| Oracle® Data Mining Concepts 11g Release 2 (11.2) Part Number E16808-06 |
|
|
PDF · Mobi · ePub |
| Oracle® Data Mining Concepts 11g Release 2 (11.2) Part Number E16808-06 |
|
|
PDF · Mobi · ePub |
This chapter describes regression, the supervised mining function for predicting a continuous, numerical target.
See Also:
"Supervised Data Mining"This chapter includes the following topics:
Regression is a data mining function that predicts numeric values along a continuum. Profit, sales, mortgage rates, house values, square footage, temperature, or distance could all be predicted using regression techniques. For example, a regression model could be used to predict the value of a house based on location, number of rooms, lot size, and other factors.
A regression task begins with a data set in which the target values are known. For example, a regression model that predicts house values could be developed based on observed data for many houses over a period of time. In addition to the value, the data might track the age of the house, square footage, number of rooms, taxes, school district, proximity to shopping centers, and so on. House value would be the target, the other attributes would be the predictors, and the data for each house would constitute a case.
In the model build (training) process, a regression algorithm estimates the value of the target as a function of the predictors for each case in the build data. These relationships between predictors and target are summarized in a model, which can then be applied to a different data set in which the target values are unknown.
Regression models are tested by computing various statistics that measure the difference between the predicted values and the expected values. The historical data for a regression project is typically divided into two data sets: one for building the model, the other for testing the model. See "Testing a Regression Model".
Regression modeling has many applications in trend analysis, business planning, marketing, financial forecasting, time series prediction, biomedical and drug response modeling, and environmental modeling.
You do not need to understand the mathematics used in regression analysis to develop and use quality regression models for data mining. However, it is helpful to understand a few basic concepts.
Regression analysis seeks to determine the values of parameters for a function that cause the function to best fit a set of data observations that you provide. The following equation expresses these relationships in symbols. It shows that regression is the process of estimating the value of a continuous target (y) as a function (F) of one or more predictors (x1 , x2 , ..., xn), a set of parameters (θ1 , θ2 , ..., θn), and a measure of error (e).
y = F(x,θ) + e
The predictors can be understood as independent variables and the target as a dependent variable. The error, also called the residual, is the difference between the expected and predicted value of the dependent variable. The regression parameters are also known as regression coefficients. (See "Regression Coefficients".)
The process of training a regression model involves finding the parameter values that minimize a measure of the error, for example, the sum of squared errors.
There are different families of regression functions and different ways of measuring the error.
A linear regression technique can be used if the relationship between the predictors and the target can be approximated with a straight line.
Regression with a single predictor is the easiest to visualize. Simple linear regression with a single predictor is shown in Figure 4-1.
Figure 4-1 Linear Regression With a Single Predictor
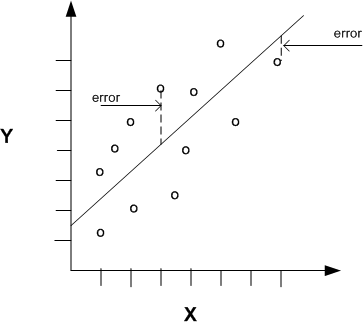
Linear regression with a single predictor can be expressed with the following equation.
y = θ2x + θ1 + e
The regression parameters in simple linear regression are:
The slope of the line (θ2) — the angle between a data point and the regression line
The y intercept (θ1) — the point where x crosses the y axis (x = 0)
The term multivariate linear regression refers to linear regression with two or more predictors (x1, x2, …, xn). When multiple predictors are used, the regression line cannot be visualized in two-dimensional space. However, the line can be computed simply by expanding the equation for single-predictor linear regression to include the parameters for each of the predictors.
y = θ1 + θ2x1 + θ3x2 + ..... θn xn-1 + e
In multivariate linear regression, the regression parameters are often referred to as coefficients. When you build a multivariate linear regression model, the algorithm computes a coefficient for each of the predictors used by the model. The coefficient is a measure of the impact of the predictor x on the target y. Numerous statistics are available for analyzing the regression coefficients to evaluate how well the regression line fits the data. ("Regression Statistics".)
Often the relationship between x and y cannot be approximated with a straight line. In this case, a nonlinear regression technique may be used. Alternatively, the data could be preprocessed to make the relationship linear.
Nonlinear regression models define y as a function of x using an equation that is more complicated than the linear regression equation. In Figure 4-2, x and y have a nonlinear relationship.
Figure 4-2 Nonlinear Regression With a SIngle Predictor
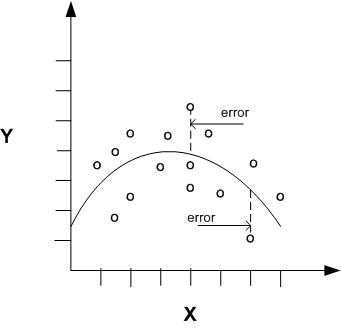
The term multivariate nonlinear regression refers to nonlinear regression with two or more predictors (x1, x2, …, xn). When multiple predictors are used, the nonlinear relationship cannot be visualized in two-dimensional space.
A regression model predicts a numeric target value for each case in the scoring data. In addition to the predictions, some regression algorithms can identify confidence bounds, which are the upper and lower boundaries of an interval in which the predicted value is likely to lie.
When a model is built to make predictions with a given confidence, the confidence interval will be produced along with the predictions. For example, a model might predict the value of a house to be $500,000 with a 95% confidence that the value will be between $475,000 and $525,000.
A regression model is tested by applying it to test data with known target values and comparing the predicted values with the known values.
The test data must be compatible with the data used to build the model and must be prepared in the same way that the build data was prepared. Typically the build data and test data come from the same historical data set. A percentage of the records is used to build the model; the remaining records are used to test the model.
Test metrics are used to assess how accurately the model predicts these known values. If the model performs well and meets the business requirements, it can then be applied to new data to predict the future.
The Root Mean Squared Error and the Mean Absolute Error are commonly used statistics for evaluating the overall quality of a regression model. Different statistics may also be available depending on the regression methods used by the algorithm.
The Root Mean Squared Error (RMSE) is the square root of the average squared distance of a data point from the fitted line.
This SQL expression calculates the RMSE.
SQRT(AVG((predicted_value - actual_value) * (predicted_value - actual_value)))
This formula shows the RMSE in mathematical symbols. The large sigma character represents summation; j represents the current predictor, and n represents the number of predictors.

The Mean Absolute Error (MAE) is the average of the absolute value of the residuals (error). The MAE is very similar to the RMSE but is less sensitive to large errors.
This SQL expression calculates the MAE.
AVG(ABS(predicted_value - actual_value))
This formula shows the MAE in mathematical symbols. The large sigma character represents summation; j represents the current predictor, and n represents the number of predictors.
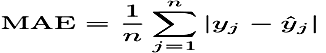
Oracle Data Mining supports two algorithms for regression. Both algorithms are particularly suited for mining data sets that have very high dimensionality (many attributes), including transactional and unstructured data.
Generalized Linear Models (GLM)
GLM is a popular statistical technique for linear modeling. Oracle Data Mining implements GLM for regression and for binary classification.
GLM provides extensive coefficient statistics and model statistics, as well as row diagnostics. GLM also supports confidence bounds.
Support Vector Machines (SVM)
SVM is a powerful, state-of-the-art algorithm for linear and nonlinear regression. Oracle Data Mining implements SVM for regression and other mining functions.
SVM regression supports two kernels: the Gaussian kernel for nonlinear regression, and the linear kernel for linear regression. SVM also supports active learning.
|
Copyright © 2005, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|