, then all five are mapped to the source tables.
The data type of the cube is NUMBER, VARCHAR2, NVARCHAR2, or DATE.
The source detail tables support dimension and rely constraints. If they have not been defined, then use the Relational Schema Advisor to generate a script that defines them on the detail tables.
The cube is compressed.
The cube can be enriched with calculated measures, but it cannot support more advanced analytics in a cube script.
Adding Materialized View Capabilities
To add materialized view capabilities to an OLAP cube, take the following steps:
In the Analytic Workspace Manager, connect to the oadm_sys schema.
From the cube list, select the cube which you want to enable.
In the right pane, select the Materialized Views tab.
Select Enable Materialized View Refresh of the Cube. then click Apply.
Note:
You cannot enable the cube materialized view for a forecast cube.Oracle by Example:
For more information on working with OLAP cubes, see the following OBE tutorials:"Querying OLAP 11g Cubes"
"Using Oracle OLAP 11g With Oracle BI Enterprise Edition"
To access the tutorials, open the Oracle Learning Library in your browser by following the instructions in "Oracle Technology Network"; and, then, search for the tutorials by name.
See also:
Oracle OLAP User's GuideThe default access layer of Oracle Airlines Data Model provides a dimensional perspective of the data using Oracle OLAP cubes.
There are OLAP cubes defined in the default oadm_sys schema. These cubes have the general characteristics described in "Characteristics of the OLAP Dimensional Model". Specifically, OLAP cubes in the Oracle Airlines Data Model have the following characteristics:
All of the default OLAP cubes are loaded with data from DWA_ tables.
The cubes were defined and built using the Analytical Workspace Manager (AWM) client tool.
A relational view (with a _VIEW suffix) is defined over each of the OLAP cubes.
All of the OLAP cubes in the Oracle Airlines Data Model are are ready to be enabled as cube materialized views (that is, CB$ objects).
Tip:
Immediately after installation, all materialized views underlying the OLAP cubes are disabled by default. To enable the cube materialized views, you must follow the steps outlined in "Adding Materialized View Capabilities".For information on the using OLAP cubes in your customized version of Oracle Airlines Data Model, see Oracle OLAP User's Guide and the following topics:
You can add new OLAP cubes to the oadm_sys schema. For consistency's sake, design and define these new cubes as described in "Characteristics of the OLAP Cubes in Oracle Airlines Data Model".
Take the following steps to define new cubes:
Ensure that there is an aggregate table (DWA_) to use as the "lowest leaf" data for the cube. See "Aggregate Tables in the Oracle Airlines Data Model" for information on creating new tables.
Use the AWM to define new Cubes for a customized version of Oracle Airlines Data Model. Follow the instructions given for creating cubes and dimensions in Oracle OLAP User's Guide.
Use the information provided in "Characteristics of the OLAP Dimensional Model". and the Oracle OLAP User's Guide to guide you when you design and define new OLAP cubes. Also, if you are familiar with a relational star schema design as outlined in "Characteristics of Relational Star and Snowflake Tables", then you can use this understanding to help you design an OLAP Cube as described below:
Fact tables correspond to cubes.
Data columns in the fact tables correspond to measures.
Foreign key constraints in the fact tables identify the dimension tables.
Dimension tables identify the dimensions.
Primary keys in the dimension tables identify the base-level dimension members.
Parent columns in the dimension tables identify the higher level dimension members.
Columns in the dimension tables containing descriptions and characteristics of the dimension members identify the attributes.
You can also get insights into the dimensional model by looking at the sample reports included with Oracle Airlines Data Model.
See:
Oracle Airlines Data Model Installation Guide for more information on installing the sample reports and deploying the Oracle Airlines Data Model RPD and webcat on the Business Intelligence Suite Enterprise Edition instance.Tip:
While investigating your source data, you may decide to create relational views that more closely match the dimensional model that you plan to create.Add materialized view capabilities to the OLAP cubes as described in "Adding Materialized View Capabilities".
See also:
Oracle OLAP User's Guide, "Defining New Oracle OLAP Cubes for Oracle Airlines Data Model", and the sample reports in Oracle Airlines Data Model Reference.Oracle by Example:
For more information on creating OLAP cubes, see the "Building OLAP 11g Cubes" OBE tutorial.To access the tutorial, open the Oracle Learning Library in your browser by following the instructions in "Oracle Technology Network"; and, then, search for the tutorial by name.
Common customizations to Oracle Airlines Data Model cubes are changing the dimensions or the measures of the cube.
Since all Oracle Airlines Data Model cubes load data from tables with the DWA_ prefix, to change the measures or dimensions of one cube, you must take the following steps:
Use the information in Oracle Airlines Data Model Reference, to identify the DWA_ table from which the OLAP cube is populated.
Change the structure of the DWA_ table identified in Step 1.
Change the OLAP cube and cube materialized views to reflect the new structure.
To create a forecast cube for Oracle Airlines Data Model:
Create a cube to contain the results of the forecast as described in "Defining New Oracle OLAP Cubes for Oracle Airlines Data Model".
Note:
You cannot enable materialized views for an Oracle Airlines Data Model forecast cube.Write an OLAP DML forecasting context program as described in Oracle OLAP DML Reference.
Partitioning is a method of physically storing the contents of a cube. It improves the performance of large cubes in the following ways:
Improves scalability by keeping data structures small. Each partition functions like a smaller measure.
Keeps the working set of data smaller both for queries and maintenance, since the relevant data is stored together.
Enables parallel aggregation during data maintenance. Each partition can be aggregated by a separate process.
Simplifies removal of old data from storage. Old partitions can be dropped, and new partitions can be added.
The number of partitions affects the database resources that can be allocated to loading and aggregating the data in a cube. Partitions can be aggregated simultaneously when sufficient resources have been allocated.
The Cube Partitioning Advisor analyzes the source tables and develops a partitioning strategy. You can accept the recommendations of the Cube Partitioning Advisor, or you can make your own decisions about partitioning.
If your partitioning strategy is driven primarily by life-cycle management considerations, then you should partition the cube on the Time dimension. Old time periods can then be dropped as a unit, and new time periods added as a new partition. The Cube Partitioning Advisor has a Time option, which recommends a hierarchy and a level in the Time dimension for partitioning.
The level on which to partition a cube is determined based on a trade off between load performance and query performance.
Typically, you do not want to partition on too low a level (for example, on the DAY level of a TIME dimension) because if you do then too many partitions must be defined at load time which slows down an initial or historical load. Also, a large number of partitions can result in unusually long Analytic Workspace attach times and slows down the Time Series-based calculations. Also, a Quarterly Cumulative measure (Quarter to Date Measure) needs to access 90 or 91 partitions to calculate a specific value for one Customer and Organization. All dimension members above the partition level of partition dimension (including those belonging to nondefault hierarchies) would be present in a single default template. Day level partitioning makes this very heavy since all higher level members are stored in default template. However, the advantage of partitioning DAY if the OLAP Cube load frequency is daily then there you must only load from a new partition in fact table into a single partition in the OLAP cube every day. This greatly improves the load performance since percentage-based refresh can be enabled if the cube is materialized-view enabled and has materialized-view logs.
Recommendations: Cube Partitioning Strategy
Usually a good compromise between the differing load and query performance requirements is to use an intermediate level like MONTH as the partition level. Time series calculations within a month (week to date, month to date, and so on) are fast and higher level calculation like year to date needs to refer to 12 partitions at most. Also this way the monthly partition is defined and created only one time (that is during the initial load on first of each month) and is then reused for each subsequent load that month. The aggregation process may be triggered off at the month level (instead of specific day level) and some redundant aggregations (of previously loaded dates of current month) may occur each time but it should result in satisfactory load and query performance.
See also:
"The discussion on choosing a partition strategy in Oracle OLAP User's Guide, "Indexes and Partitioned Indexes in Oracle Airlines Data Model", and "Partitioning and Materialized Views".While developing a dimensional model of your data, it is a good idea to map and load each object immediately after you create it so that you can immediately detect and correct any errors that you made to the object definition or the mapping.
However, in a production environment, you want to perform routine maintenance as quickly and easily as possible. For this stage, you can choose among data maintenance methods. You can refresh all cubes using the Maintenance Wizard. This wizard enables you to refresh a cube immediately, or submit the refresh as a job to the Oracle job queue, or generate a PL/SQL script. You can run the script manually or using a scheduling utility, such as Oracle Enterprise Manager Scheduler or the DBMS_SCHEDULER PL/SQL package. The generated script calls the BUILD procedure of the DBMS_CUBE PL/SQL package. You can modify this script or develop one from the start using this package.
The data for a partitioned cube is loaded and aggregated in parallel when multiple processes have been allocated to the build. You are able to see this in the build log.
In addition, each cube can support these data maintenance methods:
Custom cube scripts
Cube materialized views
If you are defining cubes to replace existing materialized views, then you use the materialized views as an integral part of data maintenance. Note, however, that materialized view capabilities restrict the types of analytics that can be performed by a custom cube script.
Oracle by Example:
See the following OBE tutorial for an example of how Oracle uses cube materialized views for transparent access to a relational star schema.:"Querying OLAP 11g Cubes"
To access the tutorial, open the Oracle Learning Library in your browser by following the instructions in "Oracle Technology Network"; and, then, search for the tutorial by name.
Materialized views are query results that have been stored or "materialized" in advance as schema objects. From a physical design point of view, materialized views resemble tables or partitioned tables and behave like indexes in that they are used transparently and improve performance.
In the past, organizations using summaries spent a significant amount of time and effort creating summaries manually, identifying which summaries to create, indexing the summaries, updating them, and advising their users on which ones to use. With the advent of materialized views, a database administrator creates one or more materialized views, which are the equivalent of a summary. Thus, the workload of the database administrator is eased and the user no longer needed to be aware of the summaries that had been defined. Instead, the end user queries the tables and views at the detail data level. The query rewrite mechanism in the Oracle server automatically rewrites the SQL query to use the summary tables and reduces response time for returning results from the query.
Materialized views improve query performance by precalculating expensive join and aggregation operations on the database before executing and storing the results in the database. The query optimizer automatically recognizes when an existing materialized view can and should be used to satisfy a request.
The default Oracle Airlines Data Model defines materialized views. In the default oadm_sys schema, you can identify these materialized views by looking at objects with the prefixes listed in the following table.
| Prefix | Description |
|---|---|
CB$ |
An OLAP cube enhanced with materialized view capabilities.
See: OLAP cube materialized views in Oracle Airlines Data Model Reference for a list of these objects in the default data model. "Characteristics of the OLAP Cubes in Oracle Airlines Data Model" for information on OLAP cubes. Note: Do |
DMV_ |
Data mining source materialized views.
See: Oracle Airlines Data Model Reference to identify these objects in the default data model. |
The following topics provide more information on using and creating materialized views in your customized Oracle Airlines Data Model:
Refresh option vary by the type of materialized view:
See:
Oracle OLAP User's Guide for a discussion of creating materialized views of Oracle OLAP cubes.In data warehouses, materialized views normally contain aggregates. The _DWA tables in the default Oracle Airlines Data Model are this type of materialized view.
For a materialized view with aggregates, for fast refresh to be possible:
The SELECT list must contain all of the GROUP BY columns (if present)
There must be a COUNT(*) and a COUNT(column) on any aggregated columns.
Materialized view logs must be present on all tables referenced in the query that defines the materialized view. The valid aggregate functions are: SUM, COUNT(x), COUNT(*), AVG, VARIANCE, STDDEV, MIN, and MAX, and the expression to be aggregated can be any SQL value expression.
Fast refresh for a materialized view containing joins and aggregates is possible after any type of DML to the base tables (direct load or conventional INSERT, UPDATE, or DELETE).
You can define that the materialized view be refreshed ON COMMIT or ON DEMAND. A REFRESH ON COMMIT materialized view is automatically refreshed when a transaction that does DML to a materialized view's detail tables commits.
When you specify REFRESH ON COMMIT, the table commit can take more time than if you have not. This is because the refresh operation is performed as part of the commit process. Therefore, this method may not be suitable if many users are concurrently changing the tables upon which the materialized view is based.
Some materialized views contain only joins and no aggregates (for example, when a materialized view is created that joins the sales table to the times and customers tables). The advantage of creating this type of materialized view is that expensive joins are precalculated.
Fast refresh for a materialized view containing only joins is possible after any type of DML to the base tables (direct-path or conventional INSERT, UPDATE, or DELETE).
A materialized view containing only joins can be defined to be refreshed ON COMMIT or ON DEMAND. If it is ON COMMIT, the refresh is performed at commit time of the transaction that does DML on the materialized view's detail table.
If you specify REFRESH FAST, Oracle performs further verification of the query definition to ensure that fast refresh can be performed if any of the detail tables change. These additional checks are:
A materialized view log must be present for each detail table unless the table supports partition change tracking. Also, when a materialized view log is required, the ROWID column must be present in each materialized view log.
The rowids of all the detail tables must appear in the SELECT list of the materialized view query definition.
If some of these restrictions are not met, you can create the materialized view as REFRESH FORCE to take advantage of fast refresh when it is possible. If one table does not meet all of the criteria, but the other tables do the materialized view is still fast refreshable with respect to the other tables for which all the criteria are met.
To achieve an optimally efficient refresh:
Ensure that the defining query does not use an outer join that behaves like an inner join. If the defining query contains such a join, consider rewriting the defining query to contain an inner join.
If the materialized view contains only joins, the ROWID columns for each table (and each instance of a table that occurs multiple times in the FROM list) must be present in the SELECT list of the materialized view.
If the materialized view has remote tables in the FROM clause, all tables in the FROM clause must be located on that same site. Further, ON COMMIT refresh is not supported for materialized view with remote tables. Except for SCN-based materialized view logs, materialized view logs must be present on the remote site for each detail table of the materialized view and ROWID columns must be present in the SELECT list of the materialized view.
A nested materialized view is a materialized view whose definition is based on another materialized view. A nested materialized view can reference other relations in the database in addition to referencing materialized views.
In a data warehouse, you typically create many aggregate views on a single join (for example, rollups along different dimensions). Incrementally maintaining these distinct materialized aggregate views can take a long time, because the underlying join has to be performed many times.
Using nested materialized views, you can create multiple single-table materialized views based on a joins-only materialized view and the join is performed just one time. In addition, optimizations can be performed for this class of single-table aggregate materialized view and thus refresh is very efficient.
Some types of nested materialized views cannot be fast refreshed. Use EXPLAIN_MVIEW to identify those types of materialized views.
You can refresh a tree of nested materialized views in the appropriate dependency order by specifying the nested =TRUE parameter with the DBMS_MVIEW.REFRESH parameter.
The two most common operations on a materialized view are query execution and fast refresh, and each operation has different performance requirements:
Query execution might need to access any subset of the materialized view key columns, and might need to join and aggregate over a subset of those columns. Consequently, for best performance, create a single-column bitmap index on each materialized view key column.
In the case of materialized views containing only joins using fast refresh, create indexes on the columns that contain the rowids to improve the performance of the refresh operation.
If a materialized view using aggregates is fast refreshable, then an index appropriate for the fast refresh procedure is created unless USING NO INDEX is specified in the CREATE MATERIALIZED VIEW statement.
Because of the large volume of data held in a data warehouse, partitioning is an extremely useful option when designing a database. Partitioning the fact tables improves scalability, simplifies system administration, and makes it possible to define local indexes that can be efficiently rebuilt. Partitioning the fact tables also improves the opportunity of fast refreshing the materialized view because this may enable partition change tracking refresh on the materialized view.
Partitioning a materialized view has the same benefits as partitioning fact tables. When a materialized view is partitioned a refresh procedure can use parallel DML in more scenarios and partition change tracking-based refresh can use truncate partition to efficiently maintain the materialized view.
See also:
Oracle Database VLDB and Partitioning Guide, "Partitioned Tables in the Oracle Airlines Data Model", "Indexes and Partitioned Indexes in Oracle Airlines Data Model", and "Choosing a Cube Partitioning Strategy for Oracle Airlines Data Model"Using Partition Change Tracking
It is possible and advantageous to track freshness to a finer grain than the entire materialized view. The ability to identify which rows in a materialized view are affected by a certain detail table partition, is known as partition change tracking. When one or more of the detail tables are partitioned, it may be possible to identify the specific rows in the materialized view that correspond to a modified detail partition(s). those rows become stale when a partition is modified while all other rows remain fresh.
You can use partition change tracking to identify which materialized view rows correspond to a particular partition. Partition change tracking is also used to support fast refresh after partition maintenance operations on detail tables. For instance, if a detail table partition is truncated or dropped, the affected rows in the materialized view are identified and deleted. Identifying which materialized view rows are fresh or stale, rather than considering the entire materialized view as stale, allows query rewrite to use those rows that refresh while in QUERY_REWRITE_INTEGRITY = ENFORCED or TRUSTED modes.
Several views, such as DBA_MVIEW_DETAIL_PARTITION, detail which partitions are stale or fresh. Oracle does not rewrite against partial stale materialized views if partition change tracking on the changed table is enabled by the presence of join dependent expression in the materialized view.
To support partition change tracking, a materialized view must satisfy the following requirements:
At least one detail table referenced by the materialized view must be partitioned.
Partitioned tables must use either range, list or composite partitioning.
The top level partition key must consist of only a single column.
The materialized view must contain either the partition key column or a partition marker or ROWID or join dependent expression of the detail table.
If you use a GROUP BY clause, the partition key column or the partition marker or ROWID or join dependent expression must be present in the GROUP BY clause.
If you use an analytic window function or the MODEL clause, the partition key column or the partition marker or ROWID or join dependent expression must be present in their respective PARTITION BY subclauses.
Data modifications can only occur on the partitioned table. If partition change tracking refresh is being done for a table which has join dependent expression in the materialized view, then data modifications should not have occurred in any of the join dependent tables.
The COMPATIBILITY initialization parameter must be a minimum of 9.0.0.0.0.
Partition change tracking is not supported for a materialized view that refers to views, remote tables, or outer joins.
Using data compression for a materialized view brings you a additional dramatic performance improvement.
Consider data compression when using highly redundant data, such as tables with many foreign keys. In particular, likely candidates are materialized views created with the ROLLUP clause.
|
Copyright © 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|